

Method and system for generating mixed voice data
一种混合语音、语音数据的技术,应用在语音分析、语音识别、仪器等方向,能够解决人工采集周期长不利研发、音频数据不足、提高研发成本等问题,达到提高收敛速度、提高收集速度、提高性能的效果
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
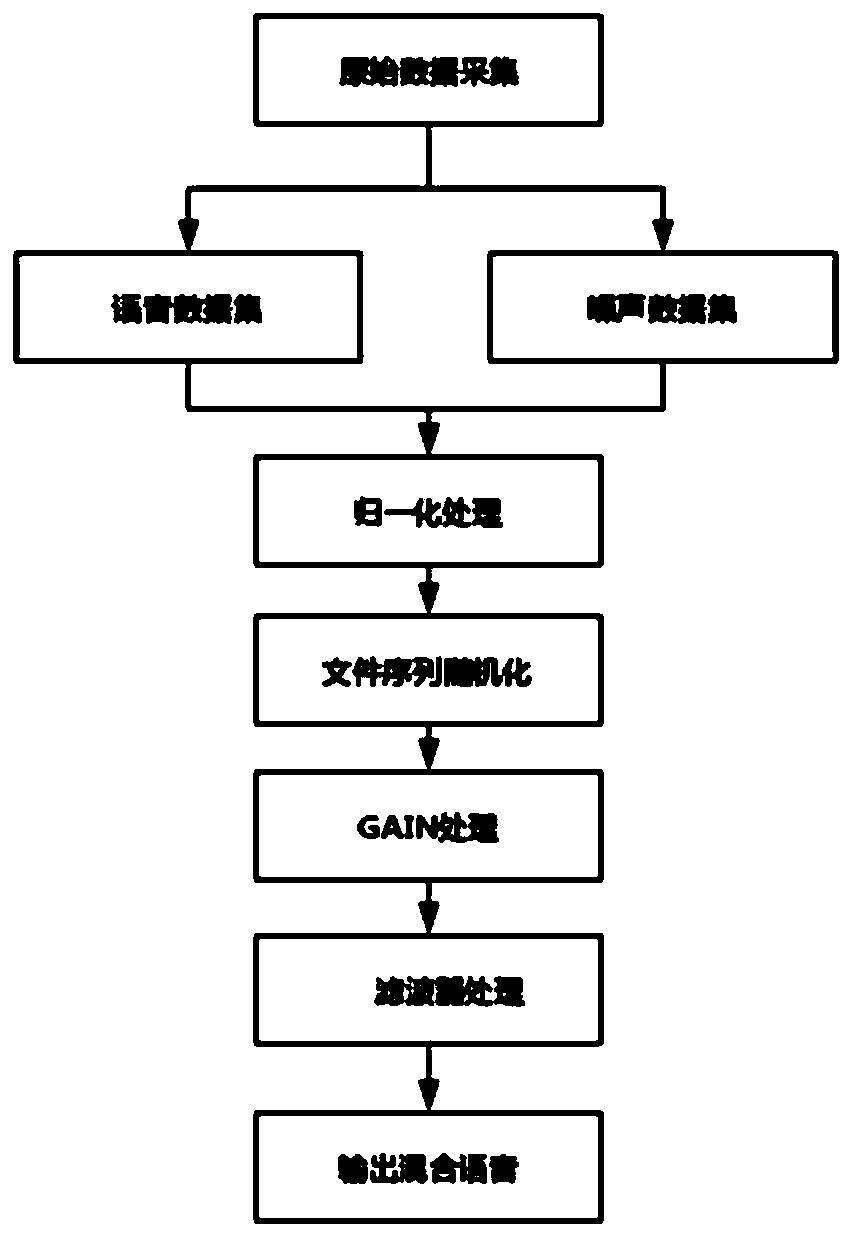
[0032] combine figure 1 As shown, a method for generating mixed voice data of the present invention first collects pure voice and noise, then normalizes the collected voice data, then randomizes the processed data, and then performs GAIN on the data processing, and finally the mixed voice data is obtained through filter processing. Specific steps are as follows:
[0033] Step 1. Raw data collection
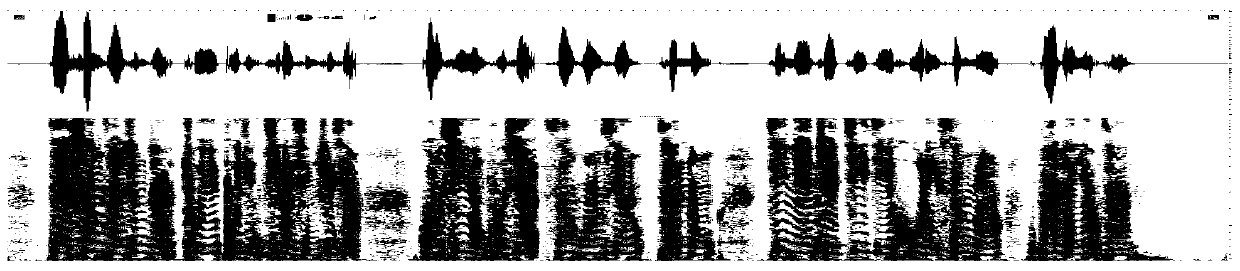
[0034] Gather pure voice data and noise data earlier; Pure voice is to collect in anechoic chamber among the present embodiment, and pure voice is the voice (such as low noise floor, high signal-to-noise ratio) of noise floor. figure 2 shown). Acquisition of noise is carried out in two ways: on-site collection and network download collection. It is worth noting that it is necessary to collect noise in different scenarios, such as noise collection in offices, streets, and stations (such as image 3 shown).
[0035] Step 2, normalization processing
[0036] First convert the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More