

Multi-user dialogue audio recognition method and system based on machine learning
A technology of machine learning and recognition methods, applied in the computer field, can solve the problems of not considering the problem of character recognition, not considering personalized scenes, segmentation and poor accuracy of character recognition, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0054] Embodiments of the technical solutions of the present invention will be described in detail below in conjunction with the accompanying drawings. The following examples are only used to more clearly illustrate the technical solution of the present invention, and therefore are only examples, and cannot limit the protection scope of the present invention with this.
[0055] It should be noted that, unless otherwise specified, the technical terms or scientific terms used in this application shall have the usual meanings understood by those skilled in the art to which the present invention belongs.
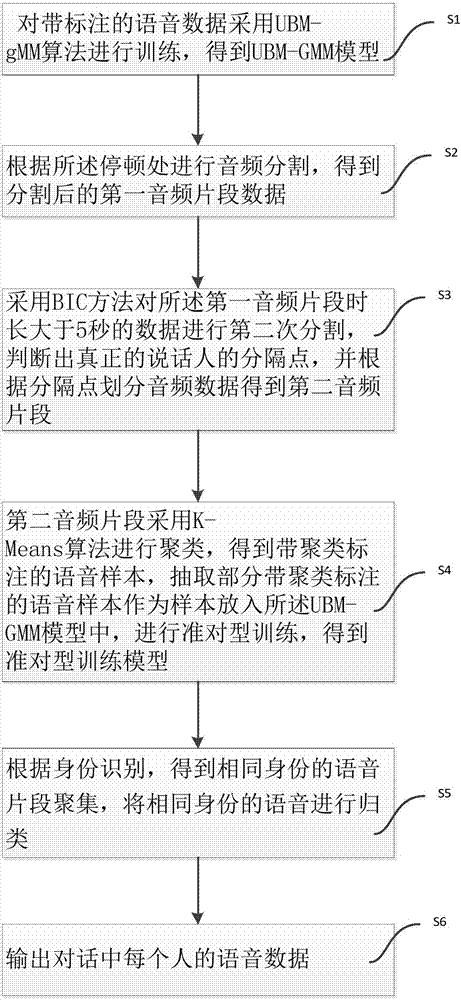
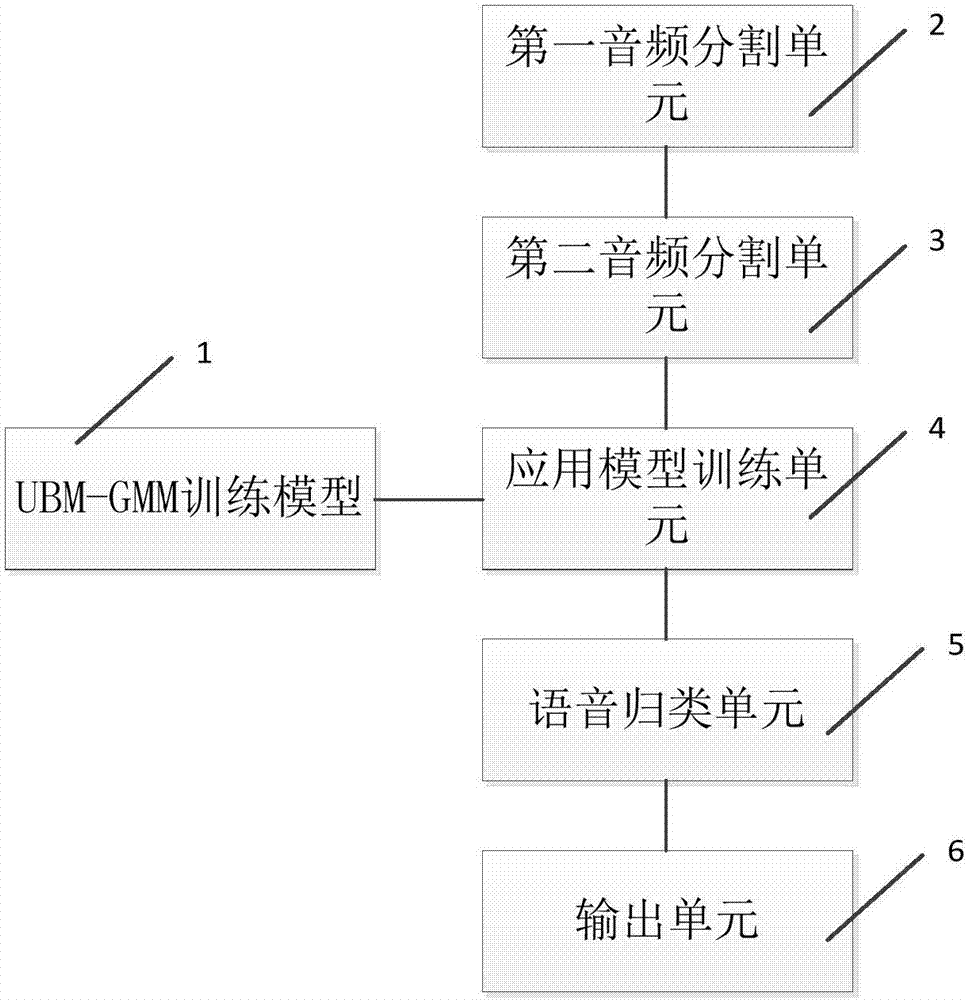
[0056] figure 1 It shows a flow chart of a method for providing machine learning-based multi-person dialogue audio role recognition provided by the first embodiment of the present invention. The multi-person dialogue audio role recognition method based on machine learning of the present embodiment specifically includes the following steps: the voice data with label is trained u...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More