Visual salience and semantic attribute based cross-modal image natural language description method
A technology of semantic attributes and natural language, applied in the field of natural language description of cross-modal images based on visual salience and semantic attributes, can solve the problems of lack of focus and low accuracy of target description, so as to increase the importance and reduce the contribution , the effect of improving the accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0034] In order to make the object, technical solution and advantages of the present invention more clear, the present invention will be further described in detail below in conjunction with the examples. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
[0035] The application principle of the present invention will be described in detail below in conjunction with the accompanying drawings.
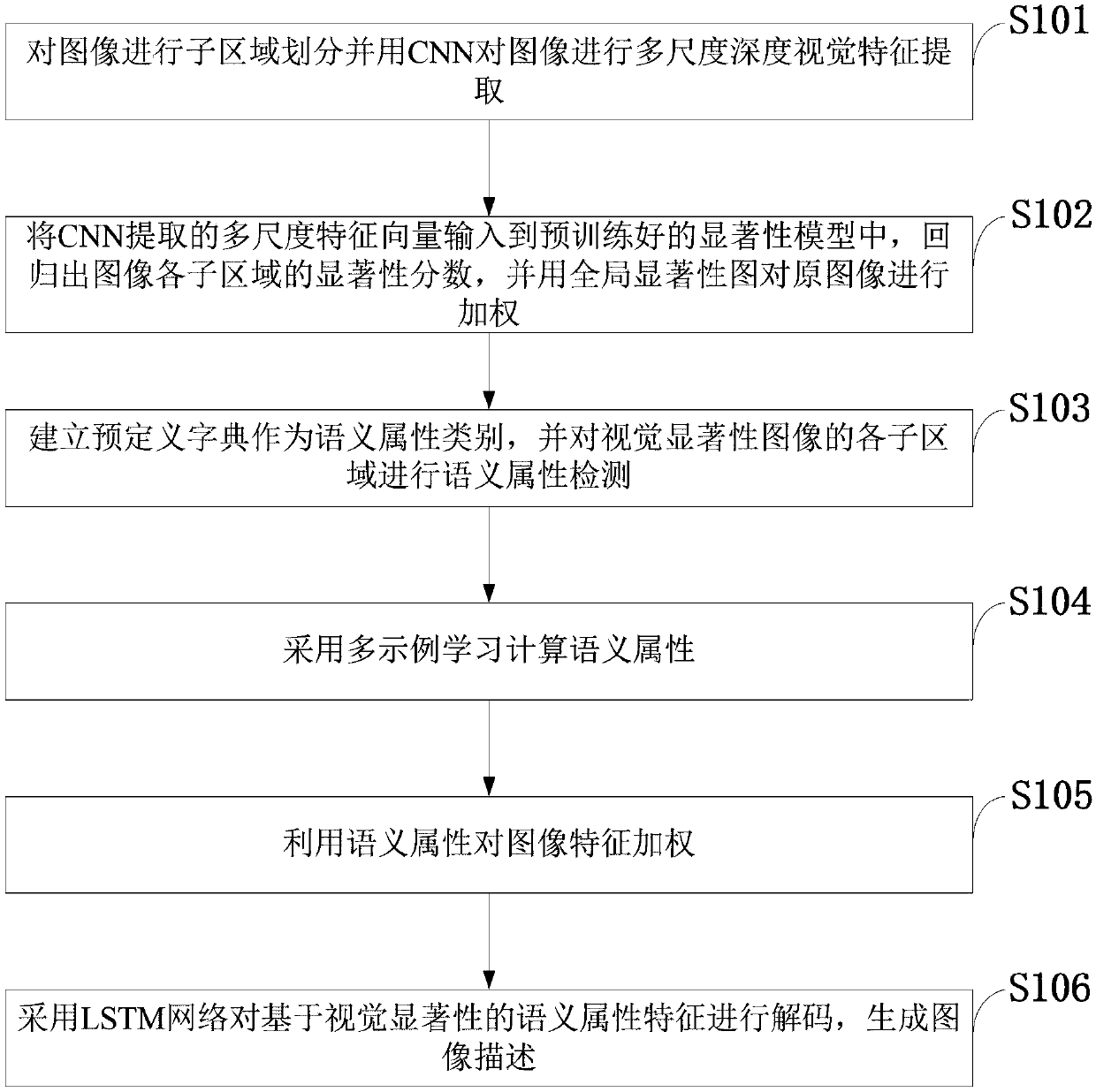
[0036] Such as figure 1 As shown, the cross-modal image natural language description method based on visual salience and semantic attributes provided by the embodiment of the present invention includes the following steps:
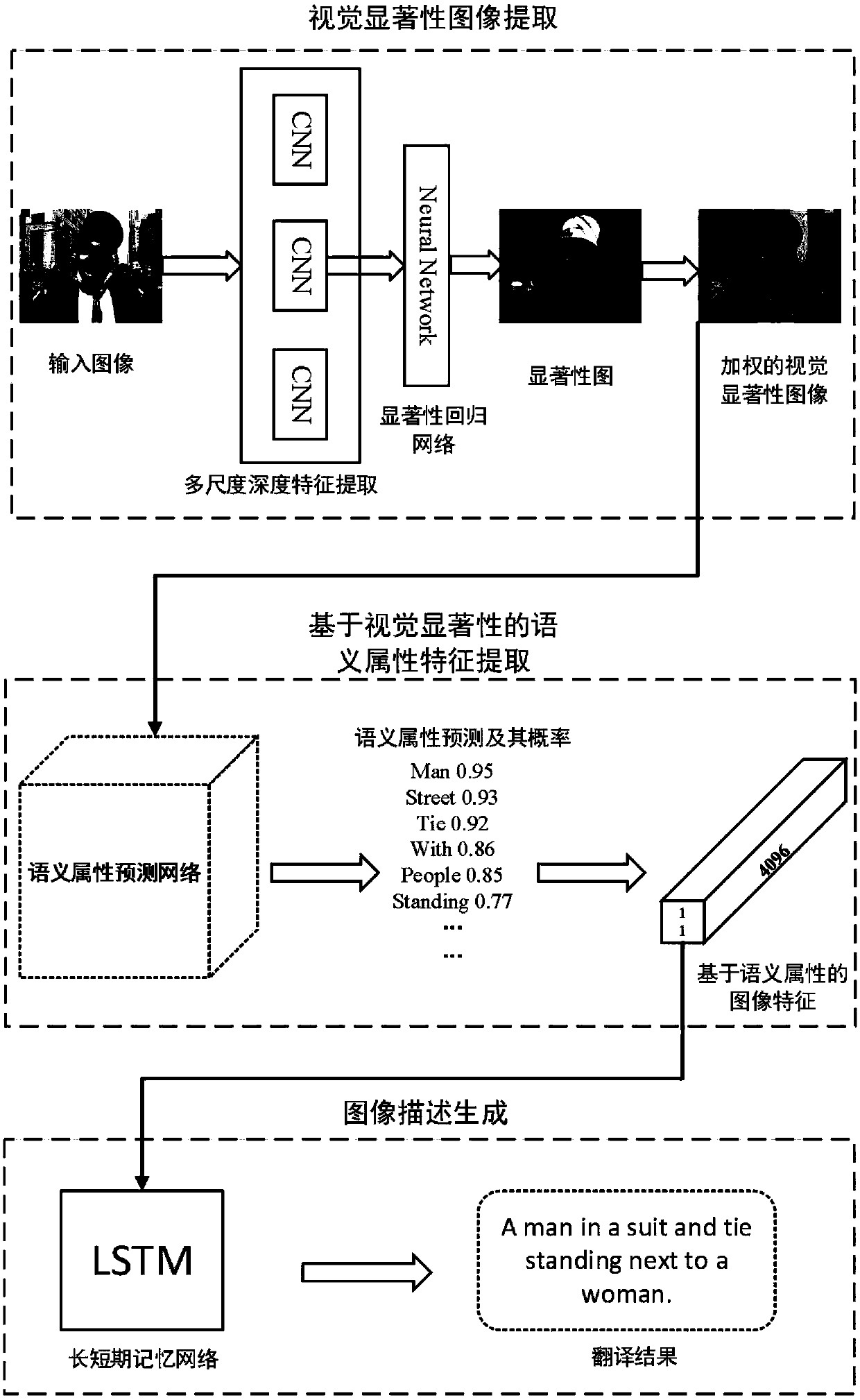
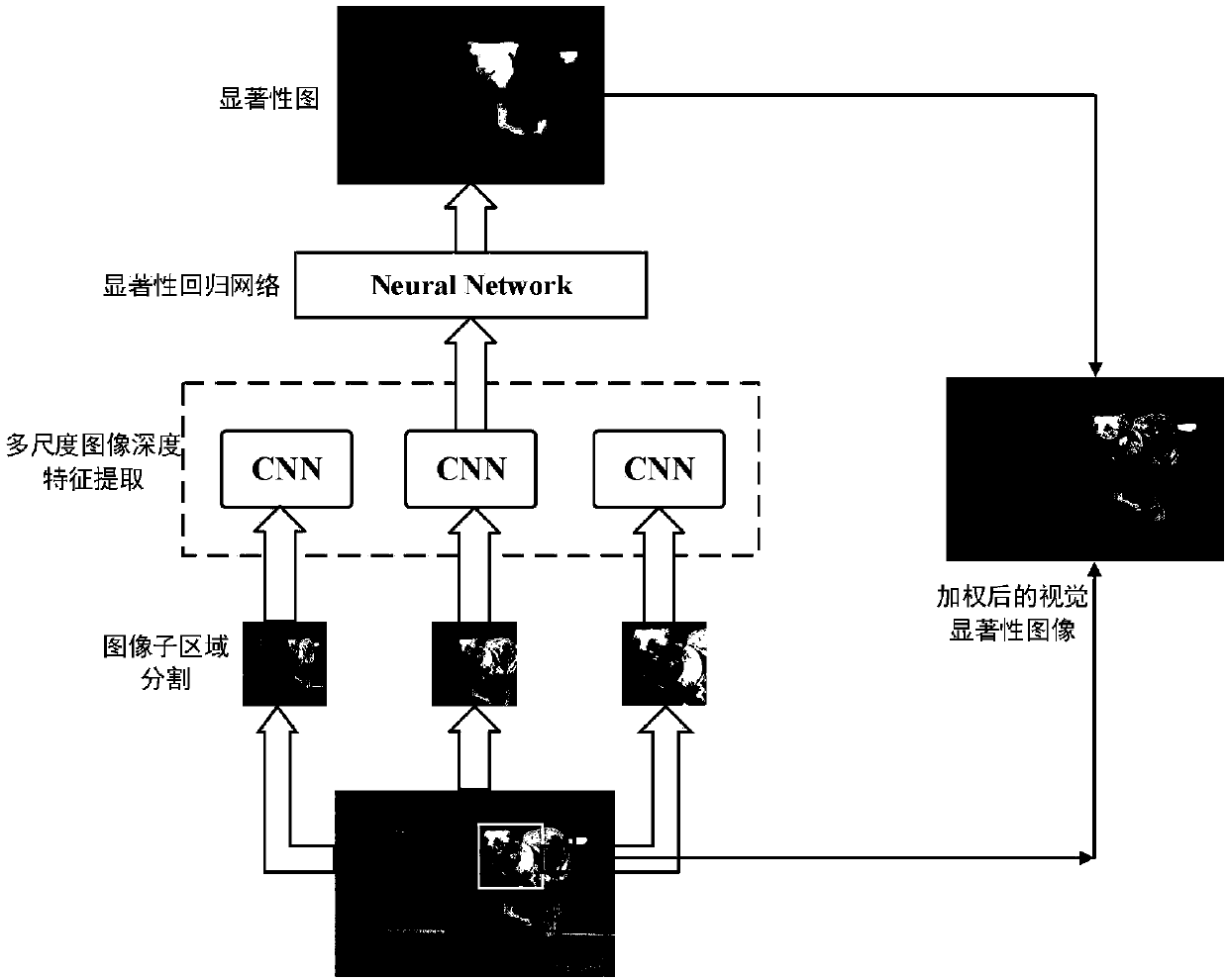
[0037] S101: Divide the image into sub-regions and use CNN to extract multi-scale depth visual features from the image;
[0038] S102: Input the multi-scale feature vector extracted by CNN into the pre-trained saliency model, regress the saliency score of each s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More