

Robot learning control method based on policy gradient
A technology of learning control and robotics, applied in the direction of program control manipulators, manipulators, manufacturing tools, etc., can solve problems such as discontinuous algorithm convergence, dimension disaster, and inability to be directly applied, so as to improve learning ability and intelligence, and shorten learning time , The effect of simplifying the design difficulty
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
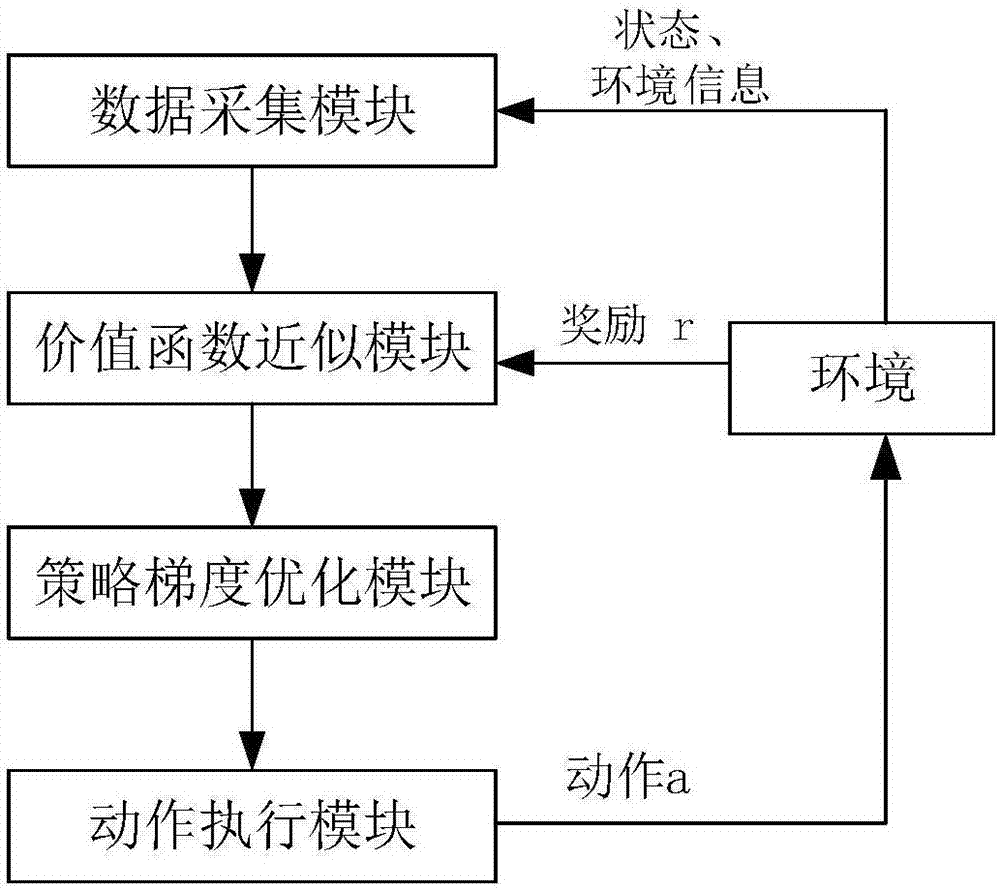
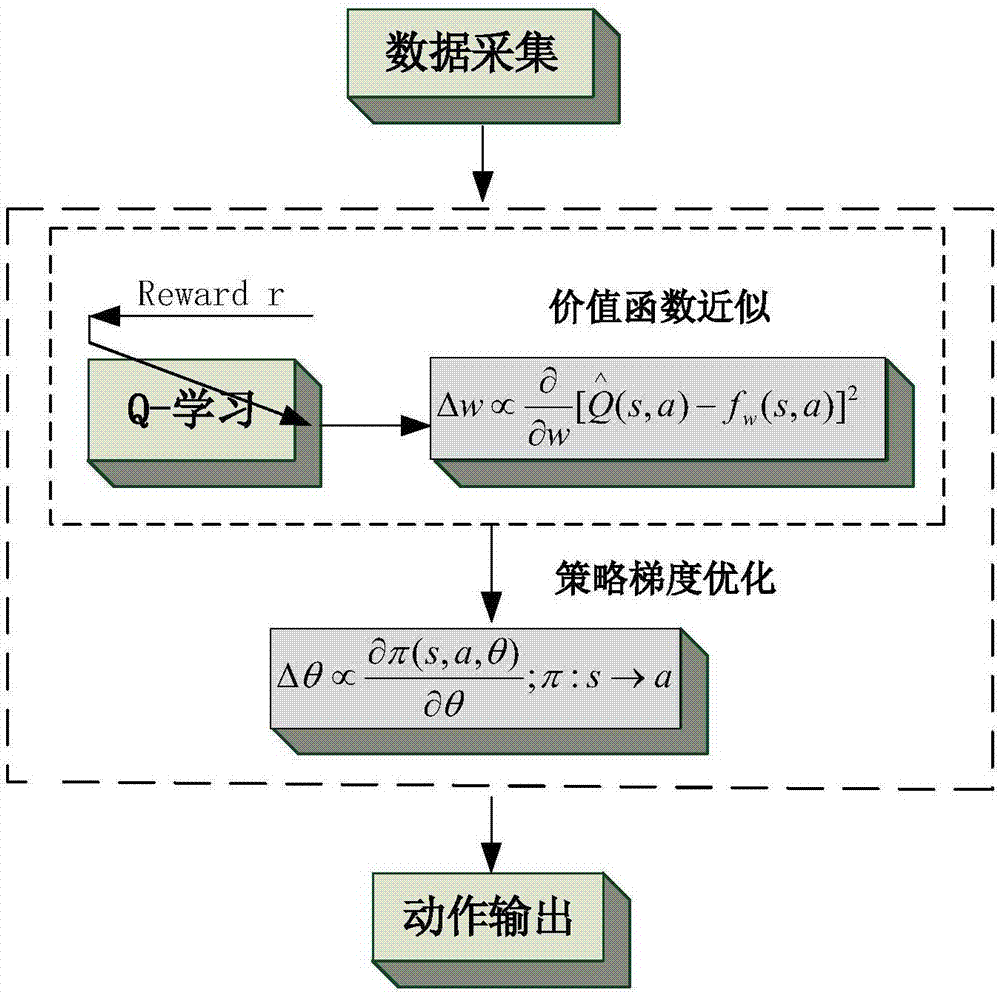
[0020] The method described in the present invention will be further described in detail below in conjunction with the accompanying drawings. figure 1 The structural block diagram of the robot learning control method based on the policy gradient provided by the present invention; figure 2 The schematic diagram of the robot learning control method based on the strategy gradient provided by the present invention is shown in the figure: the robot learning control method based on the strategy gradient provided by the present invention includes the following steps:
[0021] S1: Input the status information data of the robot during the movement process and the perception information data of the interaction with the environment;
[0022] S2: According to the state information data obtained by the robot and the environmental perception information data, calculate the approximate estimation model of the timely reward and the value function;
[0023] S3: According to the obtained cumu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More