

Voice recognition and voice synthesis model training method based on dual learning
A speech recognition model and speech synthesis technology, applied in the fields of speech synthesis, speech recognition, speech recognition and speech synthesis, can solve the problems of high cost, time-consuming and laborious, and it is difficult to ensure data quality, so as to save cost and solve data problems. small number of effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

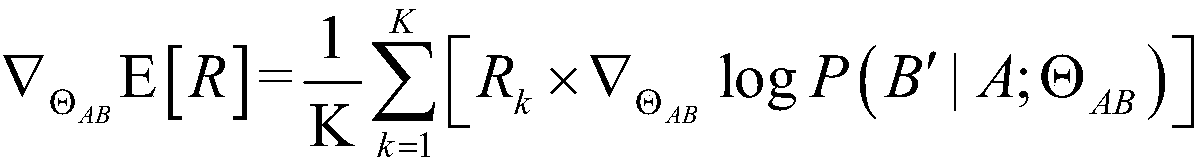
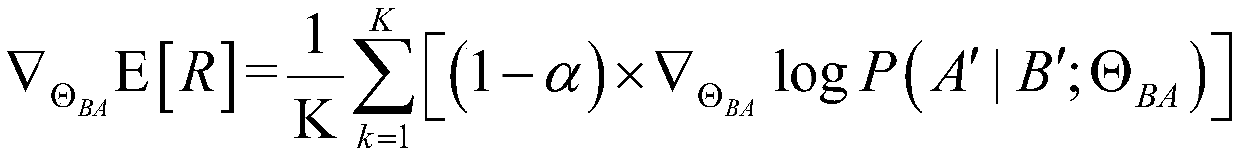
Examples
Embodiment Construction
[0019] The present invention will be further described below in conjunction with specific drawings and embodiments.
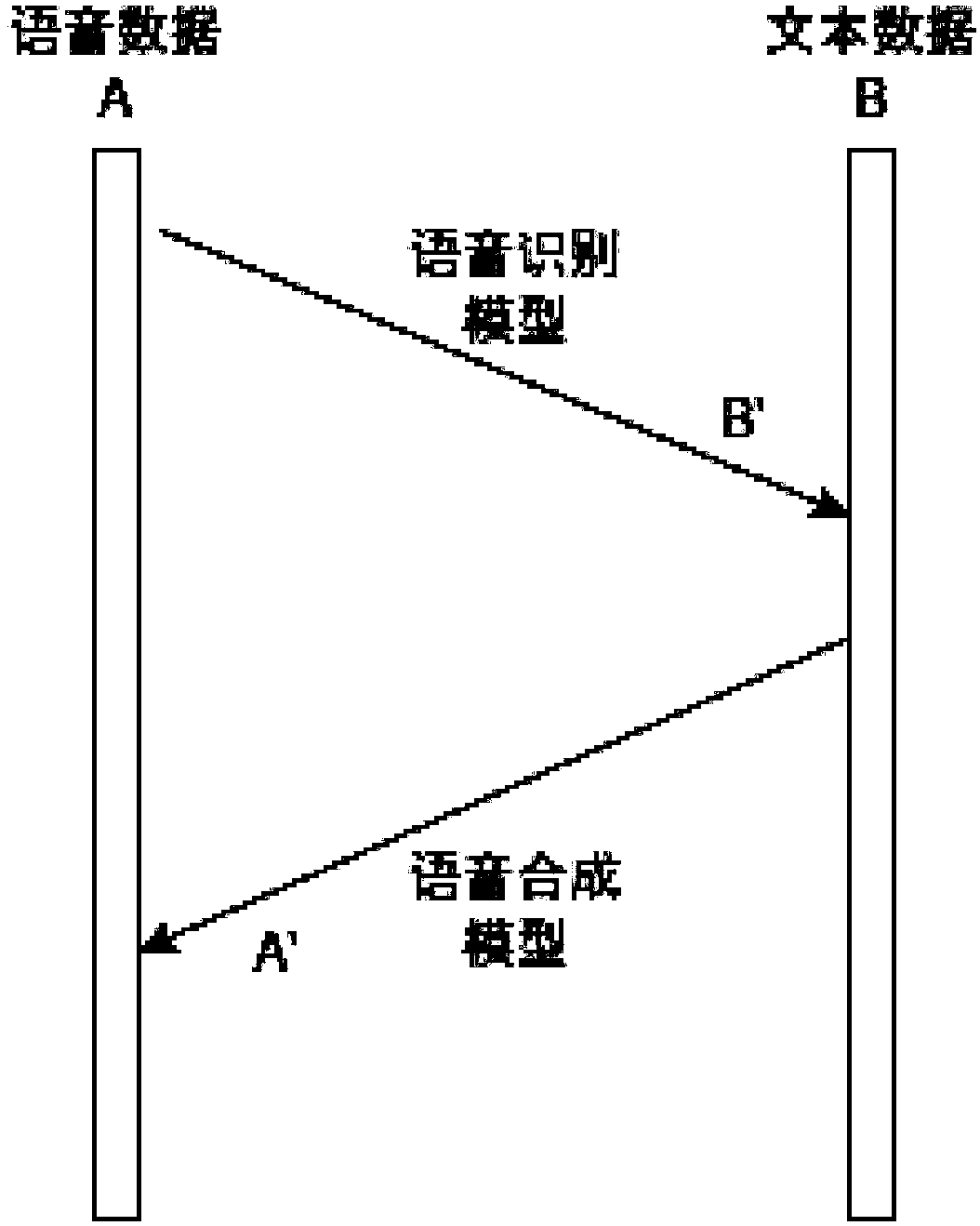
[0020] The general idea of the present invention is: firstly, use less labeled data to pre-train the speech recognition model and the speech synthesis model; The speech recognition model and the speech synthesis model are further trained in a supervised way.
[0021] First, define the input of the algorithm, including: speech data set D for training speech recognition and speech synthesis models A , a text dataset D B ; Speech recognition model Θ to be trained AB ; The speech synthesis model Θ to be trained BA ; Pre-trained speech language model LM used to calculate the confidence that the speech data is generated by humans rather than machine-generated A ; Pre-trained text language model LM used to calculate the confidence that the text data is written by humans rather than generated by machines B ; When updating parameters, the hyperparameter α used to...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More