

Video attribute representation learning method and method for automatically generating video text description
A technology of text description and learning method, applied in the field of computer vision, to achieve the effect of efficient extraction
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0032] The embodiments of the present invention are described in detail below. This embodiment is implemented on the premise of the technical solution of the present invention, and detailed implementation methods and specific operating procedures are provided, but the protection scope of the present invention is not limited to the following implementation example.
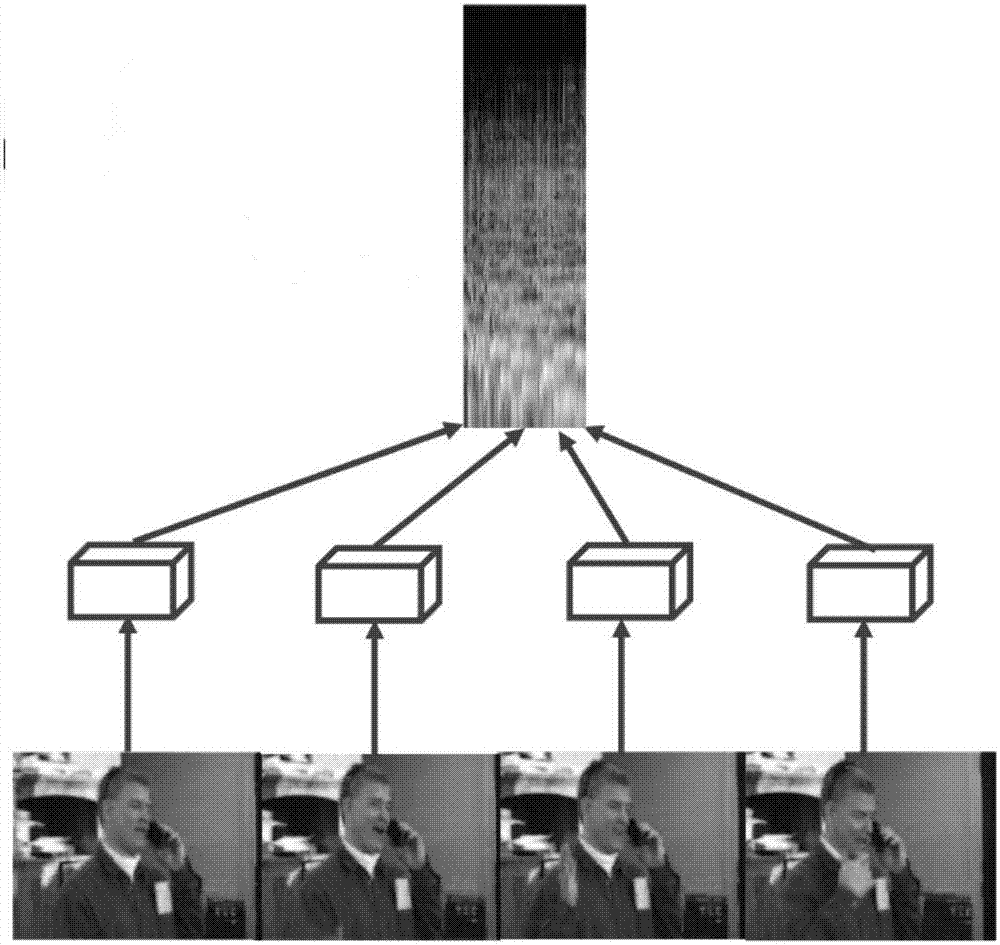
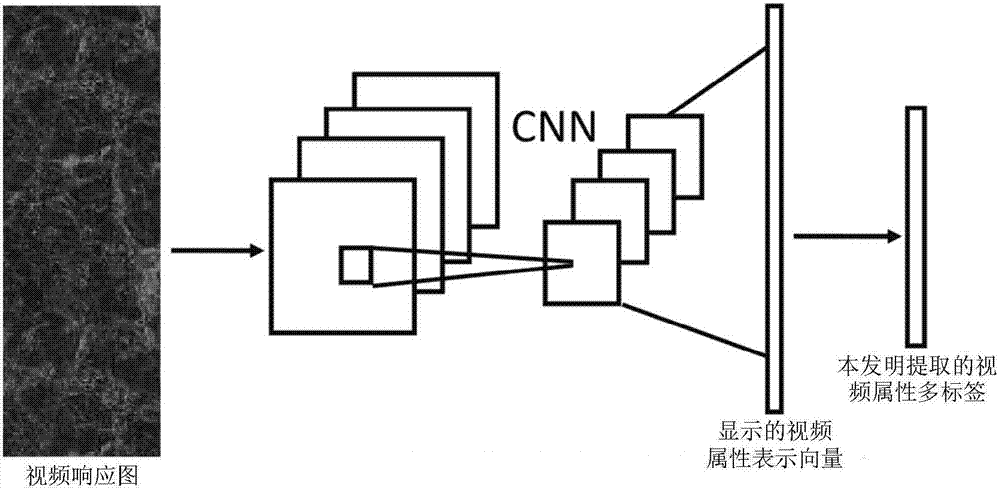
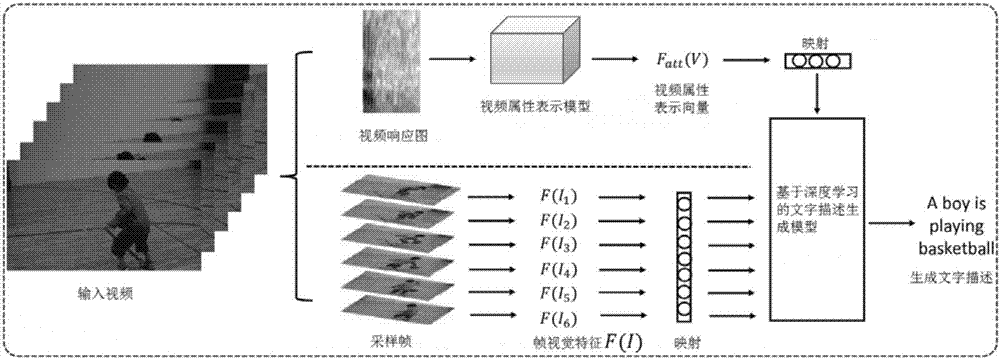
[0033] A video attribute representation learning method for extracting video semantic information that can be used for automatic generation of video text descriptions, comprising the following steps:
[0034] Step 1) collect a batch of data for the training and testing of the video text automatic description algorithm, and the data requires each video to correspond to several corresponding text descriptions;
[0035] Step 2) The present invention defines all nouns, verbs, and adjectives that appear in the text description content in the training set as the attribute labeling information of the corresponding...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More