

Resume extraction method based on deep neural network
A technology of deep neural network and resume, applied in the direction of neural learning method, biological neural network model, neural architecture, etc., can solve the problems of unclear words and words, difficult to learn, rich vocabulary features, etc., to reduce complexity and word segmentation effects, maintenance and extraction with ease
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0021] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the application. It can be understood that the terms "first", "second" and the like used in the present invention can be used to describe various elements herein, but these elements are not limited by these terms. These terms are only used to distinguish one element from another element.
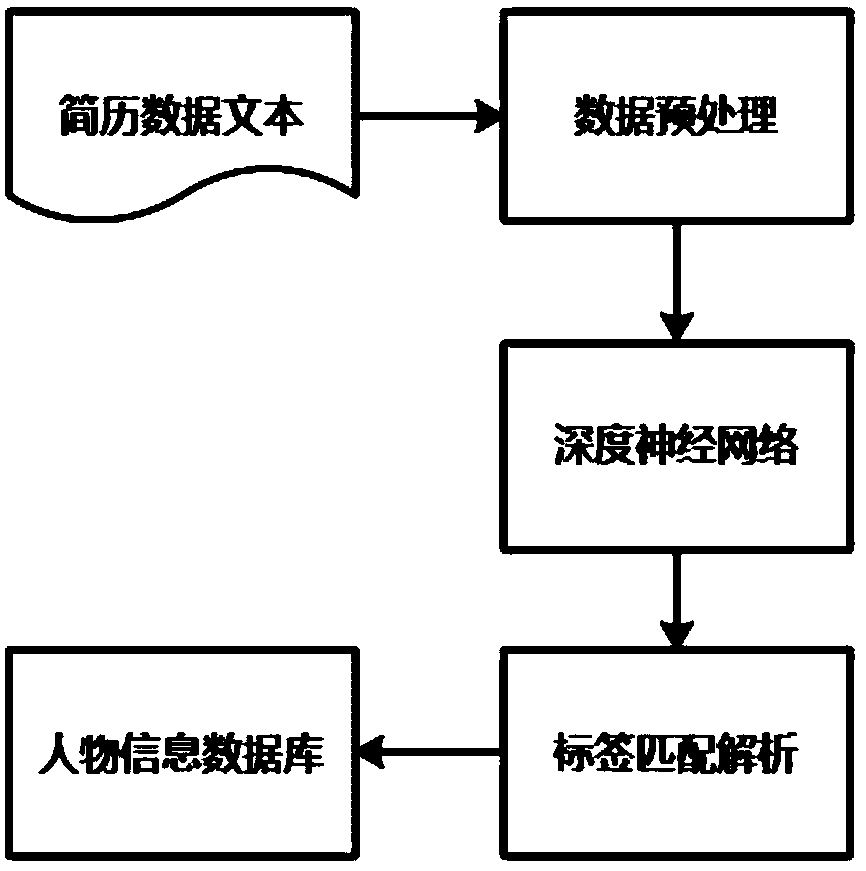
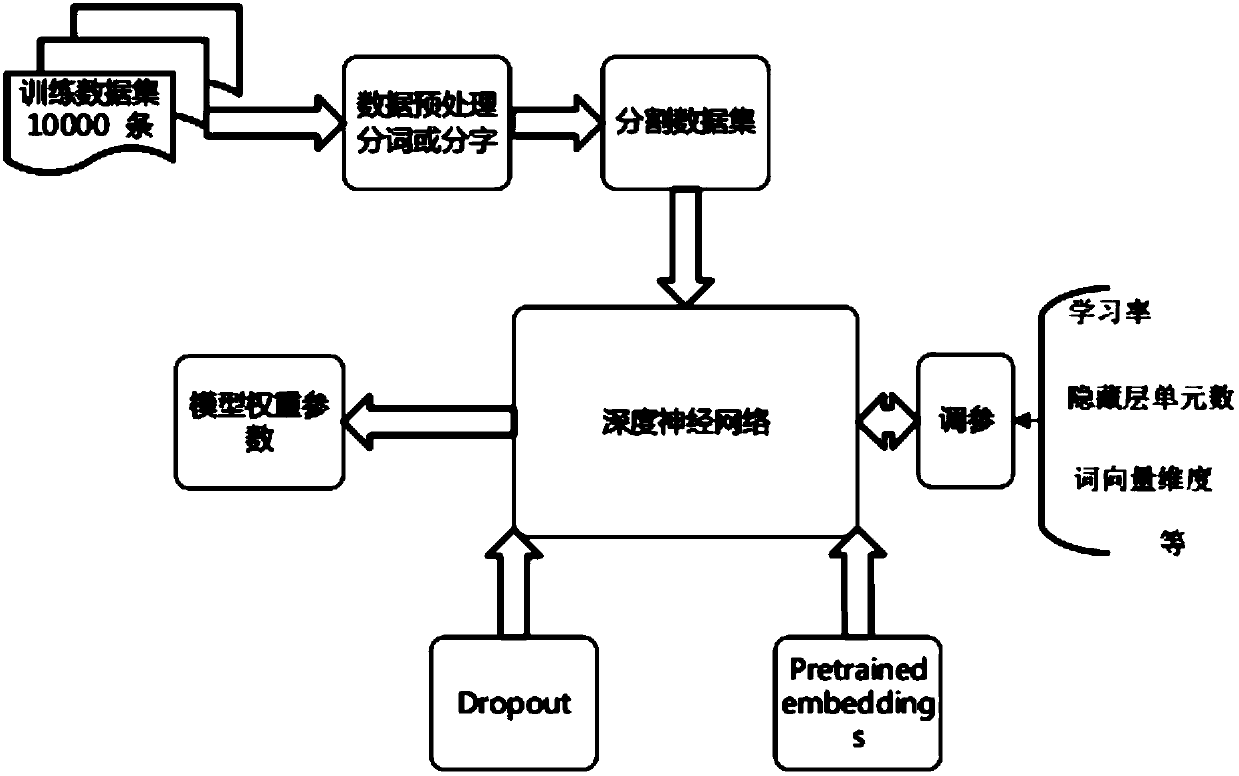
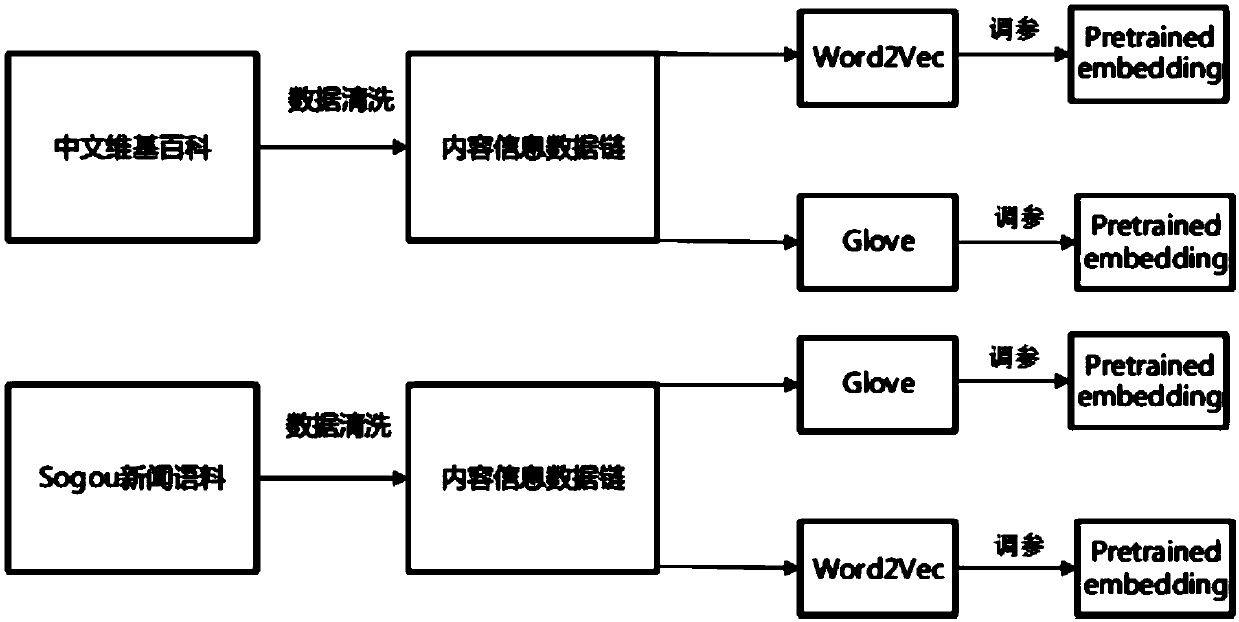
[0022] figure 1 It shows that a method for extracting resumes based on a deep neural network in this embodiment includes the following steps: Step S1, data preprocessing: obtaining resume data text, characterizing the obtained resume data text, and obtaining word vector features and word sequences feature, obtain the word vector data s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More