Vision-based offline map establishing and positioning method
A construction method and visual positioning technology, applied in directions such as road network navigators, can solve problems such as inability to navigate, unable to know one's own position, etc., and achieve the effect of improving positioning accuracy, precision and accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
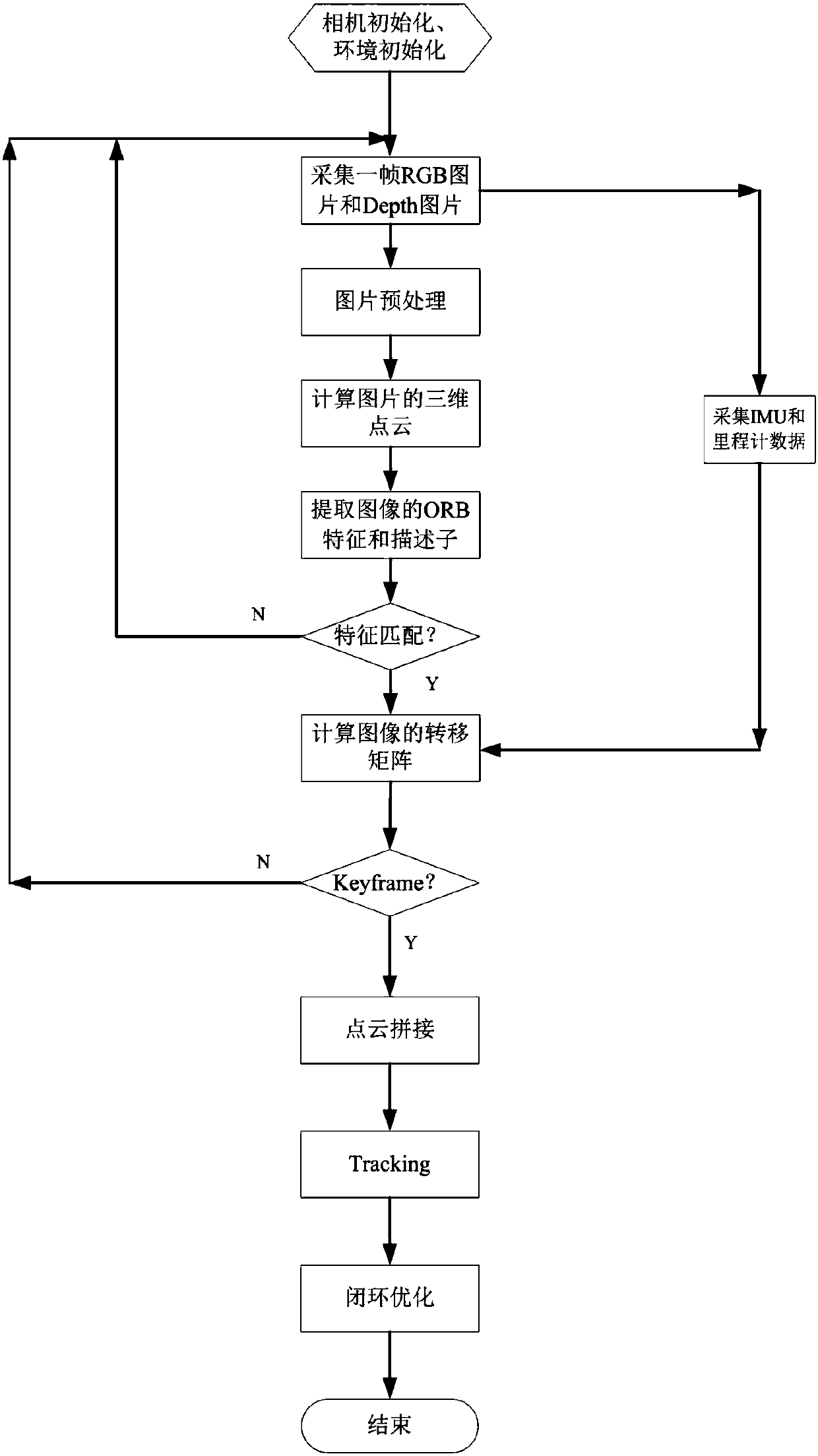
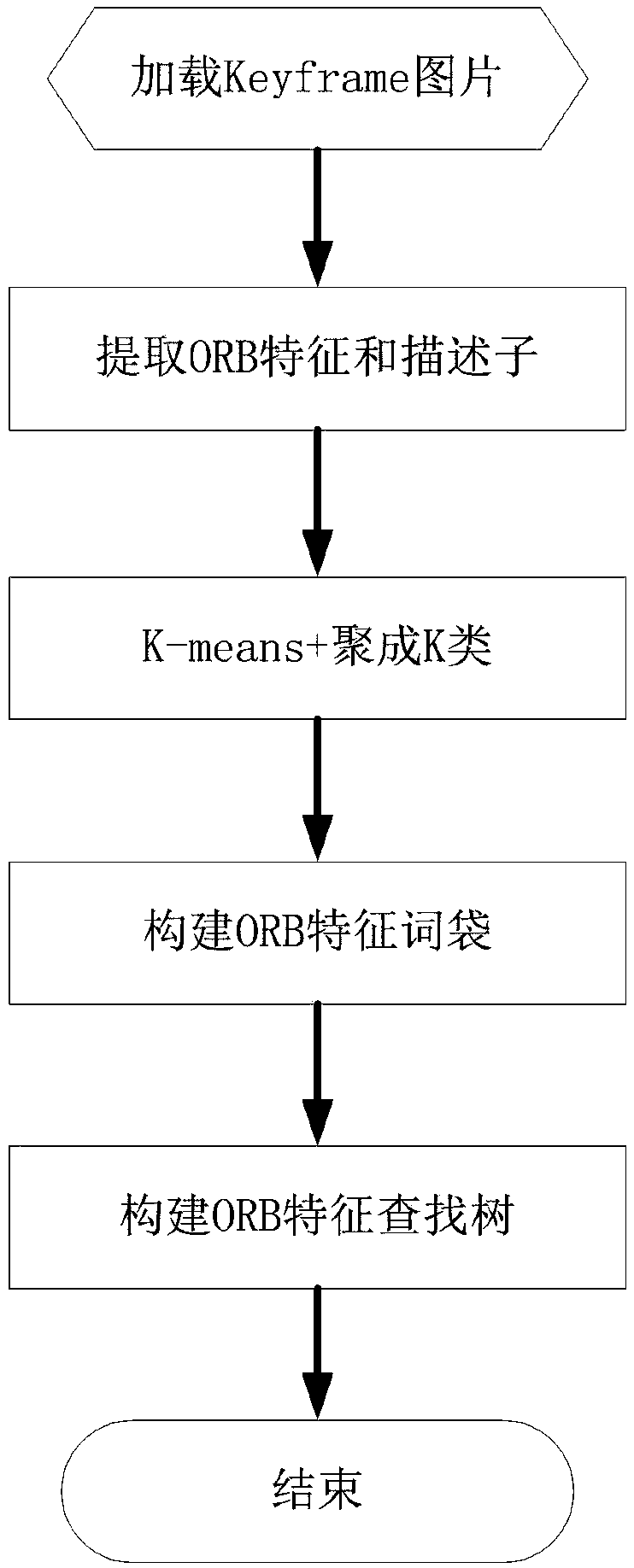
[0032] In the present invention, a method for constructing a map is proposed, which is mainly used in the field of visual positioning to generate a KeyFrame (key frame) of the surrounding environment, thereby realizing effective visual positioning. Although real-time mapping, positioning and navigation are popular at present, the 3D point cloud image established by real-time mapping is not accurate enough, and many problems are prone to occur as the map increases. Therefore, in the embodiment of the present invention, the The method for constructing a map in an offline state adopts the offline map, and in this embodiment, a positioning method of visual positioning fusion of IMU and odometer data is proposed to solve the positioning problem of the robot when the visual positioning fails, specifically Generate a Keypoint and Descriptor search tree through the image keyframes generated during map construction to improve the speed of visual positioning, and use PCA (Principal Compo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More