

Method and device for generating graph data based on relational database data
A data generation and graph data technology, applied in the database field, can solve the problems of adjacency matrix consumption of large space, space waste, etc., to achieve the effect of reducing duplication, reducing space utilization, and convenient query
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
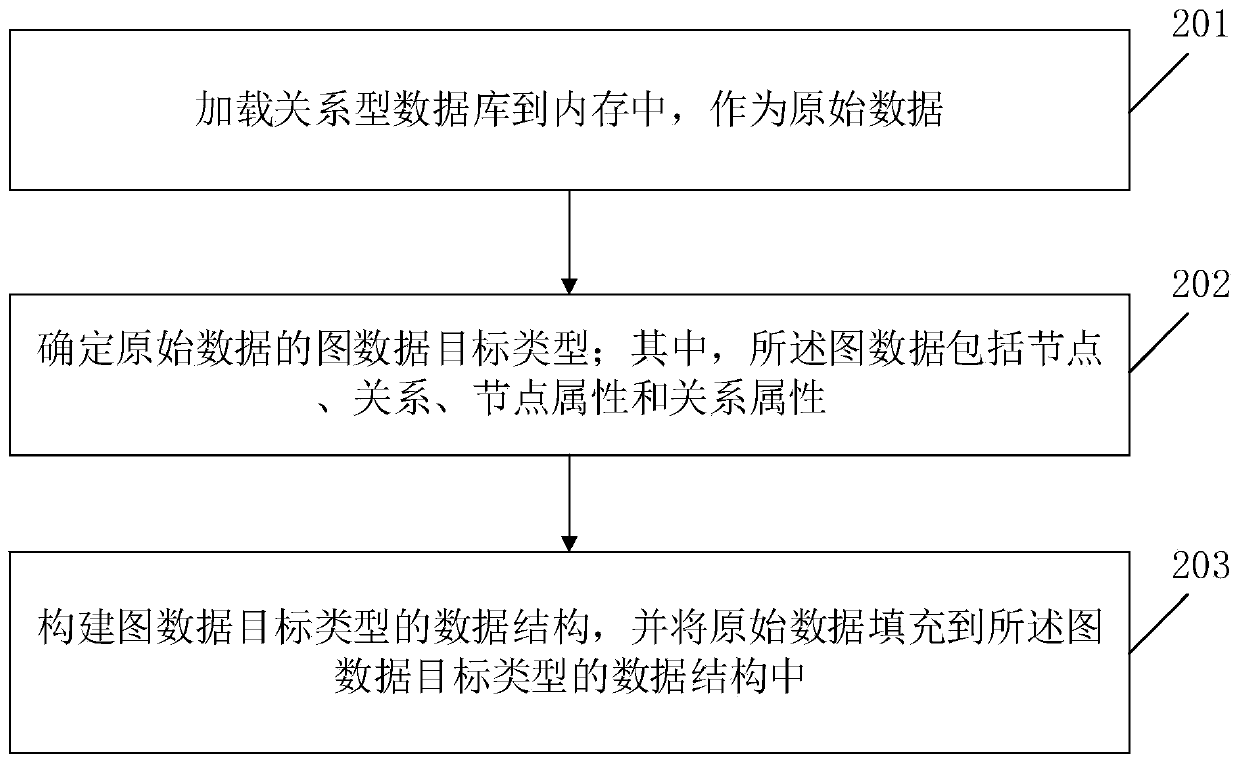
[0051] Embodiment 1 of the present invention provides a method for generating graph data based on relational database data, such as figure 1 shown, including:
[0052] In step 201, a relational database is loaded into memory as original data.
[0053] Wherein, the traditional relational database includes: one or more of an open source relational database MySQL, an open source relational database Maria DB, a Microsoft SQL Server relational database, and an Oracle relational database.
[0054] In the embodiment of the present invention, in order to improve the determination of the target type of the graph data and the generation of the corresponding data structure in the subsequent steps, preferably, when loading the relational database, for the tables of each attribute, select a specified time period according to the database log Load the relational data that is generated within and covers each relational data table. In this way, it can not only ensure the screening of data r...
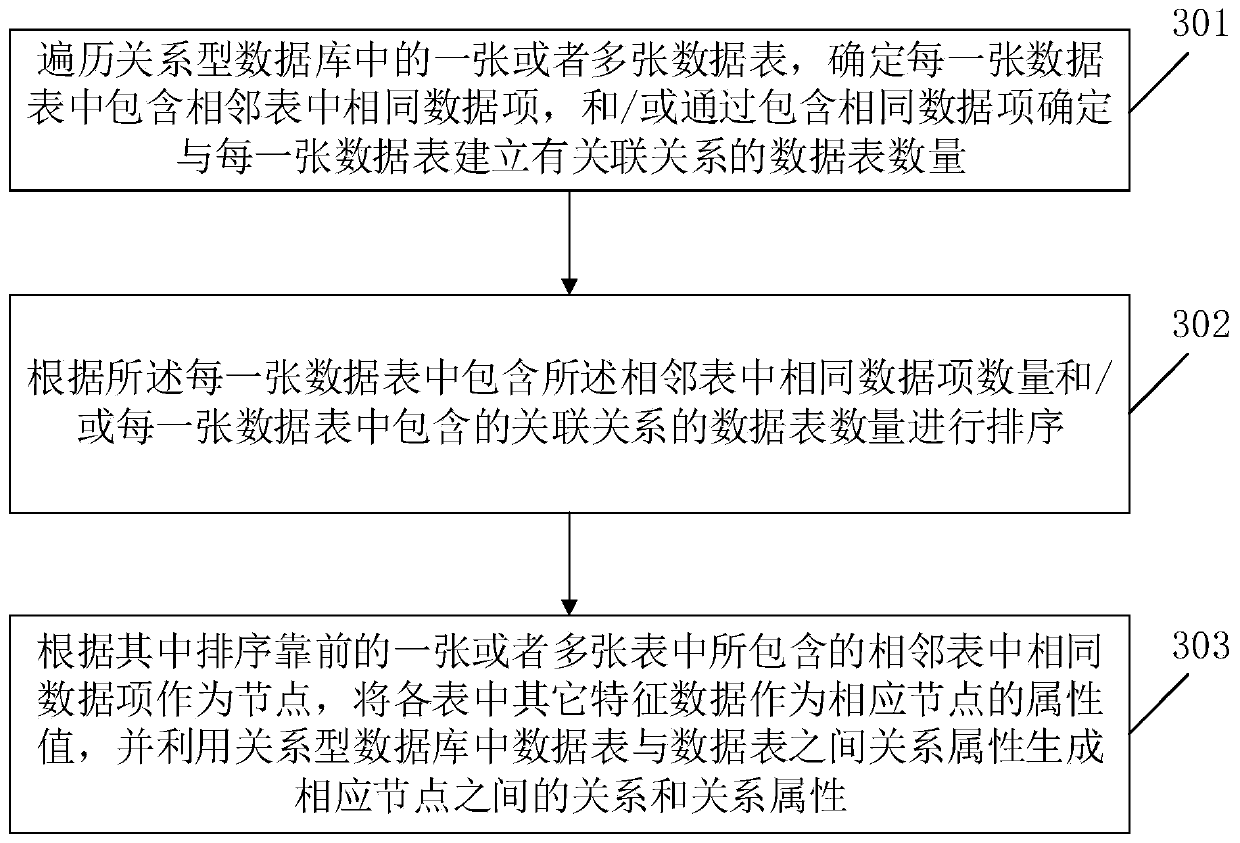
Embodiment 2
[0110] An embodiment of the present invention provides a method for converting student information, teacher teaching subject information, and student achievement information into graph data.
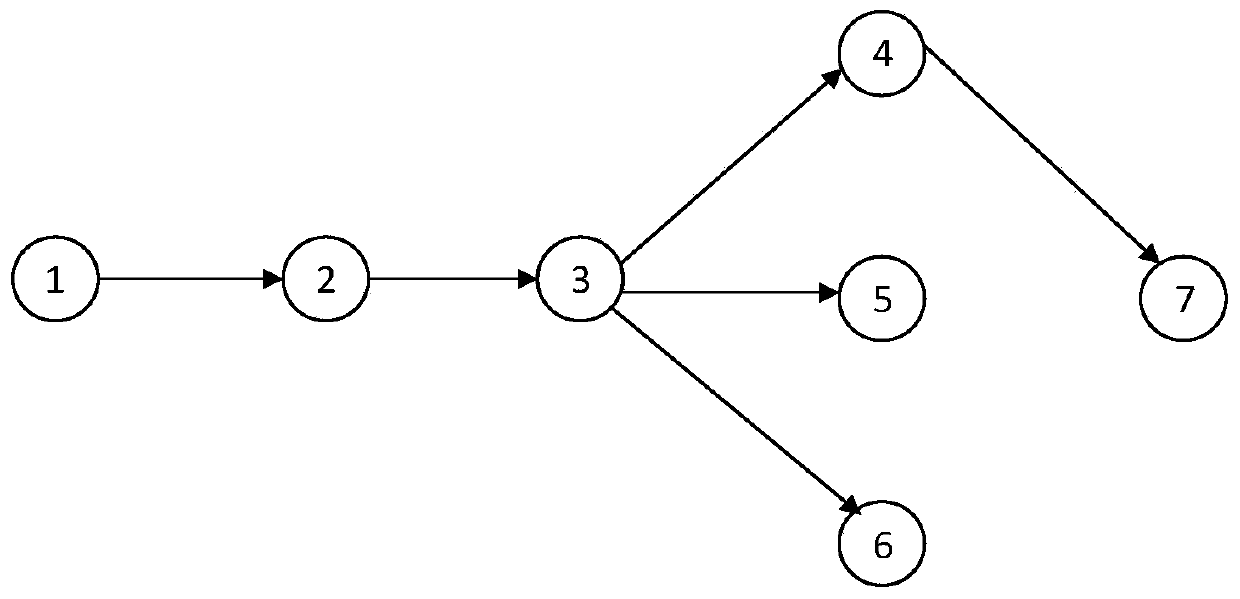
[0111] Step S1, obtaining student information, teacher teaching subject information, and student achievement information data in the relational database. The corresponding table data such as Figure 5-Figure 7 shown.
[0112] Step S2, determine the graph data type of the relational database information, in this example, determine the student information as the node type in the graph data, determine the teacher teaching information as the graph data node type, and determine the student achievement information as the graph data relationship type.
[0113] Step S3, constructing a graph data object type data structure.
[0114] The (Java) classes used by graph data nodes are defined as follows:
[0115] classNode
[0116] {
[0117] int id;
[0118] int nextRelationShipId;
[0119] int...
Embodiment 3
[0150] like Figure 10 As shown in FIG. 1 , it is a schematic diagram of the structure of the content recommendation device based on the human body state according to the embodiment of the present invention. The device for recommending content based on human body state in this embodiment includes one or more processors 21 and memory 22 . in, Figure 10A processor 21 is taken as an example.
[0151] Processor 21 and memory 22 can be connected by bus or other means, Figure 10 Take connection via bus as an example.
[0152] The memory 22, as a non-volatile computer-readable storage medium, can be used to store non-volatile software programs and non-volatile computer-executable programs, such as the method for generating graph data based on relational database data in Embodiment 1 . The processor 21 executes the method for generating graph data based on the relational database data by running the non-volatile software programs and instructions stored in the memory 22 .
[0...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More