

Image-text cross-modal feature unentanglement method based on depth mutual information constraint
A mutual information, cross-modal technology, applied in digital data information retrieval, special data processing applications, instruments, etc., can solve problems such as model performance degradation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

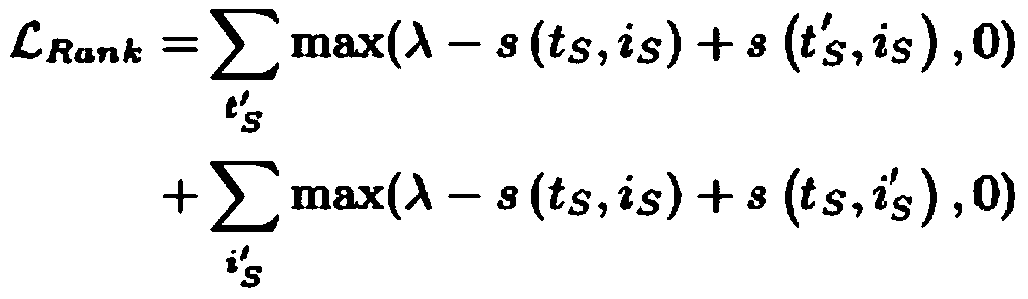
Examples
Embodiment Construction
[0068] The technical solutions of the present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
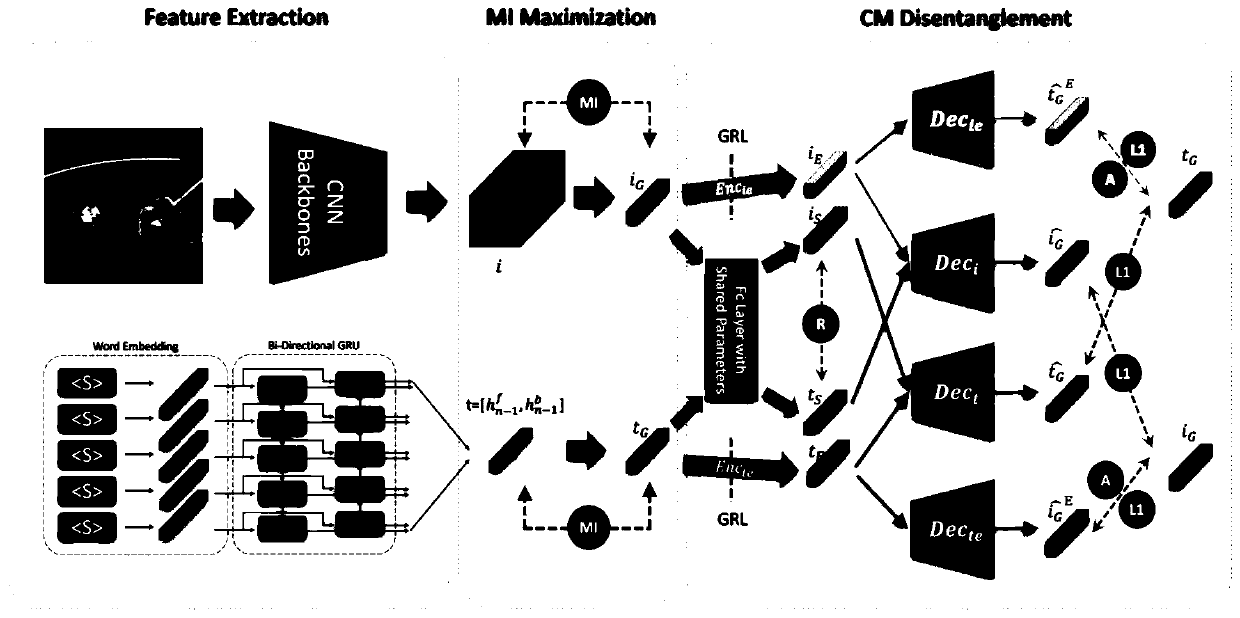
[0069] like figure 1 Shown, the implementation process of the present invention is as follows:
[0070] Step 1: Organize the text and images in the database into a prescribed data pattern.
[0071] The data mode is a sample composed of text, image and category label. In the process of reading, the sample class is first constructed, and the member variables are text data, image data and category label data. Next, the original data is read using Tools read in a specific format.
[0072] For an image file, the amount of corresponding text data can be one sentence, multiple sentences or a description, depending on the specific data set.
[0073] Taking the MSCOCO dataset as an example, each sample consists of an image, a text, and a label, expressed as and stored as a unit in the dataset.
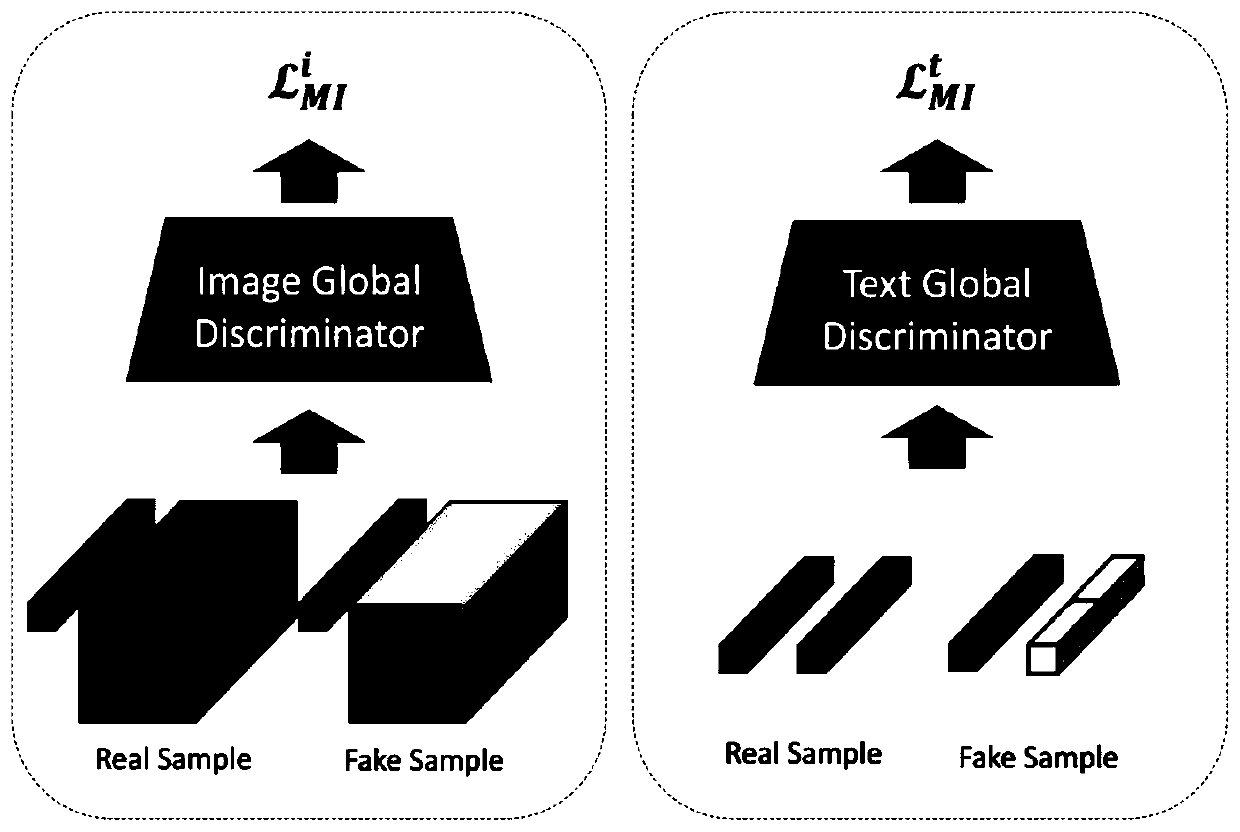
[0074] Step 2: Using deep ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More