

Video content description method based on text auto-encoder
A self-encoder, video content technology, applied in the computer field, can solve the problems of ignoring the guiding role of updating, wasting computing resources, and inability to update weights accurately.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

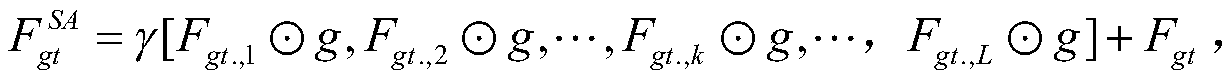
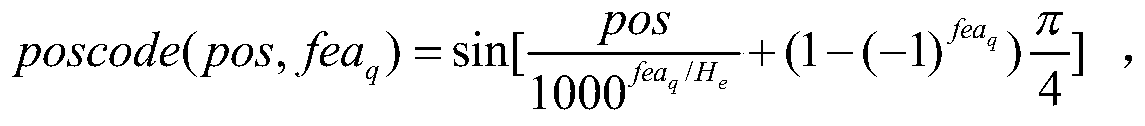
Examples
Embodiment Construction
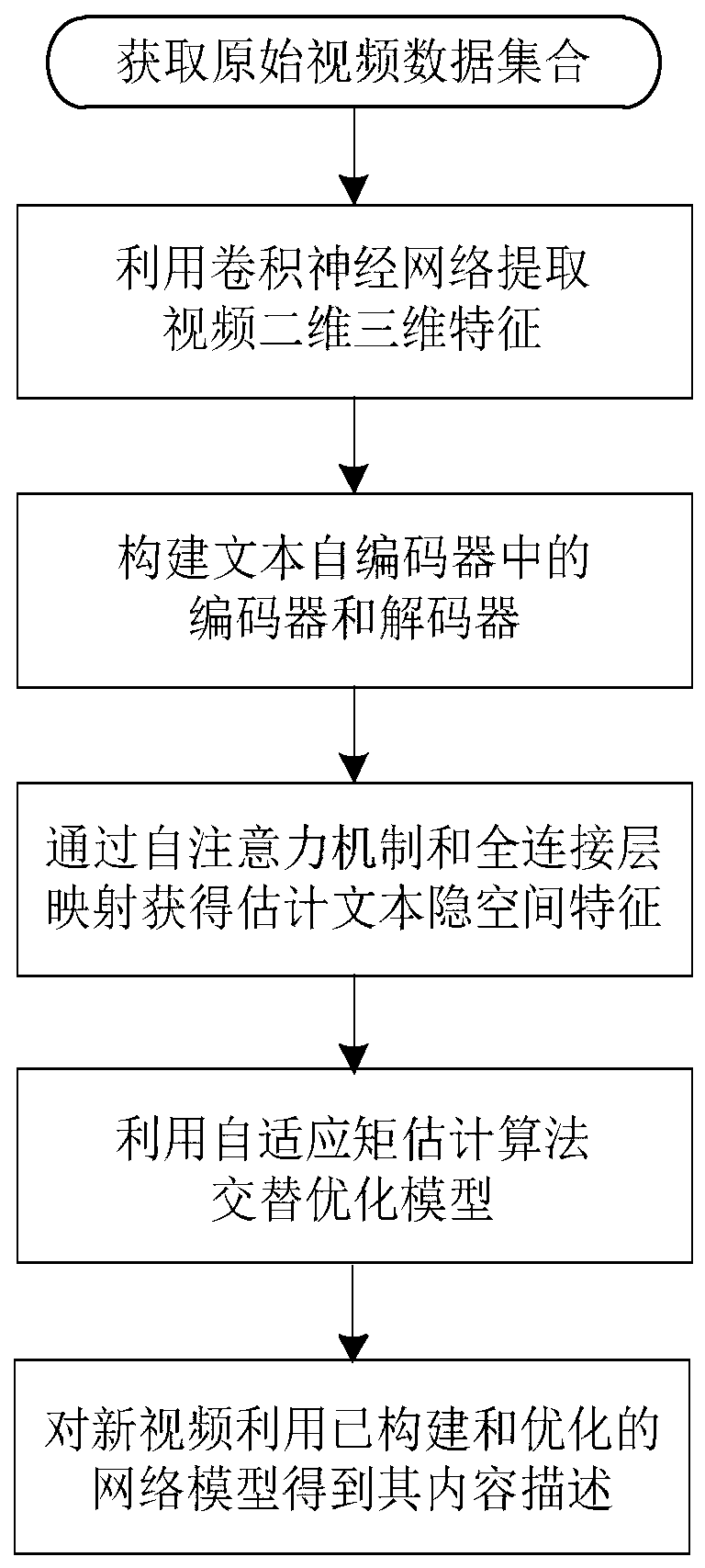
[0049] The present invention will be further described below in conjunction with accompanying drawing.
[0050] A video content description method based on a text autoencoder, which focuses on building a text autoencoder to learn the corresponding latent space features and reconstructing the text using a multi-head attention residual network, which can generate a text description that is more in line with the real content of the video, fully Mining potential relationships between video content semantics and video textual descriptions. The self-attention network composed of self-attention modules and fully connected maps can effectively capture the long-term action sequence features in videos and improve the computational efficiency of the model, while enhancing the ability of neural networks to fit data (that is, using neural networks to fit text Hidden space feature matrix) to improve the quality of video content description; the use of multi-head attention residual netwo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More