

Dynamic streaming data clustering method
A technology of streaming data and clustering method, applied in the field of clustering, can solve the problems of poor clustering effect and inability to better reflect the classification characteristics of data, and achieve the effect of ideal clustering effect and high clustering quality.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
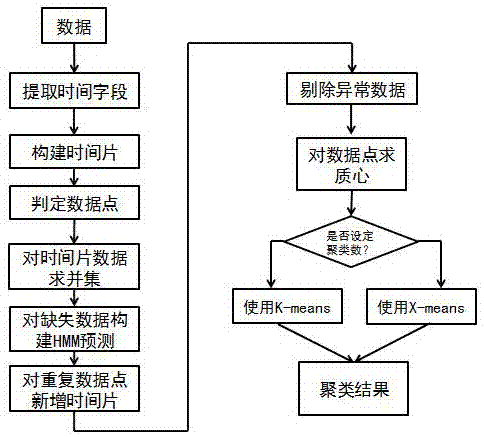
[0037] like figure 1 , a clustering method for dynamic streaming data, which includes the following steps:
[0038] S1: Extract the time field, convert the data into time field data, and extract the time field separately;
[0039] S2: Construct a time slice, and construct a time slice after sorting the time field;
[0040] S3: Determine data points, locate and identify each data;
[0041] S4: time slice, data union, and mark the time slice without corresponding data;
[0042] S5: Build a training model and build HMM predictions for missing data;
[0043] S6: Check the validity of the data, and add time slices for repeated data points;
[0044] S7: Eliminate abnormal data, and check whether there is abnormal data fluctuation according to all time slices;
[0045] S8: Centroid data clustering.
[0046] The data in the data to be analyzed described in step S1 should be structured data, and the data fields and structure should be clear and effective. The specific implementa...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More