

An error correction method and system based on a language model and word features
A technology of language model and error correction method, which is applied in natural language data processing, special data processing applications, instruments, etc., and can solve problems such as relying on word segmentation effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

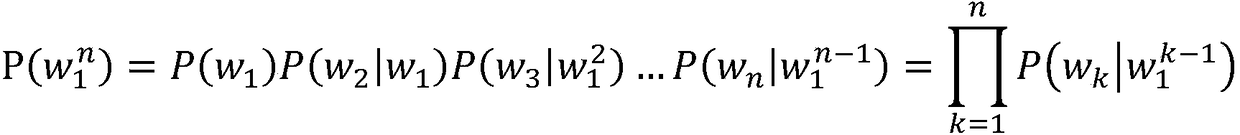
Examples
Embodiment 1
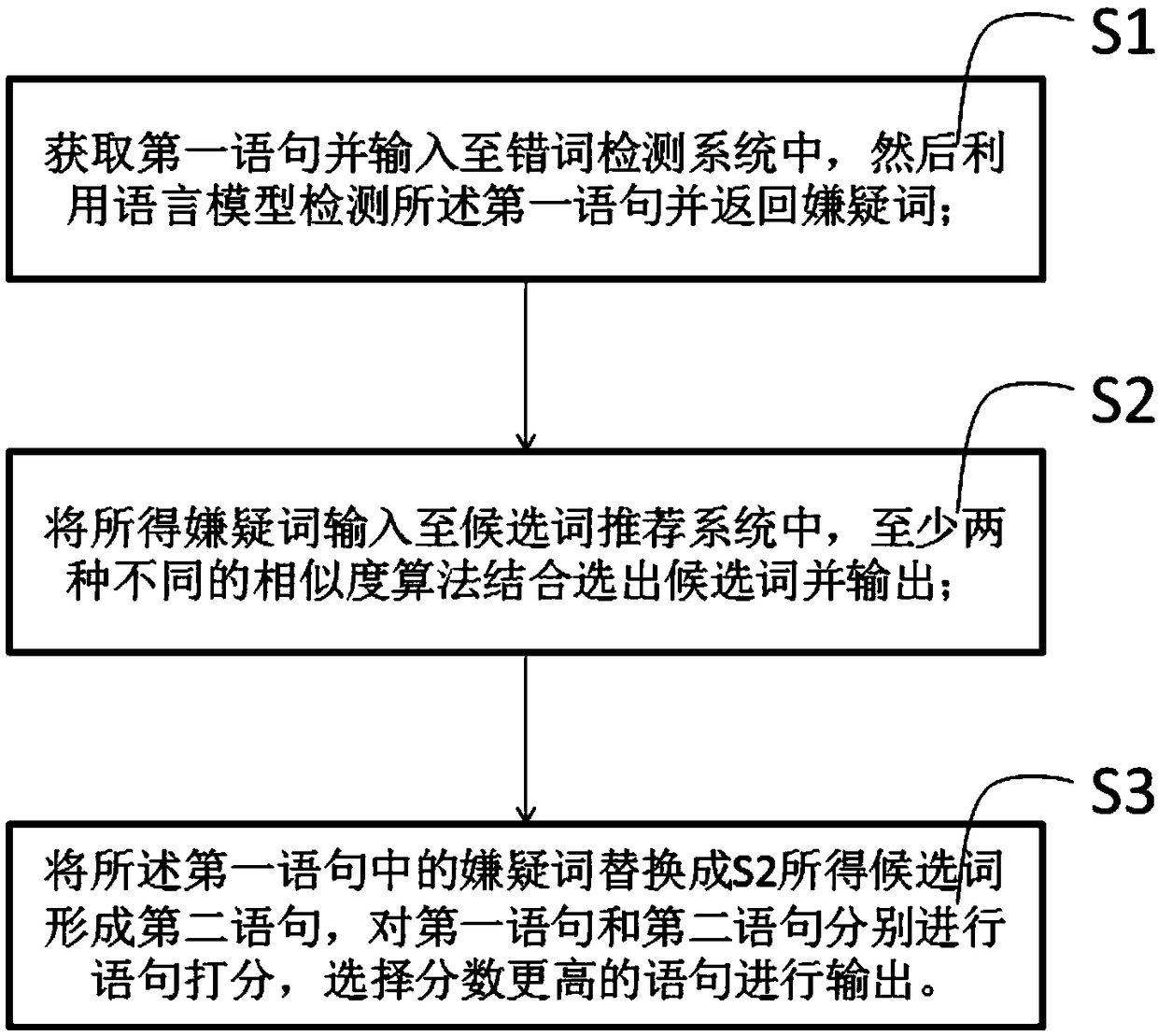
[0052] A schematic flow chart of a preferred embodiment of the error correction method based on the language model and word features of the present invention, as figure 1 As shown, the method includes the following steps:
[0053] S1: Obtain the first sentence and input it into the wrong word detection system, then use the language model to detect the first sentence and return the suspect word;
[0054] S2: Input the obtained suspect words into the candidate word recommendation system, and combine at least two different similarity algorithms to select candidate words and output them;
[0055] S3: Replace the suspect word in the first sentence with the candidate word obtained in S2 to form a second sentence, perform sentence scoring on the first sentence and the second sentence, and select a sentence with a higher score for output.
[0056] The above is a basic implementation manner of the technical solution. In this technical solution, the inventor uses at least two differen...
Embodiment 2
[0089] This embodiment is another preferred implementation mode in combination with the basic implementation mode of the above-mentioned embodiment 1. The difference between this embodiment and the above-mentioned embodiment 1 is that in this embodiment, the S2 specifically includes:
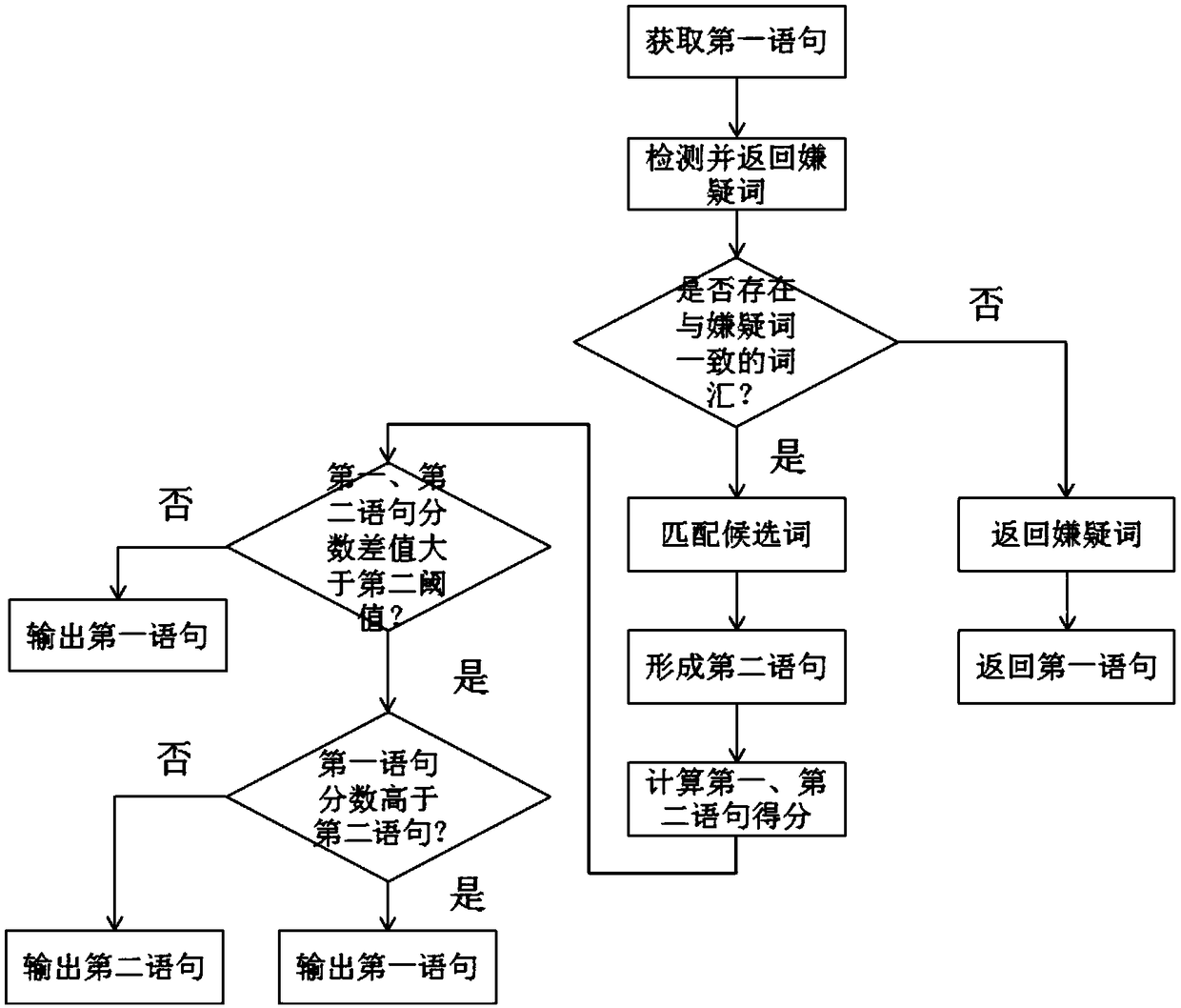
[0090] S21: Obtain the suspect word, find out whether there is a vocabulary consistent with the suspect word in the dictionary in the candidate word recommendation system, if yes, return the suspect word; if not, go to S22;
[0091] S22: Use at least two different similarity algorithms to calculate and match candidate words similar to the suspect word, and each algorithm obtains one or more candidate words for output.
[0092] It should be noted that, in this technical step, if a vocabulary consistent with the suspect word is found in the dictionary in the candidate word recommendation system at the time of S21 matching, it means that the suspect word is correct, and the original suspect Word re...
Embodiment 3
[0106] This embodiment is another preferred implementation mode in combination with the basic implementation mode of the above-mentioned embodiment 1. The difference between this embodiment and the above-mentioned embodiment 1 is that in this embodiment, the S3 also includes:
[0107] Using the difference between the scores of the first sentence and the second sentence as the error correction confidence value, if the error correction confidence value is greater than the second threshold, then select the sentence to be tested with a higher score to output; if the error correction If the confidence value is less than the second threshold, the first statement is output.
[0108] Since it is impossible for the language model to make a perfect score for all Chinese word collocations, there are some errors in the above-mentioned wrong word detection method, that is, some of the original correct word collocations are misreported as wrong words, so we can judge whether the n-gram is a ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More