Text approximately duplicated detection method based on semantic analysis and multiple Simhash
A technique of approximate repetition and semantic analysis, which is applied in the field of text approximate repetition detection based on semantic analysis and multiple Simhash, which can solve the problems of general repetition problem and achieve excellent effect.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

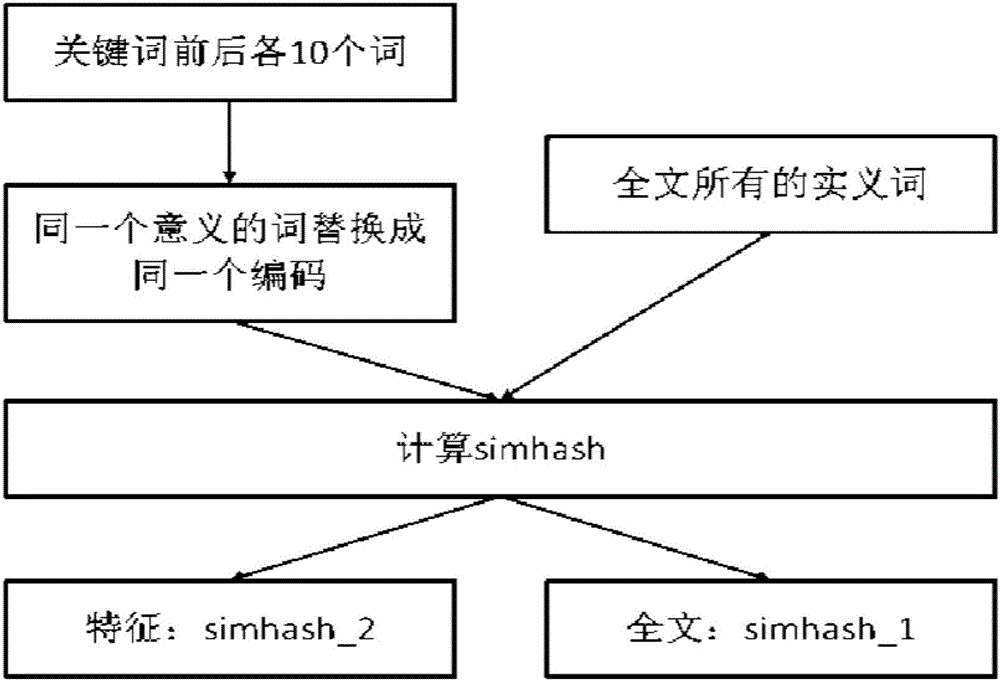
Examples
Embodiment
[0047] In this embodiment, 2162 IT news articles are used as the original text, and the specific implementation methods are as follows:
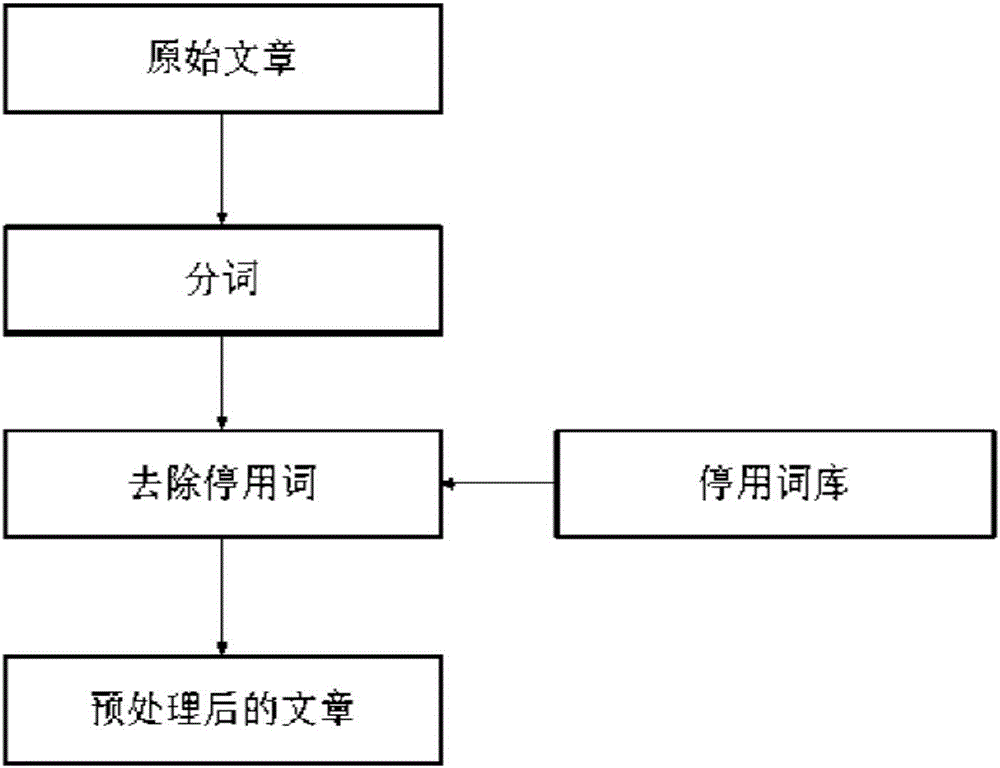
[0048] (1) Preprocessing Chinese articles: such as figure 1 As shown, the original text is segmented and stop words are removed, and the remaining words are content words.
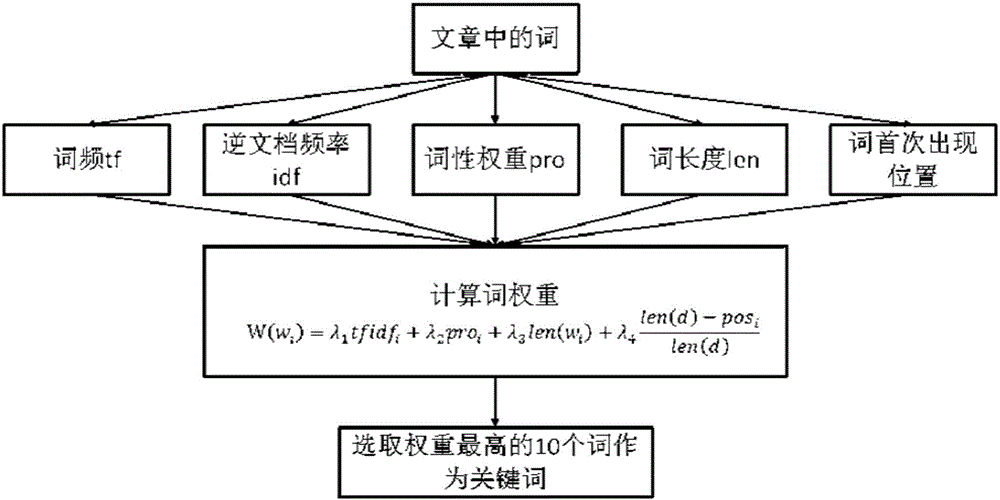
[0049] (2) Select keywords: such as figure 2 As shown in , the weight of each substantive word is calculated based on tfidf, part of speech, word length, and the position where the word first appears, and the 10 words with the highest weight are selected as keywords. The weight of a word is calculated by the following formula:
[0050]
[0051] The parameters are selected as follows:
[0052] if w i is a noun, then pro i Take 0.6, if w i is an adjective, then pro i Take 0.4, if w i is a verb, then pro i Take 0.3, if w i is a word of other parts of speech, then pro i Take 0.1;
[0053] tfidf weights λ 1 Take 0.8;
[0054] Part of Speech Weight λ 2 Take ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com