

Method for processing big data based on MLDM algorithm meeting secondary aggregation
A technology of big data and large data sets, applied in the field of privacy protection of databases, it can solve the problems of high algorithm complexity and long calculation time.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
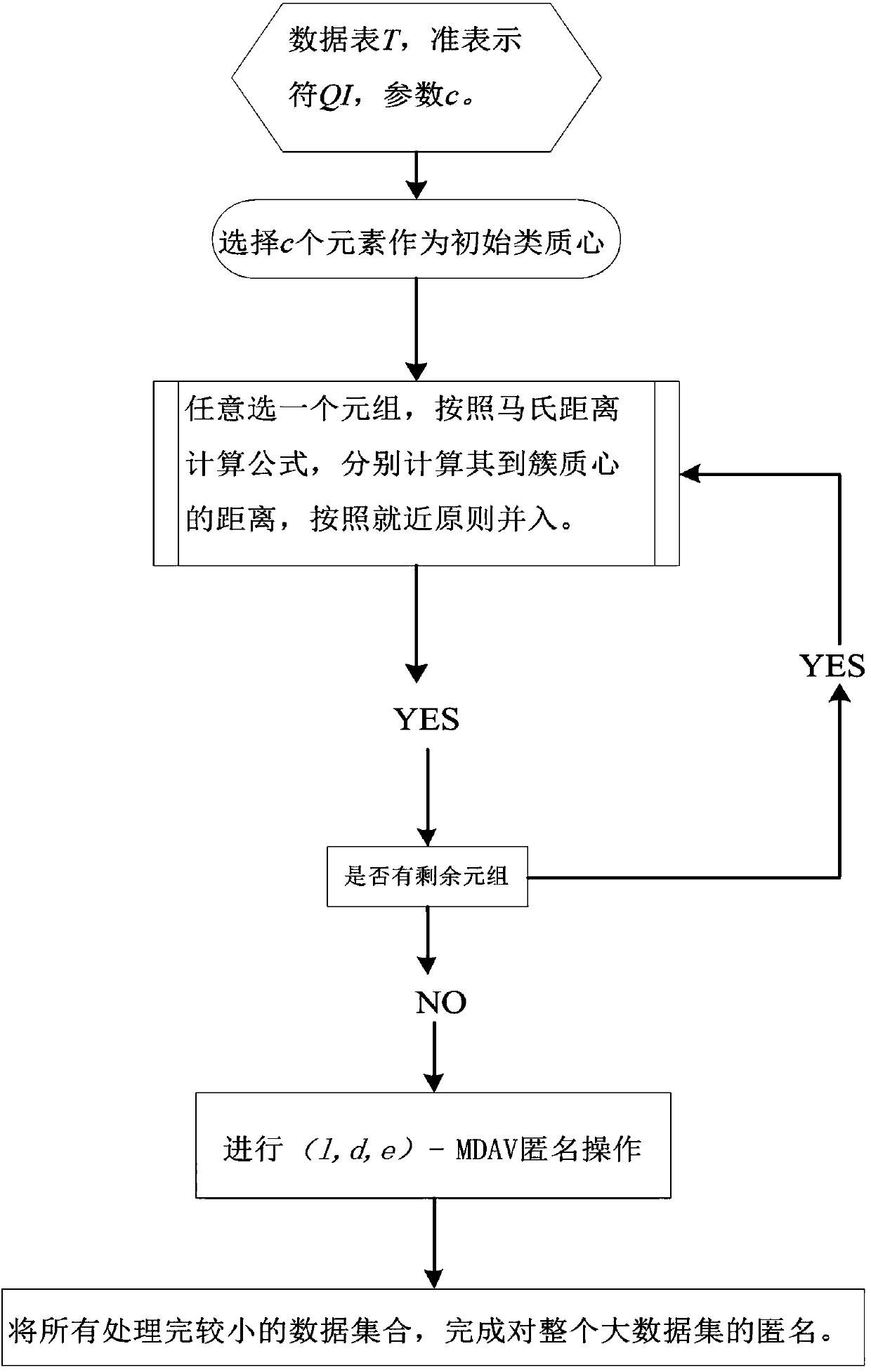
[0033] In order to make the object, technical solution and advantages of the present invention more clear, the present invention will be further described in detail below in conjunction with the examples. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
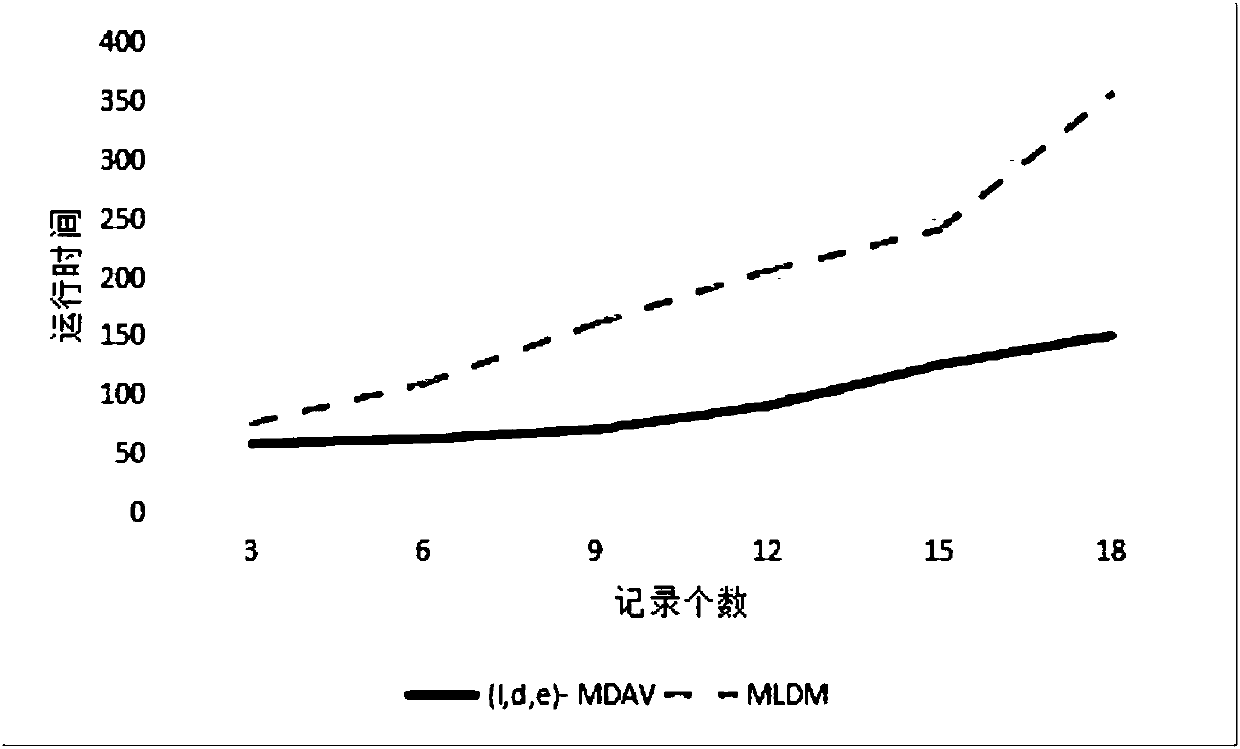
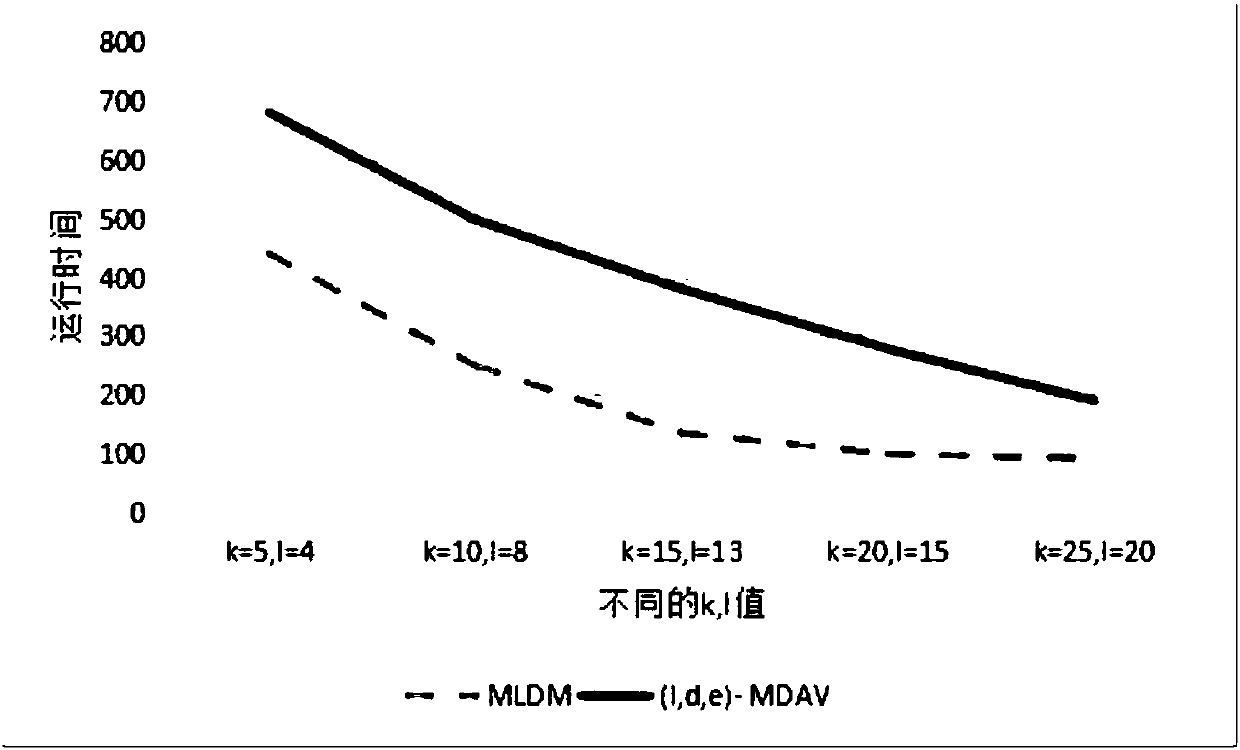
[0034] The present invention further improves on the basis of (l, d, e)-MDAV algorithm, introduces k-means algorithm, proposes MLDM algorithm, and seeks the optimization of algorithm efficiency when processing large data sets. . On the basis of the (l,d,e)-MDAV algorithm, the k-means algorithm is introduced, and a new MLDM algorithm is proposed. When the new algorithm processes a large data set, it first divides the large data set into several small data sets, and then Use the (l,d,e)-MDAV algorithm to process each small data set, and finally combine the processed data so that the entire data set satisfies the (l,d,e)-dive...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More