

Incremental clustering algorithm based on community detection
An incremental clustering and community technology, applied in the field of text clustering, can solve the problems of high computing time complexity, lack of ability to distinguish hot events from continuous reporting events, and large time overhead, so as to reduce computing time overhead Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

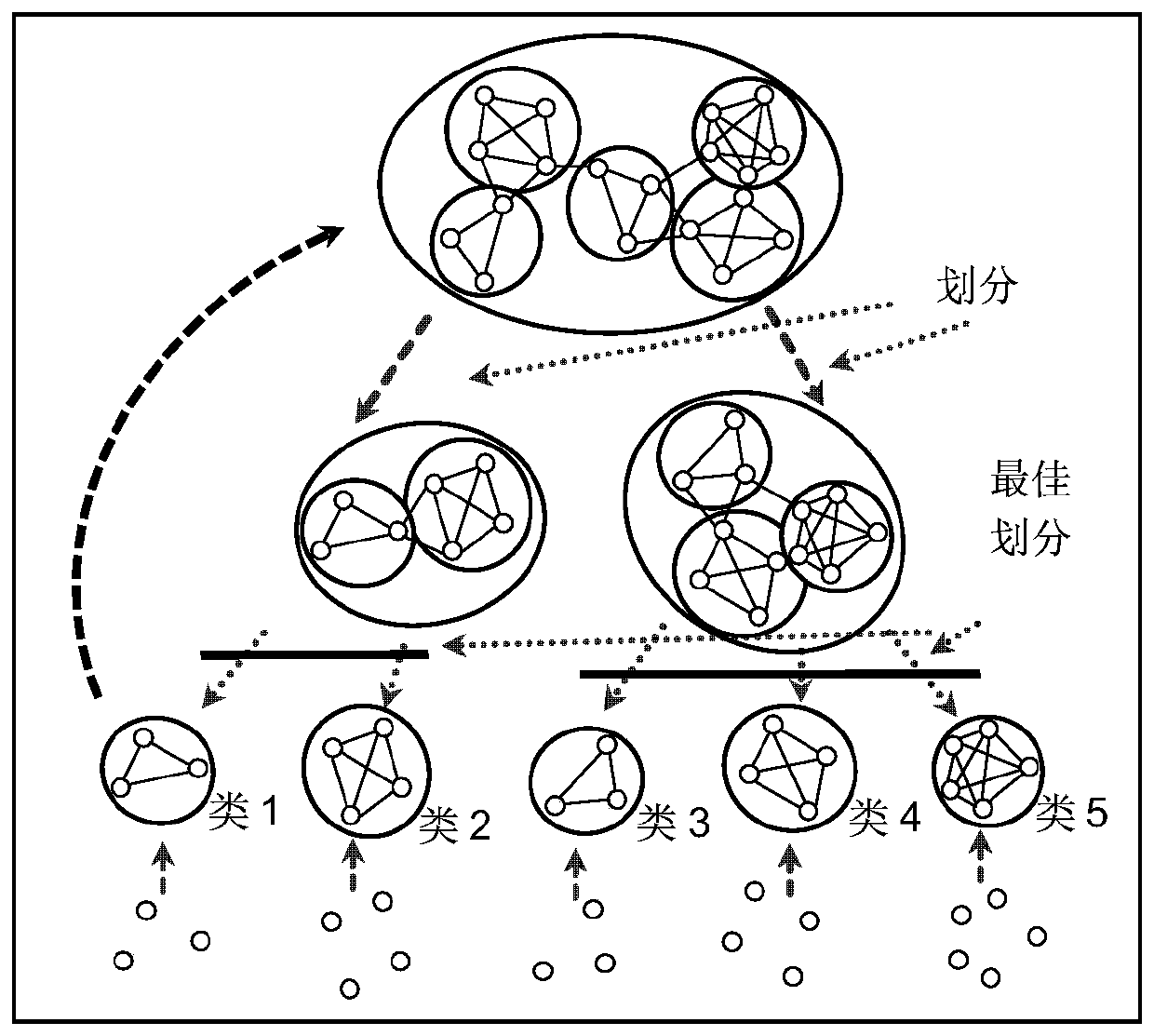
Examples
Embodiment 1
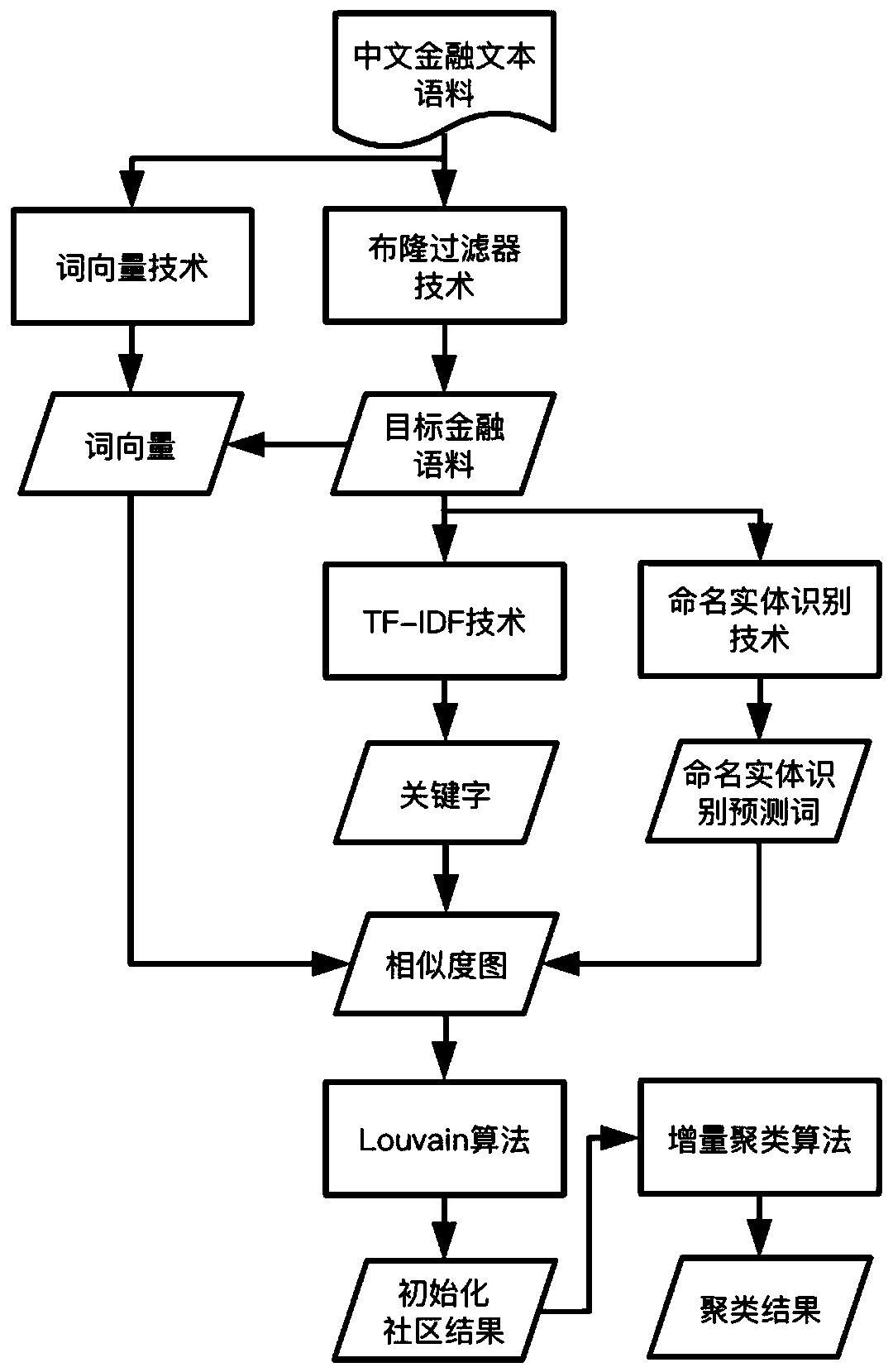
[0041] See attached figure 1 , carry out the incremental clustering algorithm based on community detection according to the following steps:
[0042] S1: Perform word vector pre-training on the full amount of Chinese financial text corpus to generate a word vector model. The full amount of Chinese financial text corpus is composed of regular crawlers crawling major financial portal websites; the word vector model is pre-trained from the full amount of Chinese financial text corpus, and its training method is fasttext.
[0043] S2: Use Bloom filter technology on the full amount of Chinese financial text corpus, perform text de-duplication screening, and obtain the target financial corpus after text preprocessing. The technology used in the text deduplication adopts BloomFilter, and the text preprocessing includes removing stop words and thualc word segmentation.
[0044] S3: Use TF-IDF technology for the target financial corpus to obtain the Top-k keywords of each corpus docu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More