

Speech recognition method based on convolution neural network
A convolutional neural network and speech recognition technology, applied in the field of speech recognition based on convolutional neural network, can solve the problems of long training time of acoustic model, complex modeling process, limited application, etc. The effect of simple modeling process and easy training
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
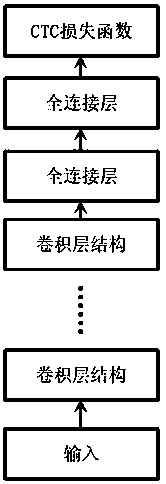
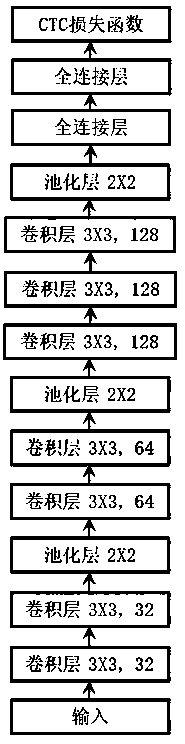
[0049] Such as Figure 1~Figure 5 As shown, the technical solution of the present invention is based on DCNN (Deep Convolutional NeuralNetwork) network model and CTC (Connectionist Temporal Classification, connectionist temporal classifier) method to realize the acoustic model of end-to-end mode; comprising the following steps:
[0050] S1: Input the original voice, preprocess the original voice signal, and perform related transformation processing;
[0051] S2: Extract key feature parameters reflecting the features of the speech signal to form a sequence of feature vectors;
[0052] S3: Build an acoustic model; use the DCNN network model as the basis and use the connectionist time classifier CTC as the loss function to build an end-to-end acoustic model;
[0053] The structure of the acoustic model includes multiple convolutional layers, two fully connected layers, and CTC loss function set in sequence; the structure of multiple convolutional layers is: the first layer and...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More