

A data processing method and device
A data processing and processing unit technology, applied in the field of big data, can solve problems such as bottlenecks, poor SparkonYARN cluster processing performance, and easy performance, and achieve the effect of improving processing performance, avoiding performance bottlenecks, and reducing hardware configuration requirements.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
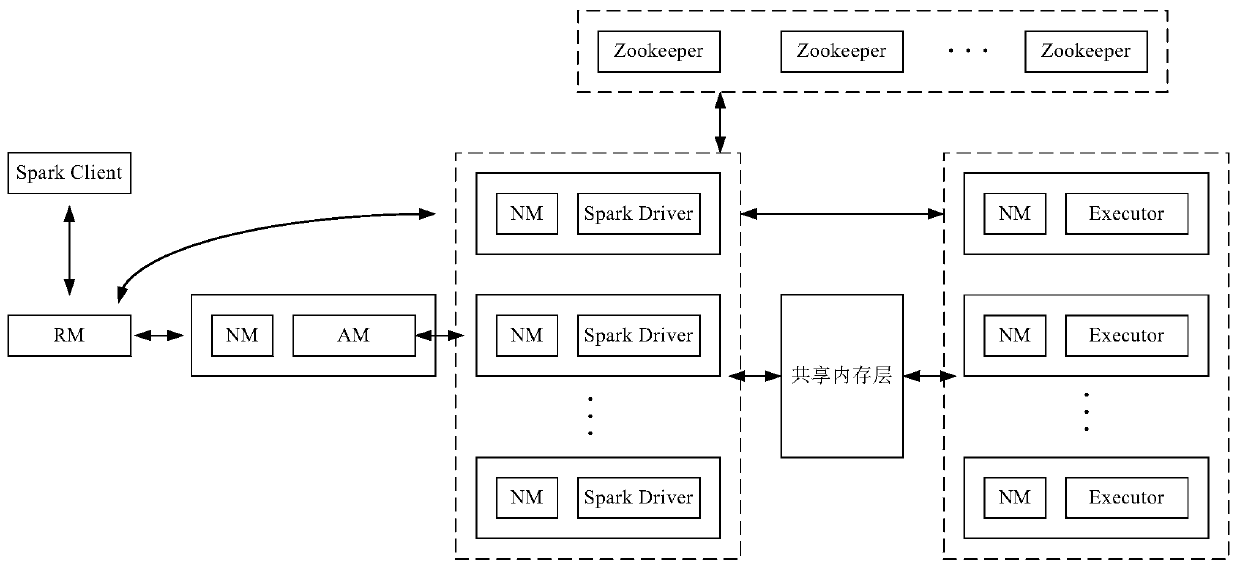
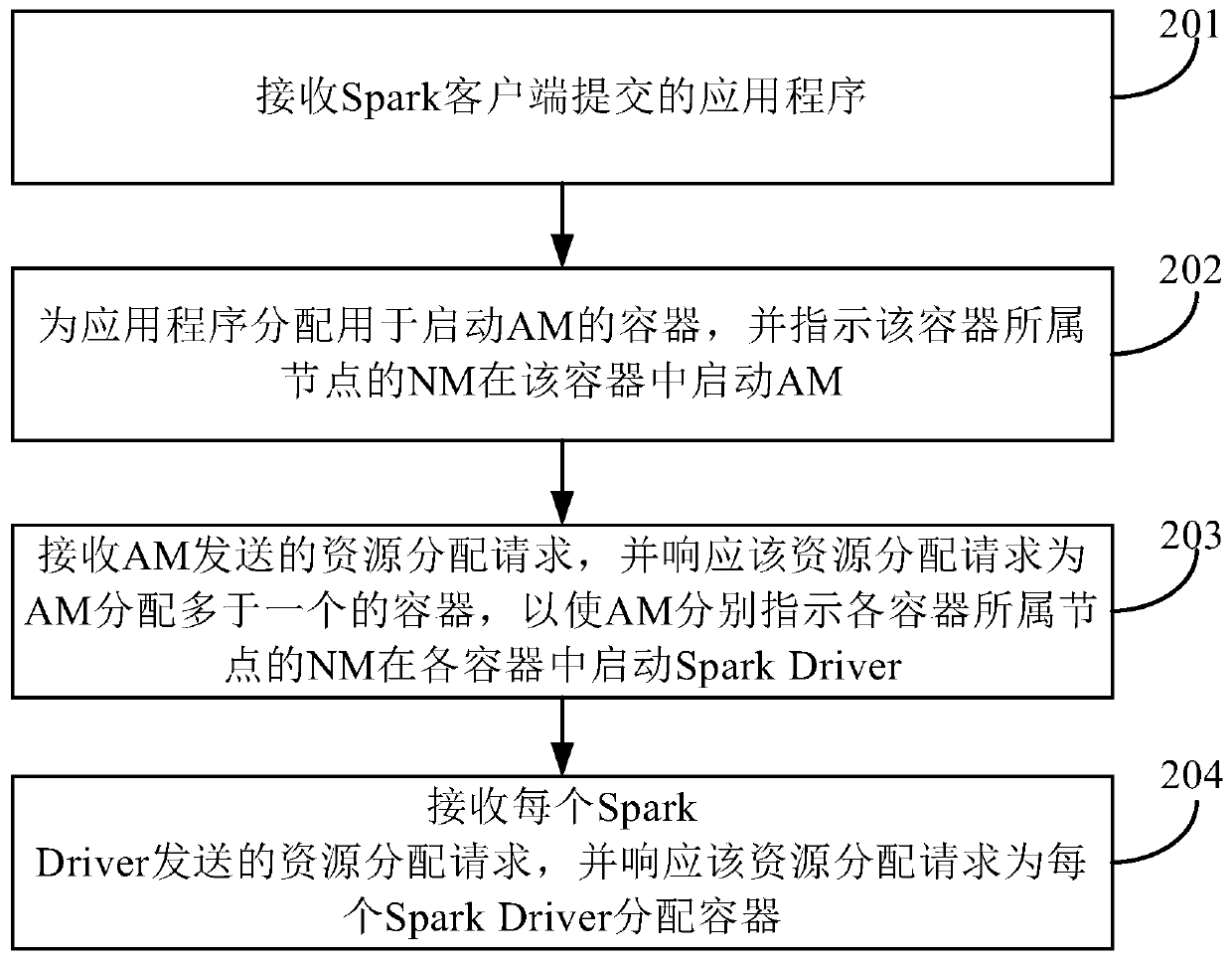
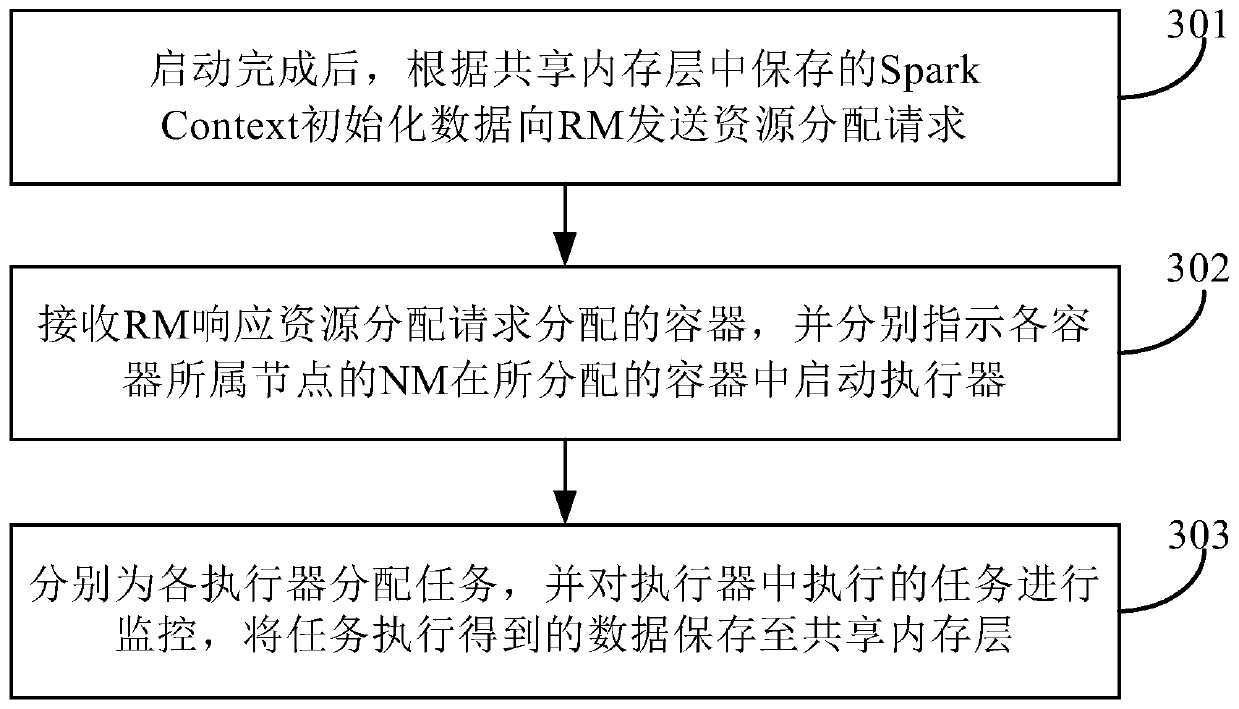
[0048] In order to enable those skilled in the art to better understand the technical solutions in the embodiments of the present invention, some terms in Spark are briefly described below.
[0049] 1. Application: The process of combining multiple batch calculations can be physically expressed as a user-written program package + deployment configuration;
[0050] 2. RDD (Resilient Distributed Datasets, Resilient Distributed Datasets): A batch of data sets with the same source, same structure, and same purpose when spark executes distributed computing. This data set may be divided into multiple partitions (Partition) , distributed on different object nodes. When programming, the RDD object corresponds to this data set, and the RDD object is regarded as a basic unit of data operation. For example, performing a map (mapping) operation on an RDD object is actually equivalent to performing a map operation on each piece of data in each partition in the dataset;
[0051] 3. Partit...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More