

Multi-speaker Speech Separation Method Based on Voiceprint Features and Generative Adversarial Learning
A voiceprint feature and voice separation technology, applied in neural learning methods, voice analysis, biological neural network models, etc., can solve problems such as robustness, high complexity of deep models, poor voice separation effect, etc., to achieve tracking” Identify and improve the effect of invariance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 example
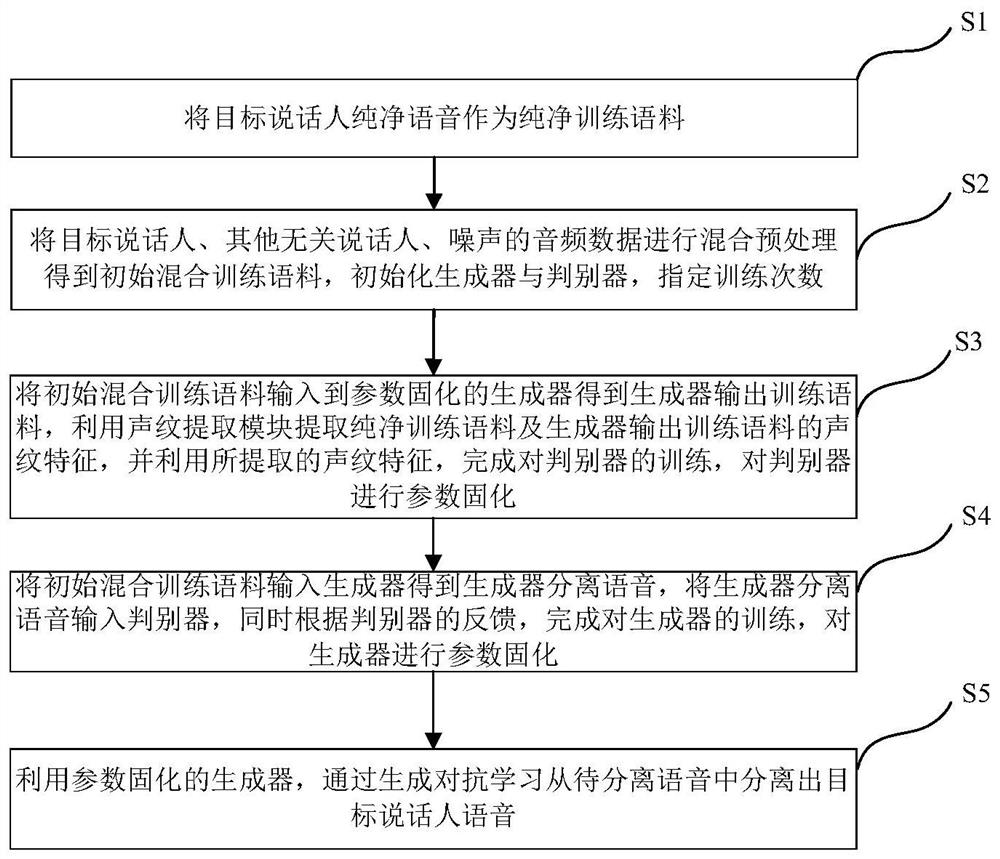
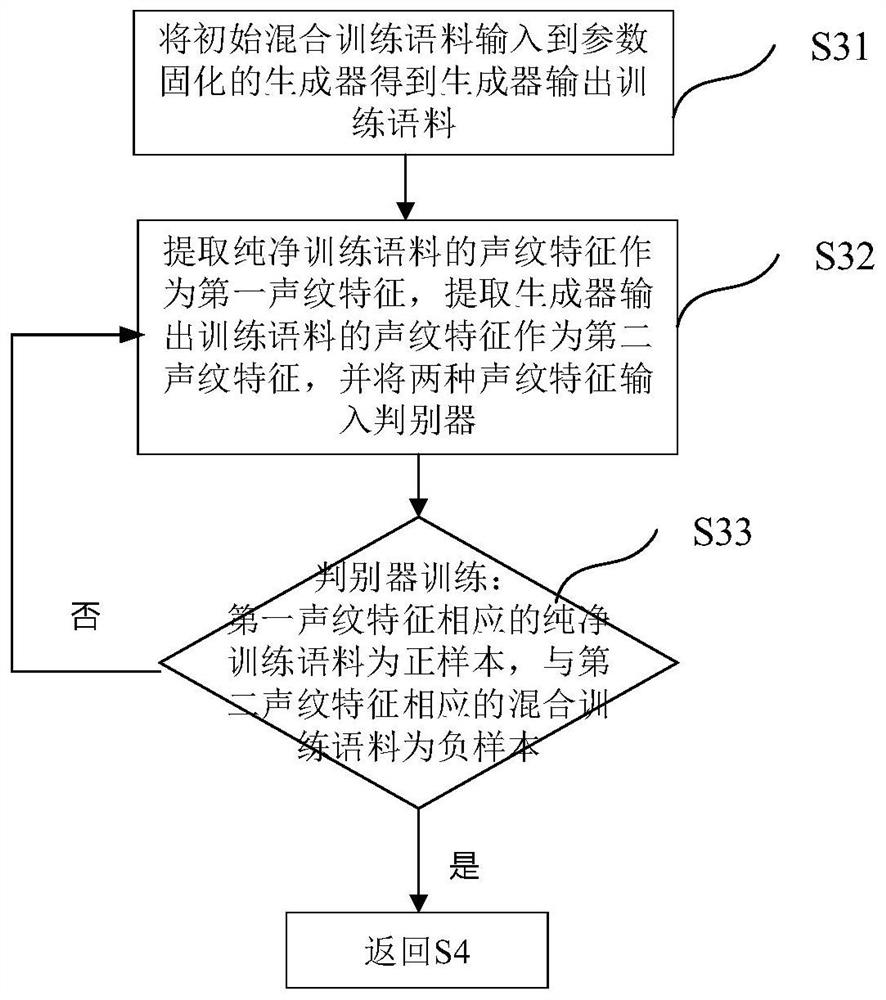
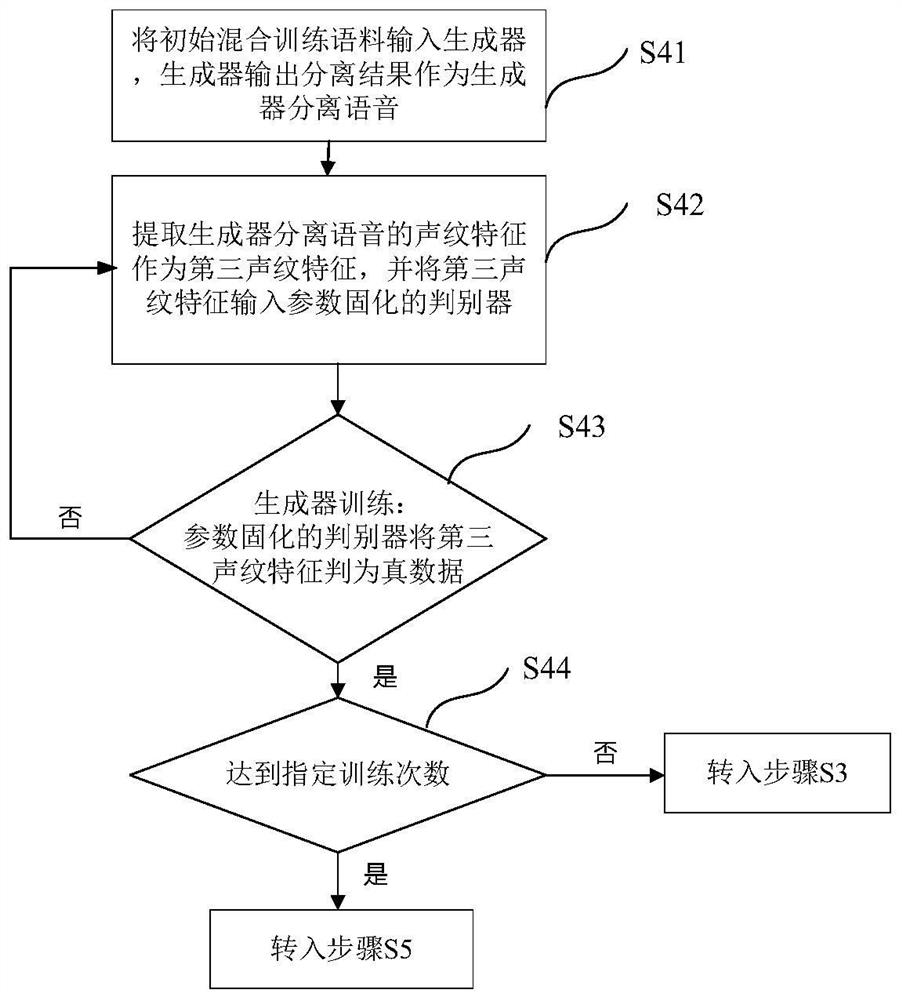
[0057] This embodiment proposes a speech separation method based on voiceprint features and generative adversarial learning for multi-speaker speech separation in speech recognition. The multi-speaker mentioned in this embodiment refers to a scene where multiple people speak at the same time, and the speech separation to be performed is to extract the speech of the target speaker. Preferably, the scene where multiple people speak at the same time includes: in the intelligent conference instant inter-interpretation system, removing the voice or background sound of unrelated people; suppressing the voice of the non-target speaker on the device side before transmitting the voice signal, Improve the voice quality and intelligibility of conference communication; and the development of application in smart cities will be in the speaker signal collection in voice interaction in smart home, unmanned driving, security monitoring and other fields.
[0058] figure 1 Shown is a schematic...
no. 2 example
[0099] This embodiment provides a multi-speaker speech separation system based on voiceprint features and generative adversarial learning. Figure 4 Shown is a schematic structural diagram of the multi-speaker speech separation system based on voiceprint features and generative adversarial learning. Such as Figure 4 As shown, the multi-speaker speech separation system includes: an anchor sample collection module, a hybrid preprocessing module, a voiceprint feature extraction module, at least one discriminator, and at least one generator.
[0100] Wherein, the anchor sample collection module is connected with the hybrid preprocessing module and the voiceprint feature extraction module, and is used to use the pure speech of the target speaker (ie, the anchor sample) as a pure training corpus, and provide the pure training corpus to the Hybrid preprocessing module and voiceprint feature extraction module.
[0101] The mixed preprocessing module is connected with the voiceprint...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More