

A large-scale data group searching method based on time sequence density clustering
A large-scale data and search method technology, applied in the field of information retrieval, can solve problems such as insufficient system scalability and low computing efficiency, and achieve the goals of reducing I/O and cross-domain communication traffic, improving data access efficiency, and improving search efficiency Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0050] The accompanying drawings are for illustrative purposes only and cannot be construed as limiting the patent;
[0051]In order to better illustrate this embodiment, some parts in the drawings will be omitted, enlarged or reduced, and do not represent the size of the actual product;
[0052] For those skilled in the art, it is understandable that some well-known structures and descriptions thereof may be omitted in the drawings.
[0053] The technical solutions of the present invention will be further described below in conjunction with the accompanying drawings and embodiments.
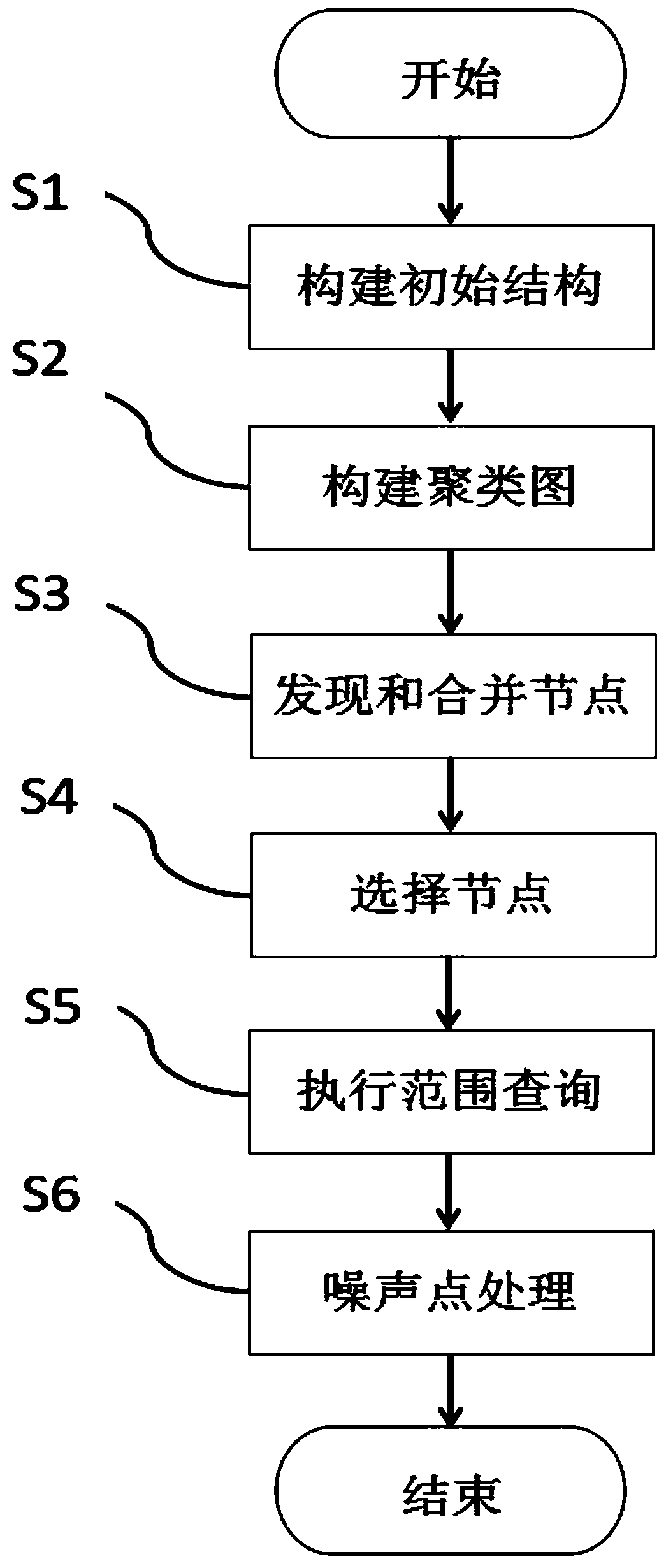
[0054] Such as figure 1 As shown, a large-scale data group search method based on time-series density clustering includes the following steps:
[0055] S1: According to a given node, define three initial states and original clusters of the node; the initial state includes initial state, unexecuted state, and executed state; the original clusters are the executed core points and the executed co...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More