

Method for semantic query of large-scale knowledge graph based on spark
A technology of knowledge graph and semantic query, applied in the field of computer storage query, can solve the problems of inability to meet the real-time requirements of large-scale semantic data query, insufficient computing performance and scalability, large storage space, etc., to reduce iterative connections, reduce The amount of production and the effect of ensuring high efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0043] In order to describe the present invention more specifically, the technical solution of the present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
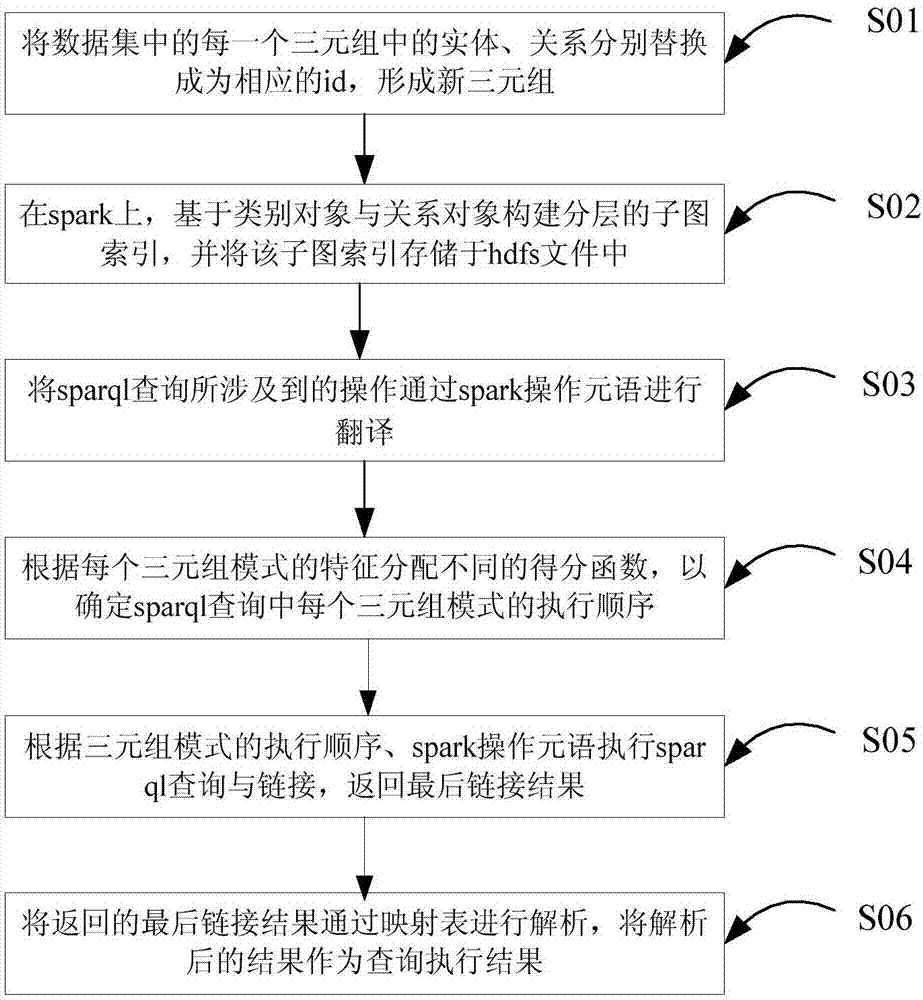
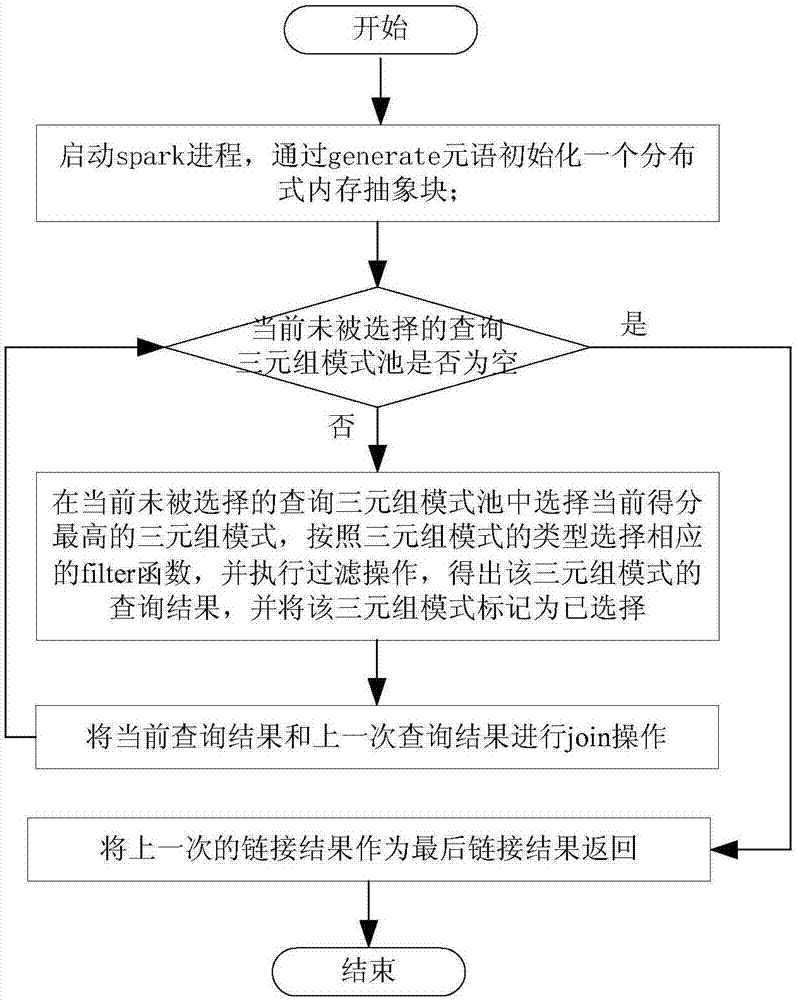
[0044] Such as figure 1 As shown, the present embodiment includes the following based on spark-based large-scale knowledge map semantic query method:
[0045] S01, replace the entity and relationship in each triple in the data set with the corresponding id to form a new triple.
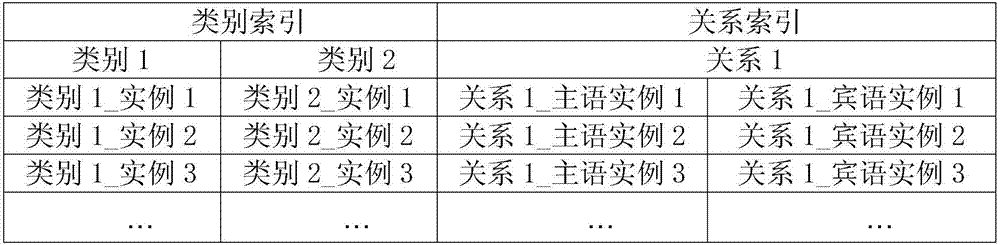
[0046] This step is specifically as follows: query benchmark LUBM through standard RDF storage to generate large-scale semantic data; then, deploy a preprocessor, assign unique ids to all entities and relationships, and build corresponding mapping tables; finally, according to the mapping table , replace the entity and relationship in each triple in the traversal dataset with the corresponding id to get a new triple; this step can not only greatly reduce the amount of distributed...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More