

Multi-event video description method based on dynamic attention mechanism
A technology of video description and attention, applied in video data indexing, video data retrieval, metadata video data retrieval, etc., can solve problems such as low accuracy and poor parallelism
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment
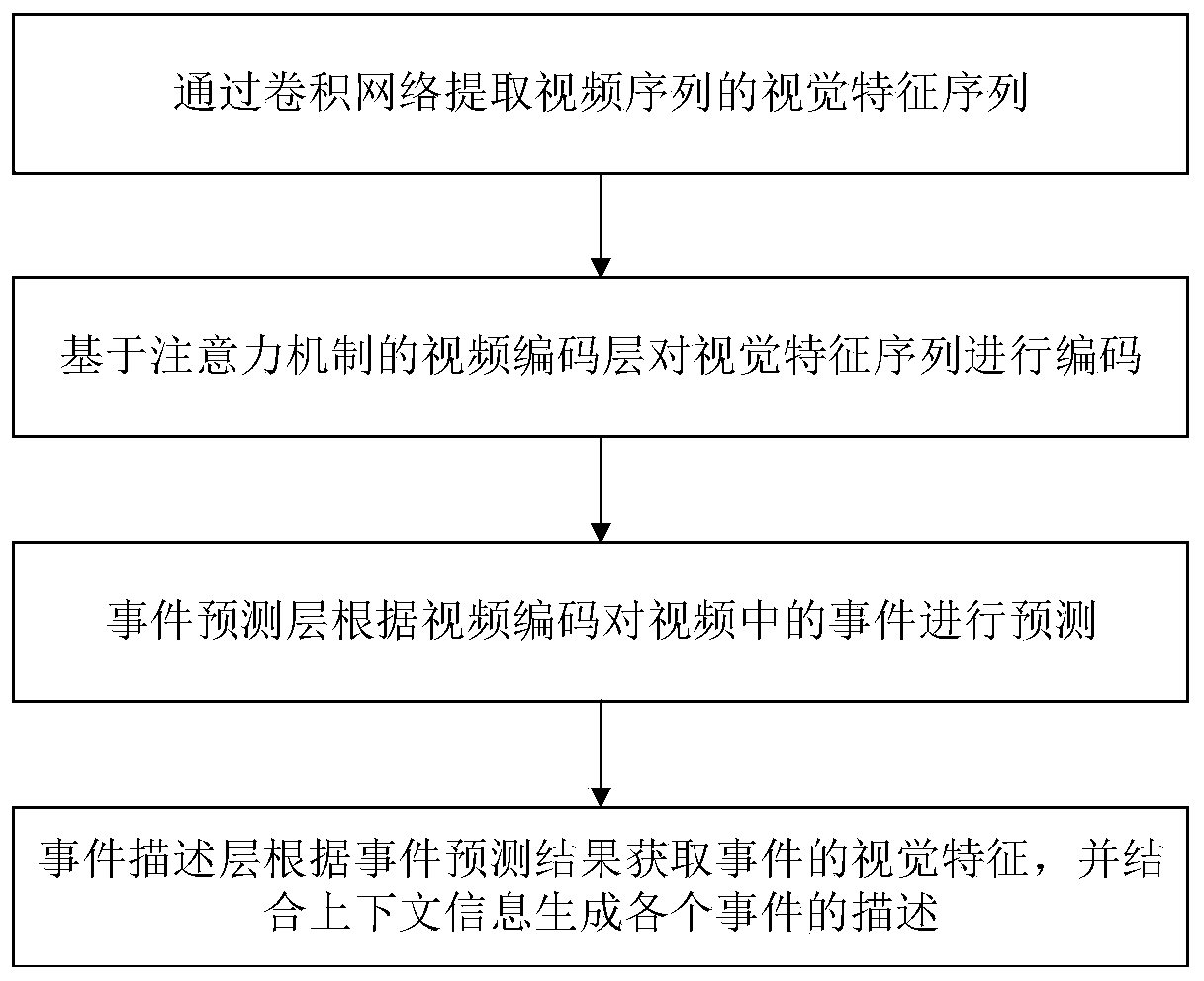
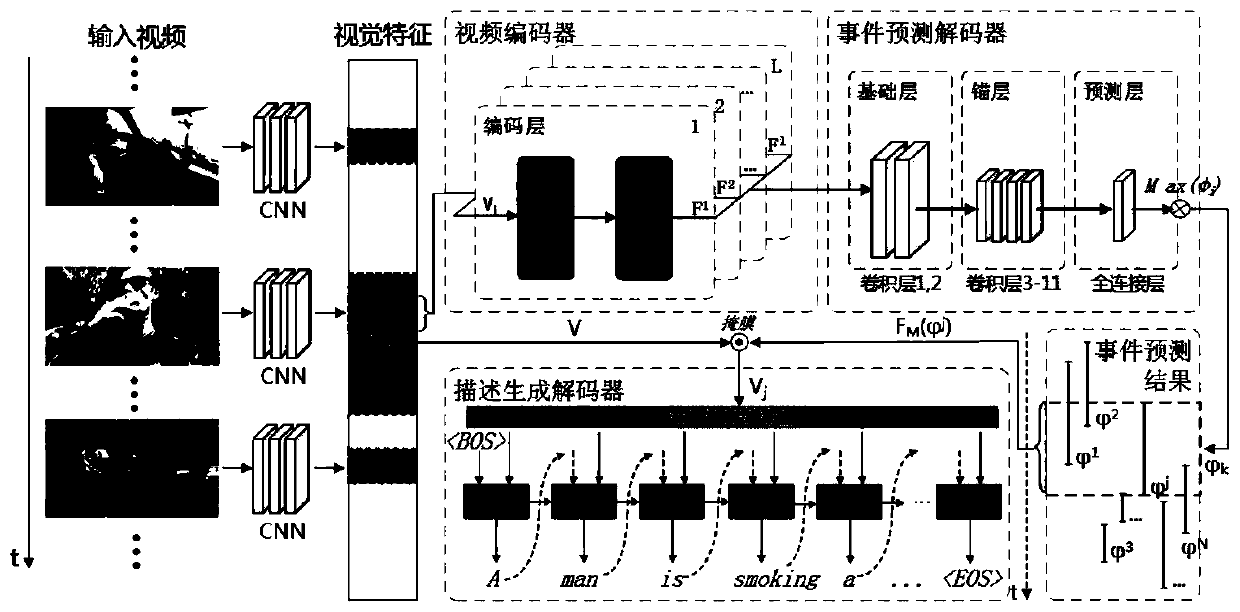
[0060] Such as figure 1 , figure 2 with image 3 As shown, the present invention has designed a kind of multi-event video description method based on dynamic attention mechanism, and this method specifically comprises the following steps:
[0061] Step 1: adopt convolutional neural network (in the present embodiment, adopt 3D-CNN) to extract video sequence X={x 1 ,x 2 ,...x L }’s visual feature V={v 1 ,v 2 ,...v T }.
[0062] For a video sequence of L frames X={x 1 ,x 2 ,...x L }, using a 3DCNN pre-trained on the Sports-1M video dataset to extract features from its video frames. The temporal resolution of the extracted C3D features is δ=16 frames, so the input video stream can be discretized into T=L / δ steps, so the final feature sequence generated is V={v 1 ,v 2 ,...v T }.
[0063] Step 2: Input the visual feature V of the video to the L-layer self-attention video coding layer to obtain the coded representation of the video {F 1 , F 2 ,…...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More