

Voice vocal print modeling method and device
A modeling method and voiceprint technology, applied in speech analysis, instruments, etc., can solve problems such as time-consuming and labor-intensive, and achieve the effect of avoiding time-consuming and labor-intensive, low hardware requirements, and meeting the needs of separation and modeling
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
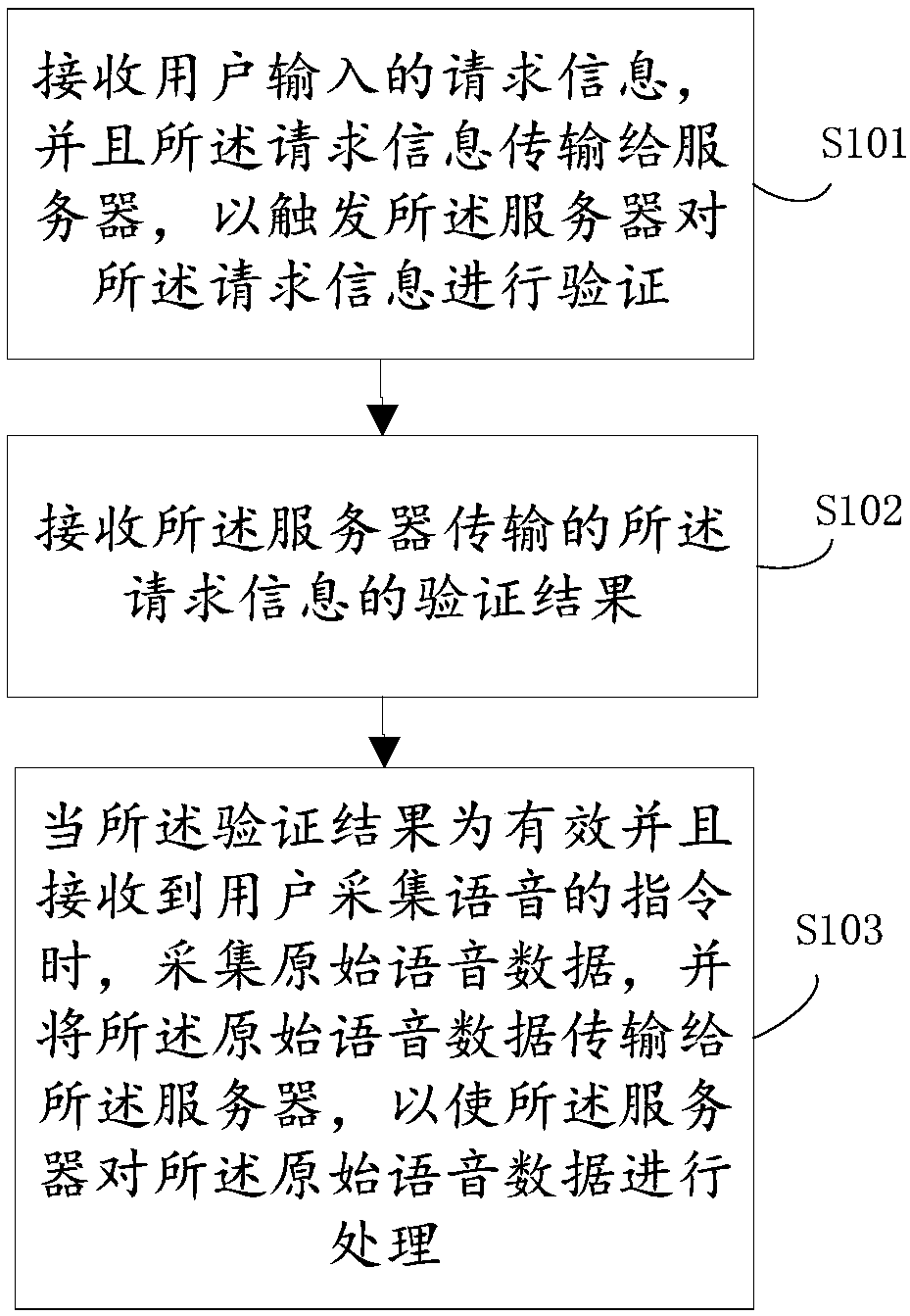
[0050] join figure 1 A flowchart of a voiceprint modeling method is shown, the method is applied to the client, and specifically includes the following steps:
[0051] S101. Receive the request information input by the user, and transmit the request information to the server, so as to trigger the server to verify the request information;
[0052] Specifically, the user submits a collection request through the client, and the user ID and parameter validity are checked through the server. Automatically estimating the number of speakers in a multi-person conversation is a difficult point in speech separation. The present invention combines actual application scenarios and allows users to fill in the actual number of people participating in the conversation, so that the problems of speech segmentation and clustering can be solved more focusedly;
[0053] S102. Receive a verification result of the request information transmitted by the server;
[0054] S103. When the verification...
Embodiment 2
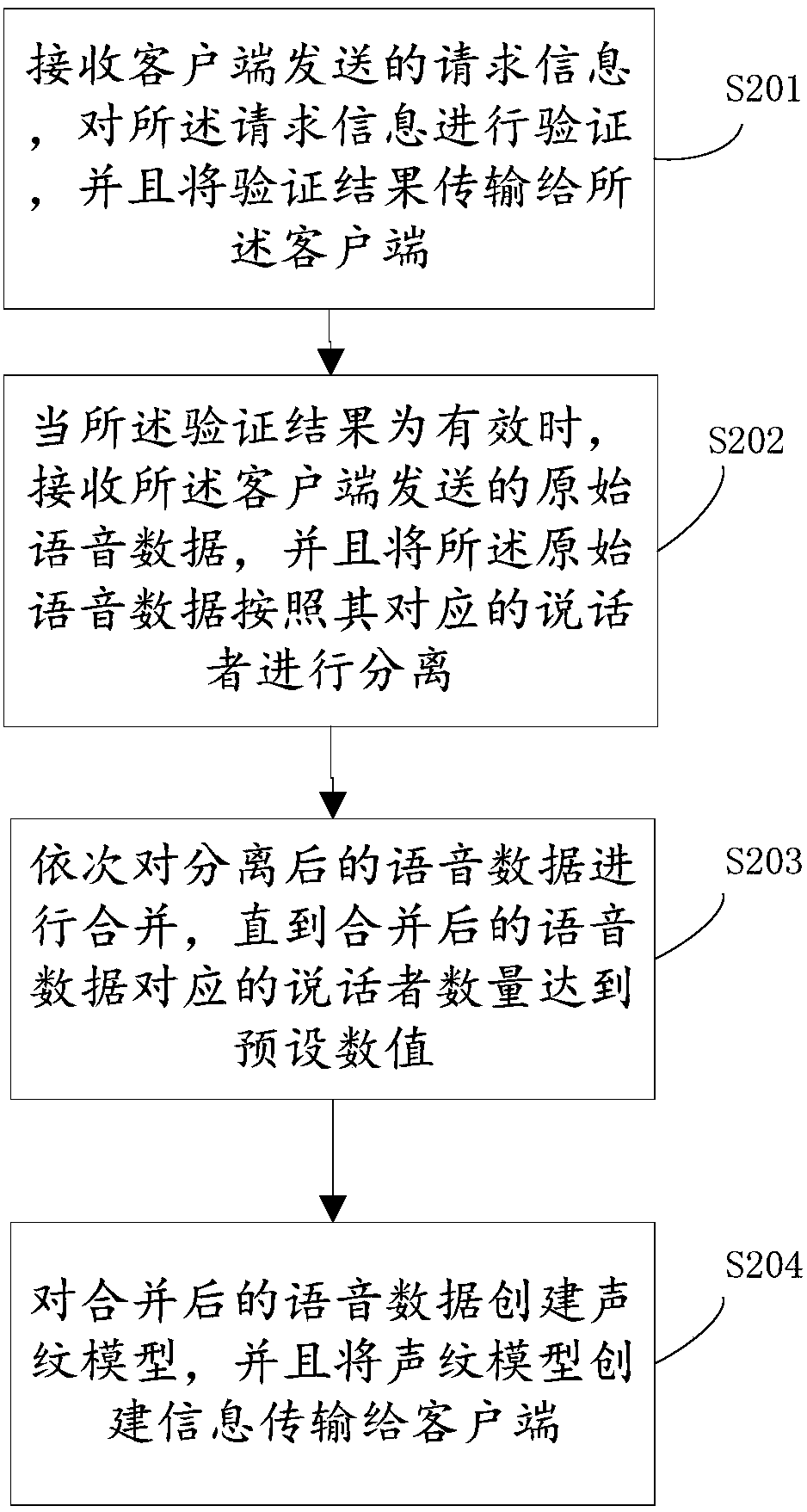
[0057] join figure 2 A flow chart of voiceprint modeling is shown, the method is implemented on the basis of the voiceprint modeling provided in Embodiment 1, and is applied to a server, and specifically includes the following steps:
[0058] S201. Receive the request information sent by the client, verify the request information, and transmit the verification result to the client;
[0059] After the server responds to the registration request, the display device on the client prompts whether to collect the voice data of the reference person in advance. In practical applications, the chat host or conference host is relatively fixed, and usually does not pay attention to their voiceprint, so it can be set to remove invalid information. If the voice of the reference person is not collected in advance, it means that all the speakers participating in the conversation are the persons concerned;
[0060] S202. When the verification result is valid, receive the original voice data...
Embodiment 3
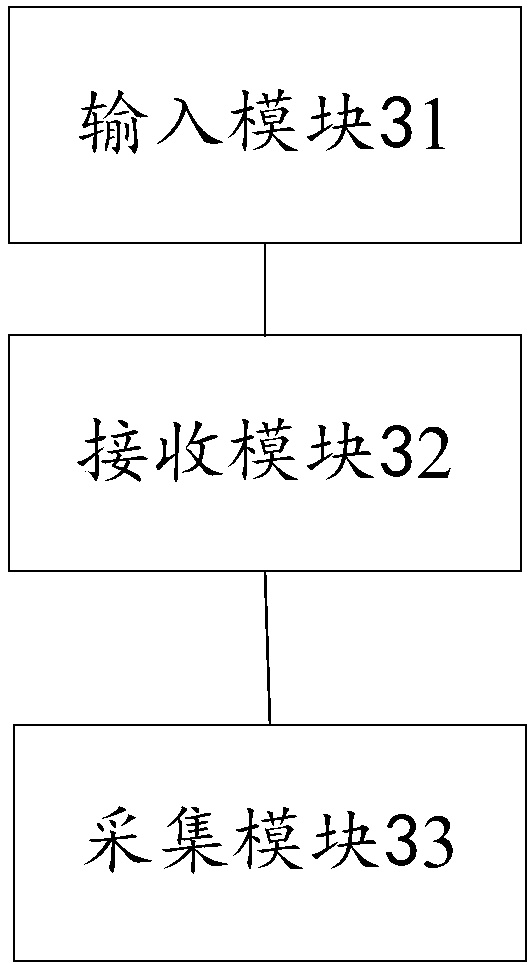
[0087] For the speech voiceprint modeling method provided in the first embodiment, the embodiment of the present invention provides a voiceprint modeling device, see image 3 A structural block diagram of a voiceprint modeling device is shown, which is applied to the client, and the device includes the following parts:
[0088] The input module 31 is configured to receive request information input by the user, and transmit the request information to the server, so as to trigger the server to verify the request information;
[0089] A receiving module 32, configured to receive a verification result of the request information transmitted by the server;
[0090] The acquisition module 33 is configured to collect original voice data when the verification result is valid and an instruction to collect voice from the user is received, and transmit the original voice data to the server, so that the server can process the original voice data. Voice data is processed.
[0091] The emb...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More