

A multi-layer convolution feature self-adaptive fusion moving target tracking method
A moving target, self-adaptive technology, applied in the field of computer vision, can solve problems such as the inability to comprehensively express the target, the lack of good robustness to appearance changes, and the large difference in tracking performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
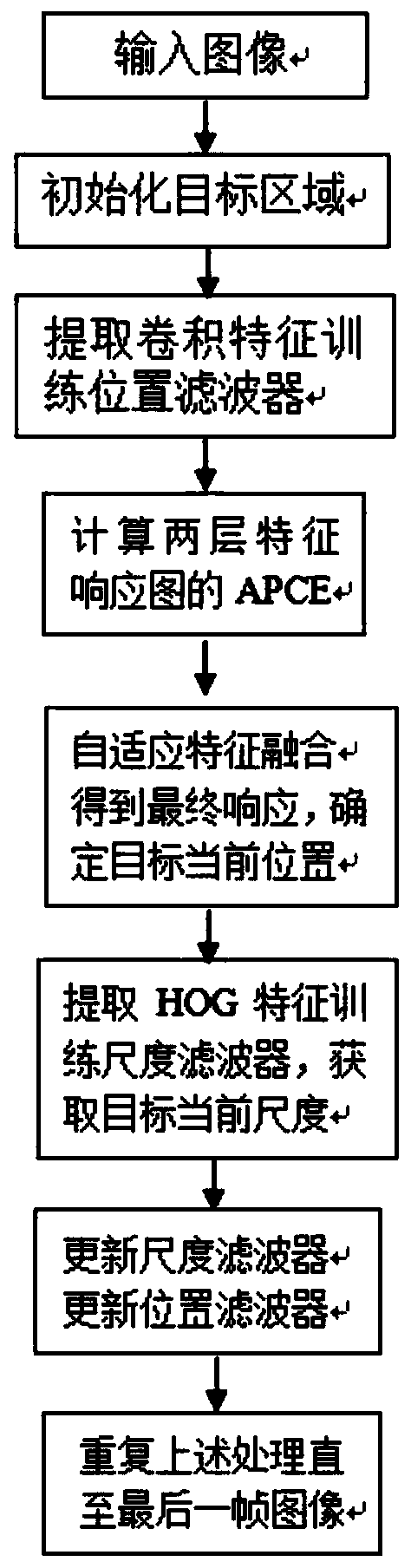
[0057] Example 1: Such as figure 1 As shown, a moving target tracking method with adaptive fusion of multi-layer convolution features, the specific steps of the method are as follows:
[0058] Step1. Initialize the target of the input image and select the target area, first process the first frame of image, take its target position as the center, and collect an image block whose size is twice the size of the target;
[0059] Step2. Use the trained deep network framework VGG-19 to extract the first and fifth layer convolutional features of the target area as training samples, and use the training samples to train the position filter template.
[0060] Step3. Extract two layers of convolutional features from the target area of the second frame of image to obtain two detection samples, and calculate the correlation scores between the two detection samples and the position filter trained in the first frame, that is, the two-layer feature Response graph.
[0061] Step4. Calculate the we...
Embodiment 2
[0066] Embodiment 2: The following describes specific video processing, Step1, according to the first frame of the input image, take the target position as the center, and collect an image block whose size is twice the size of the target, such as figure 2 (a) Shown.
[0067] Step2. Use the VGG-19 network trained on ImageNet to extract the convolutional features of the target. With the forward propagation of CNN, the semantic distinction between different categories of objects is strengthened, and the spatial resolution that can be used to accurately locate the target is also reduced. For example, the input image size is 224×224, and the full convolution feature output size of the fifth pool layer (pool layer) is 7×7, which is 1 / 32 of the input image size. This low spatial resolution is not enough to be accurate To locate the target locally, in order to solve the above problem, we use bilinear interpolation of the convolution features of the first and fifth layers to the sample s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More