

A multimodal speech emotion recognition method based on enhanced residual neural network
A neural network and emotion recognition technology, applied in biological neural network models, neural learning methods, character and pattern recognition, etc., to achieve the effect of solving the problem of unequal input dimensions and reducing the voice dimension
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0047] specific implementation plan
[0048] The present invention will be further described below in conjunction with the accompanying drawings and embodiments.
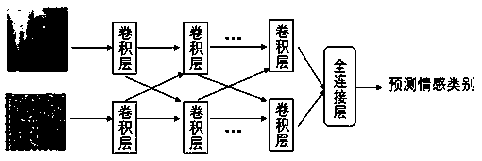
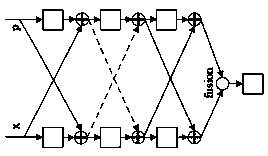
[0049] see figure 1 , a multimodal speech emotion recognition method based on enhanced deep residual neural network. The core model is a cross-enhanced deep residual neural network model, which can accept multiple modal data with different dimensions: speech , video, etc. At the same time, the basic structure of residual convolution can extract features from data, while the cross-type residual convolution structure and fusion function make multi-modal data fully fused, thus effectively improving the accuracy of emotion recognition .
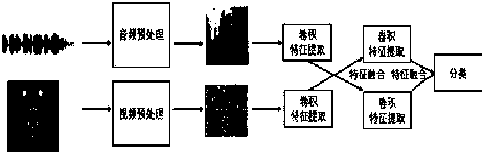
[0050] see figure 2 , an overall data flow of a multimodal speech emotion recognition method based on an enhanced deep residual neural network, the specific steps are as follows:
[0051] (11) Audio preprocessing: The original speech signal is extracted from the spectrogram featur...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More