

Full-coverage granular computing based K-medoids text clustering method
A text clustering and full coverage technology, applied in the field of full coverage granular computing and text clustering, which can solve problems such as low accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

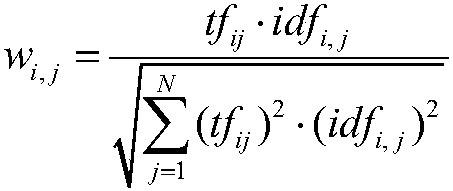
Examples
Embodiment Construction
[0056] In order to further explain the technical means and effects of the present invention to achieve the intended purpose of the invention, the specific implementation methods, features and effects of the present invention will be described in detail below in conjunction with the accompanying drawings and preferred embodiments.
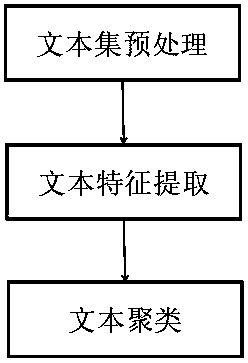
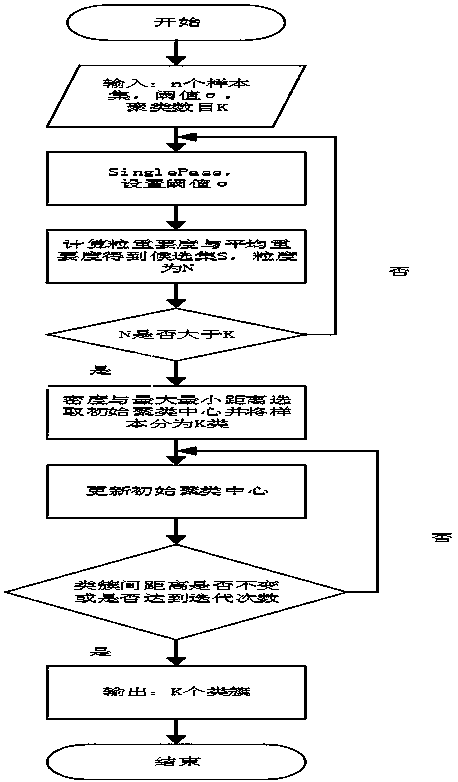
[0057] Such as figure 1 Shown, the overall flow process of the present invention is described in detail as follows:
[0058] Step 1: Use jieba word segmentation to segment the Chinese text, and sort out various stop word lists such as "Harbin Institute of Technology Stop Words Thesaurus", "Sichuan University Machine Learning Intelligence Laboratory Stop Words", Baidu Stop Words List, etc. After re-extracting the new Chinese word list.
[0059] Step 2: Perform TF-IDF feature extraction on the word segmentation results after removing stop words in step 1. TF-IDF is a statistical weighting method, the formula is
[0060]
[0061]
[0062]
...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More