

Speech recognition acoustic model building method and device, and electronic equipment
An acoustic model and speech recognition technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of speech recognition accuracy rate decline, speech recognition accuracy rate, and internal changes are not rich, so as to improve the accuracy rate and general The effect of chemical performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

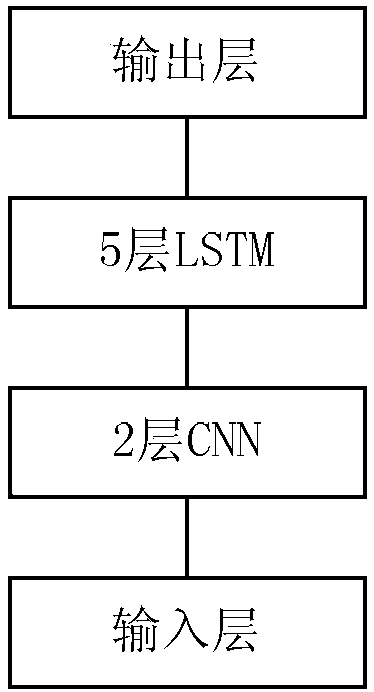
Examples
Embodiment Construction
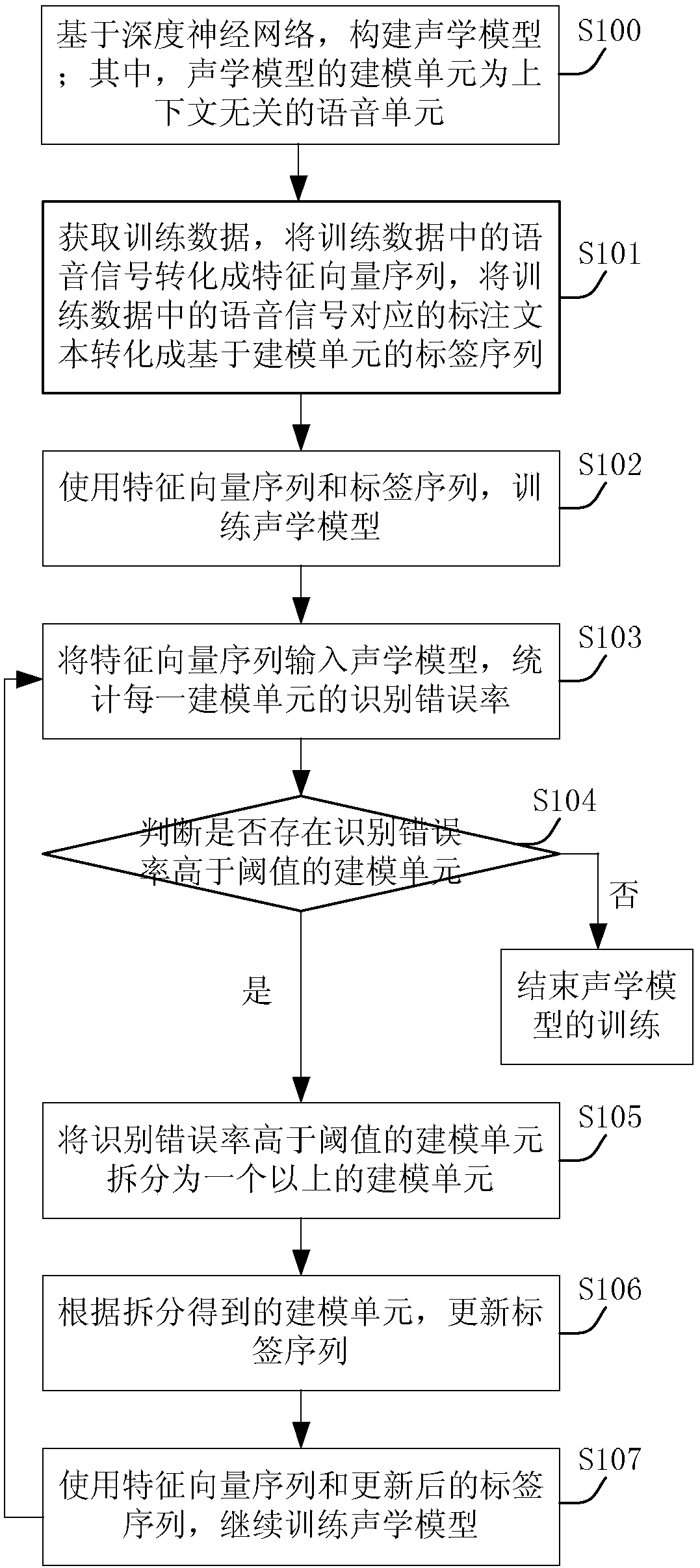
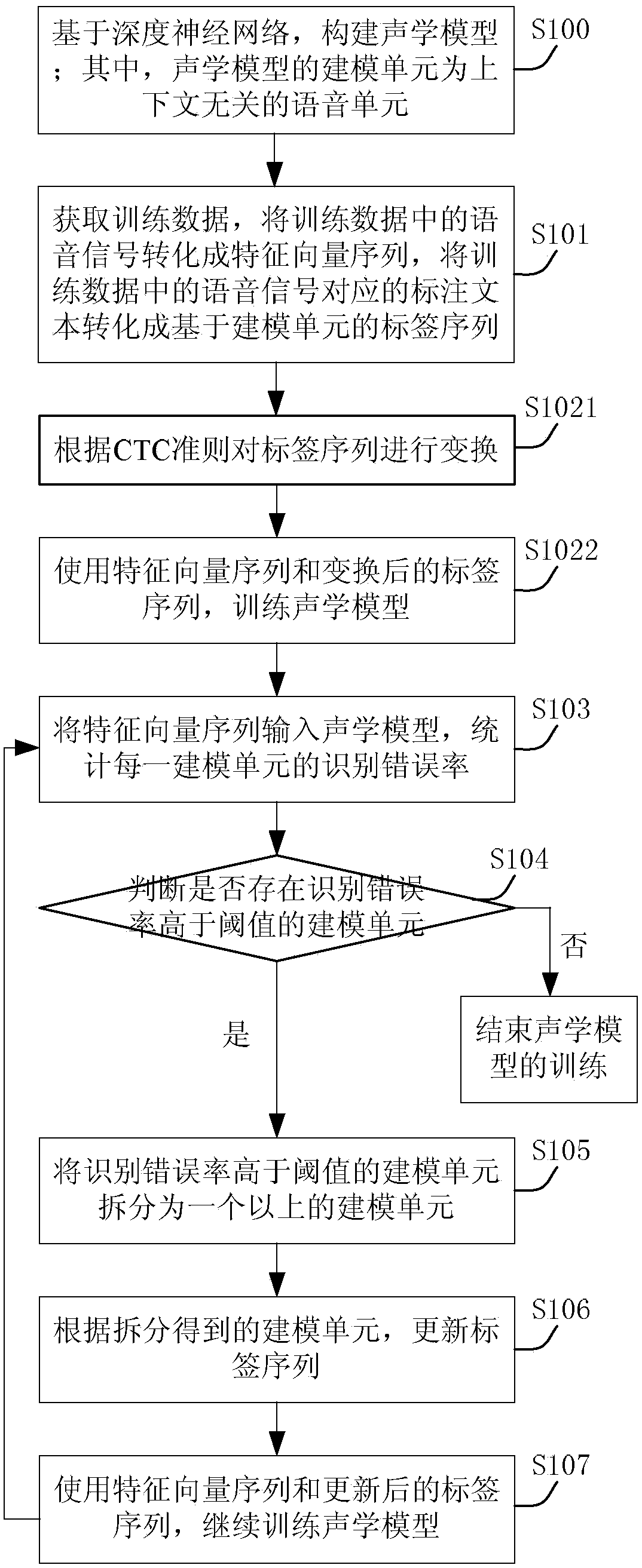
[0084] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
[0085] For convenience and explanation, the words appearing in the embodiments of the present invention are described below.
[0086] Syllable: It is a basic unit of speech that can be distinguished clearly by hearing. It is a normal pronunciation unit, and there are obvious perceivable boundaries between syllables; For example, in Chinese, the pronunciation of a Chinese character is generally one syllable, such as: the syllable corresponding to the Chinese te...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More