Data clustering method based on bivariant weighted kernel FCM algorithm
A data clustering and variable weighting technology, applied in the field of data clustering, to achieve the effect of strong anti-noise, accurate clustering results, and increased robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

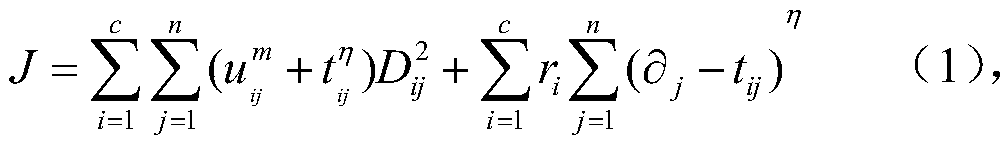
Examples
Embodiment Construction
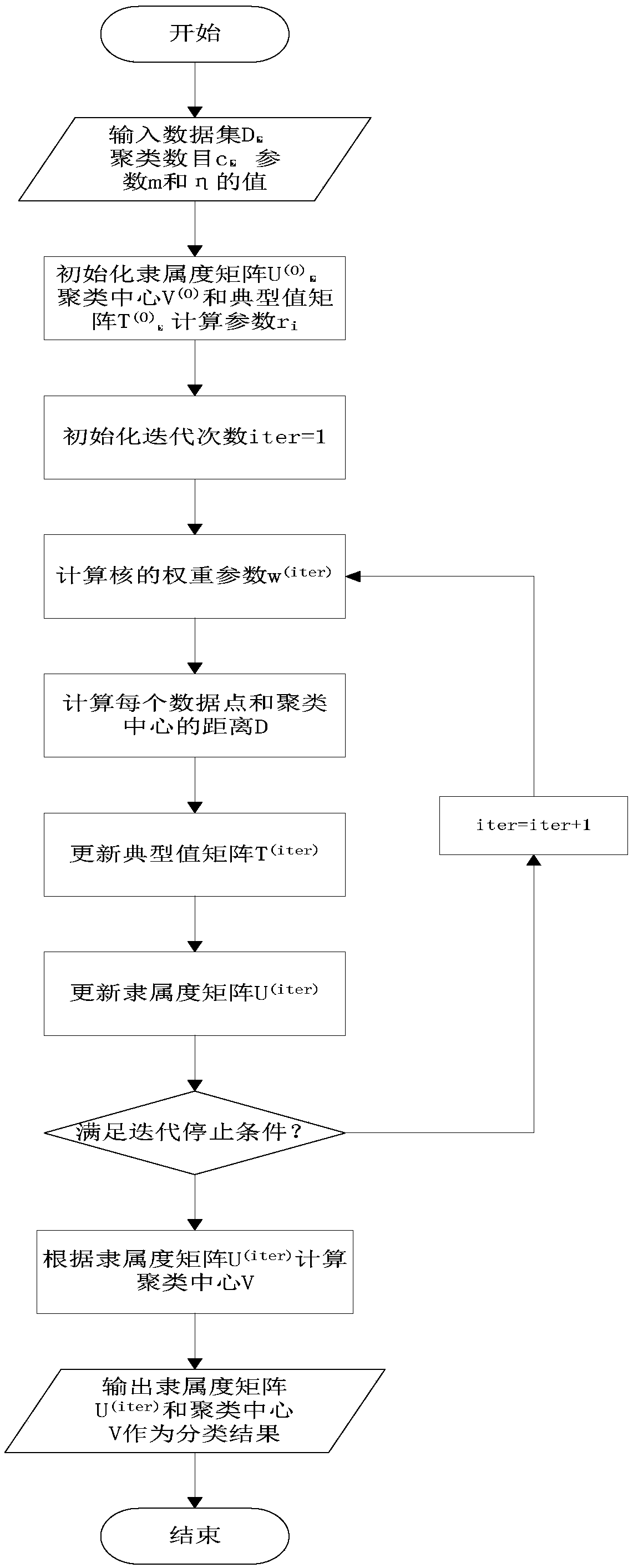
[0044] see figure 1 , in this embodiment, the data clustering method based on the bivariate weighted kernel FCM algorithm is used to cluster customer information, and recommend products to customers according to the clustering results, as follows:
[0045] Step 1, data set X is customer information, X={x 1 ,x 2 ,...,x n},x j is the jth data point; j=1,2,...,n, n is the total number of data, for example: take 10,000 customer information, that is, n=10000; optimally divide the data set X, so that the formula ( The value of the objective function J in 1) is the minimum:
[0046]
[0047] In formula (1), i represents the i-th category, and c represents the number of categories divided, that is, the type of product, such as: c=10, 1≤i≤c, 2≤c≤n; u ij represents the jth data point x j The membership degree value of the i-th category; for u ij m power of , m is a weighted index indicating the degree of clustering fuzziness, m can take a value of 2, t ij represents the jth...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More