A GPU acceleration method for multiplying a large-scale sparse matrix by a transposed matrix of the large-scale sparse matrix
A technology of sparse matrix and transposed matrix, which is applied in the direction of multi-channel program device, program synchronization, and data processing according to predetermined rules, which can solve the problems of inability to fully utilize the advantages of GPU in the program and in-depth optimization of thread design, so as to reduce floating Point calculation, the effect of solving the calculation time-consuming and reducing the time required for operation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0044] The technical solution of the present invention will be further described below in conjunction with the accompanying drawings.
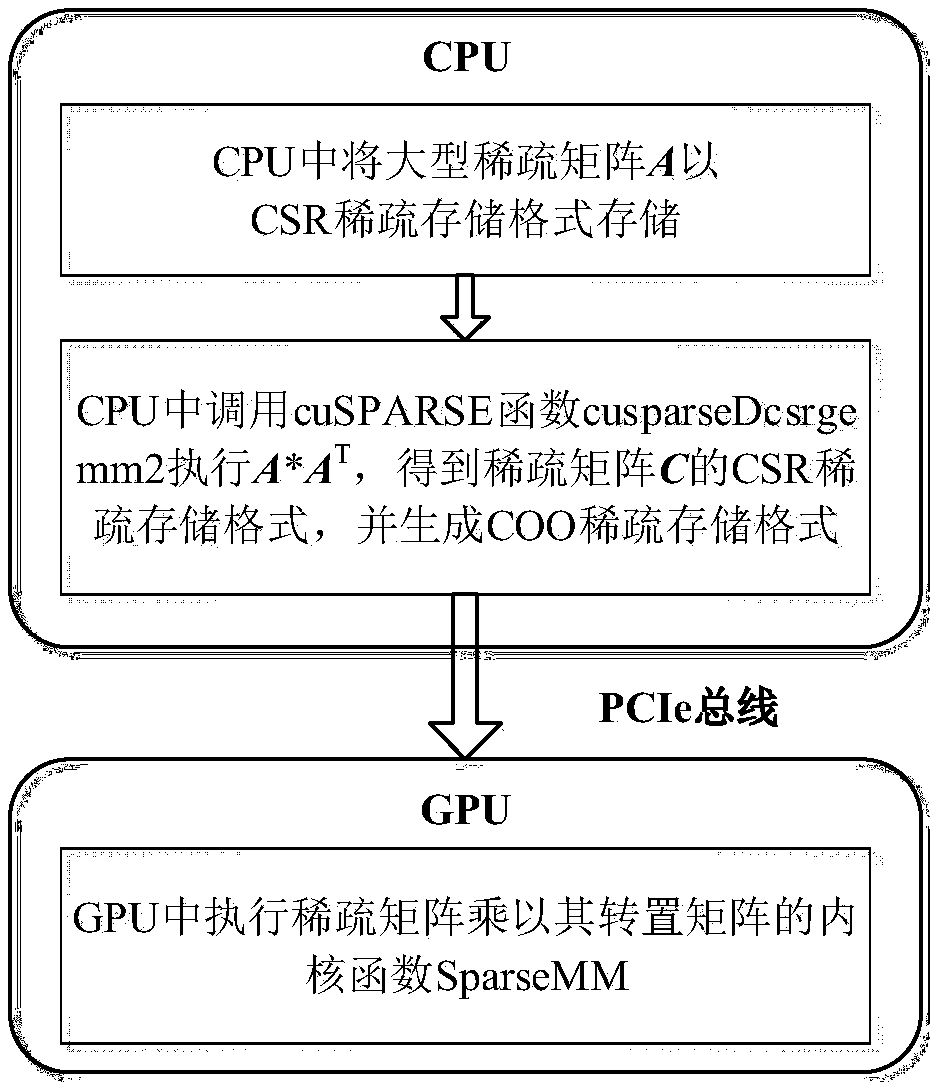
[0045] like image 3 Shown, a kind of large-scale sparse matrix of the present invention is multiplied by the GPU acceleration method of its transpose matrix, described method comprises the following steps:
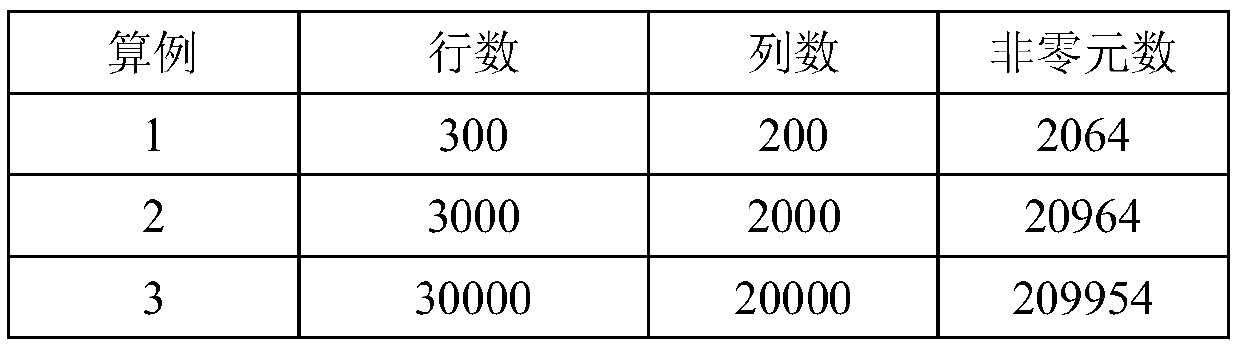
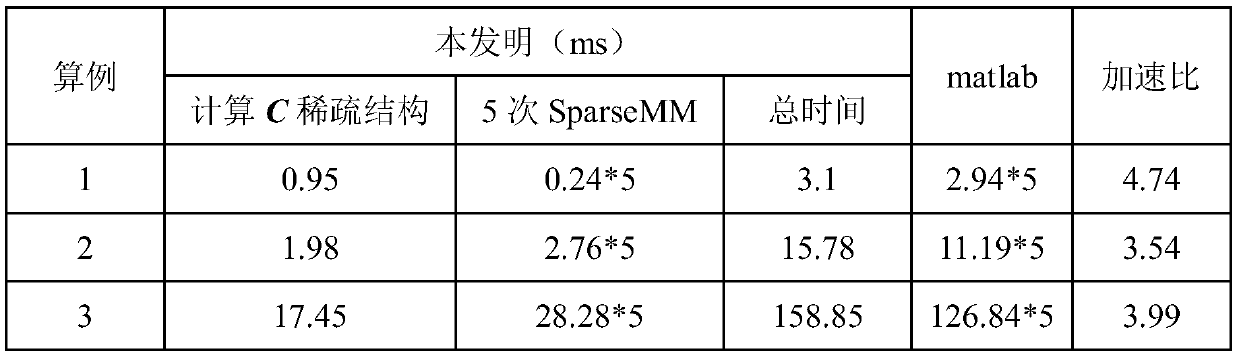
[0046] (1) In the CPU, the large sparse matrix A is stored in the CSR sparse storage format, and the CSR sparse storage format of the sparse matrix A is stored in three vectors, which are row offset A_RowPtr, column number A_ColInd, and value A_Val;
[0047] (2) Call the cuSPARSE function cusparseDcsrgemm2 in the CPU to execute A×A T , obtain the CSR sparse storage format of the sparse matrix C, and generate the COO sparse storage format; the CSR sparse storage format of the sparse matrix C: row offset C_RowPtr, column number C_ColInd and value C_Val, the COO sparse storage of the sparse matrix C The row number in the format is C_RowInd...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More