Big data text clustering method and system based on parallel improved K-means algorithm
A k-means algorithm and text clustering technology, applied in the field of text clustering, can solve the problems of low accuracy and efficiency of the algorithm, no optimization or partial optimization of the K-means algorithm, etc., and achieve great performance advantages and accuracy Improve and improve the effect of accuracy and efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
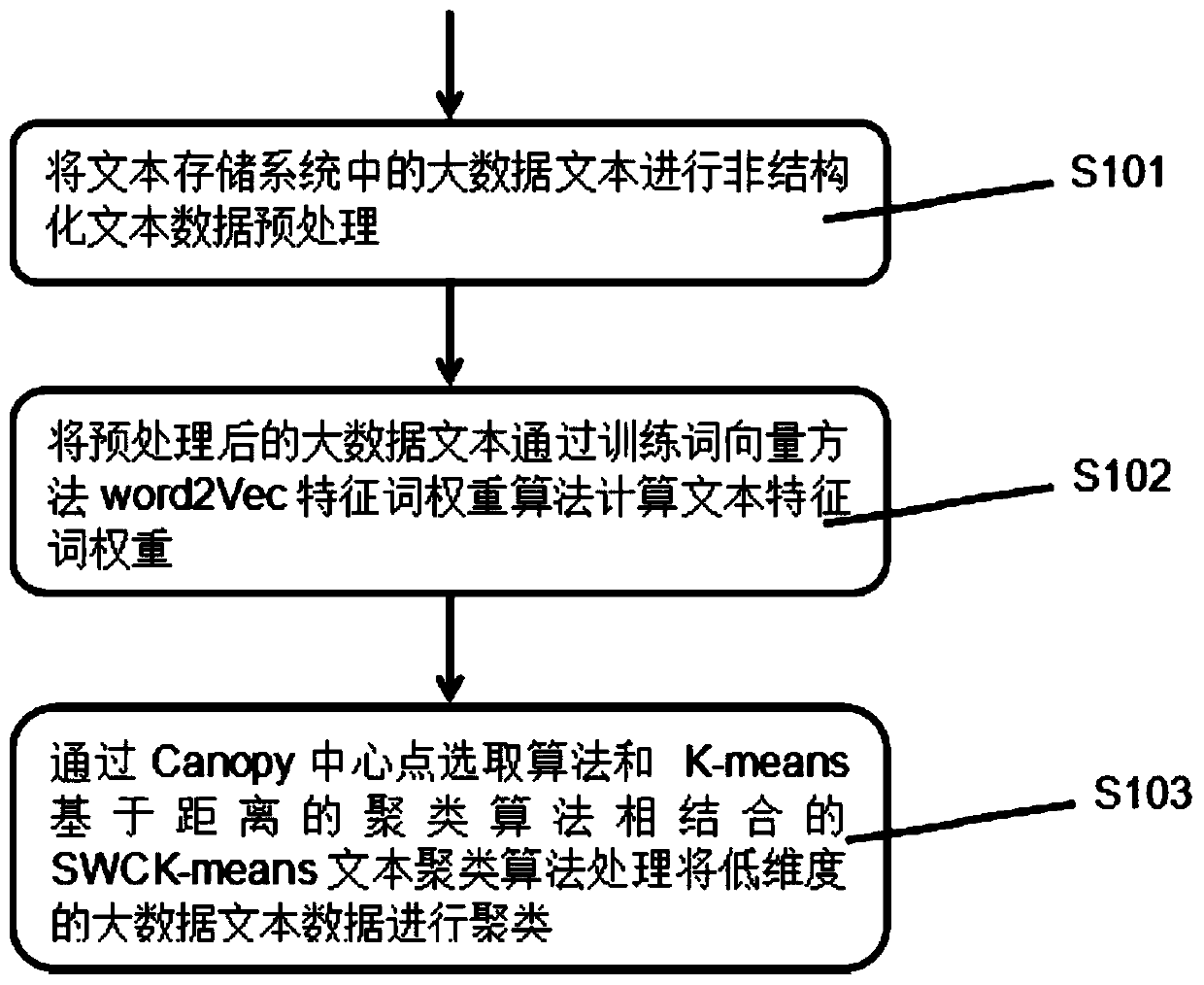
[0056] Embodiment one: if figure 1 As shown, the large data text clustering method based on the parallel improved K-means algorithm includes:
[0057] Perform unstructured text data preprocessing S101 on the large data text in the text storage system;
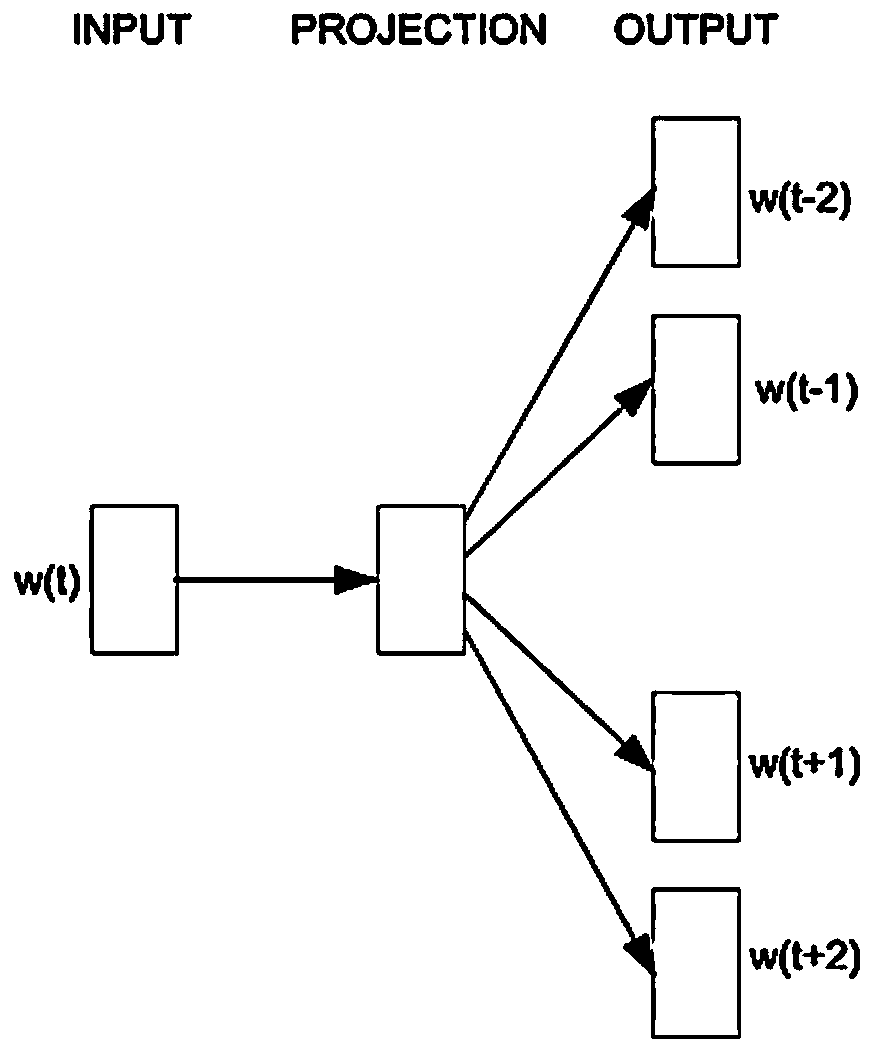
[0058] The preprocessed big data text is used to calculate the text feature word weight S102 through the word2Vec feature word weight algorithm of the training word vector method;
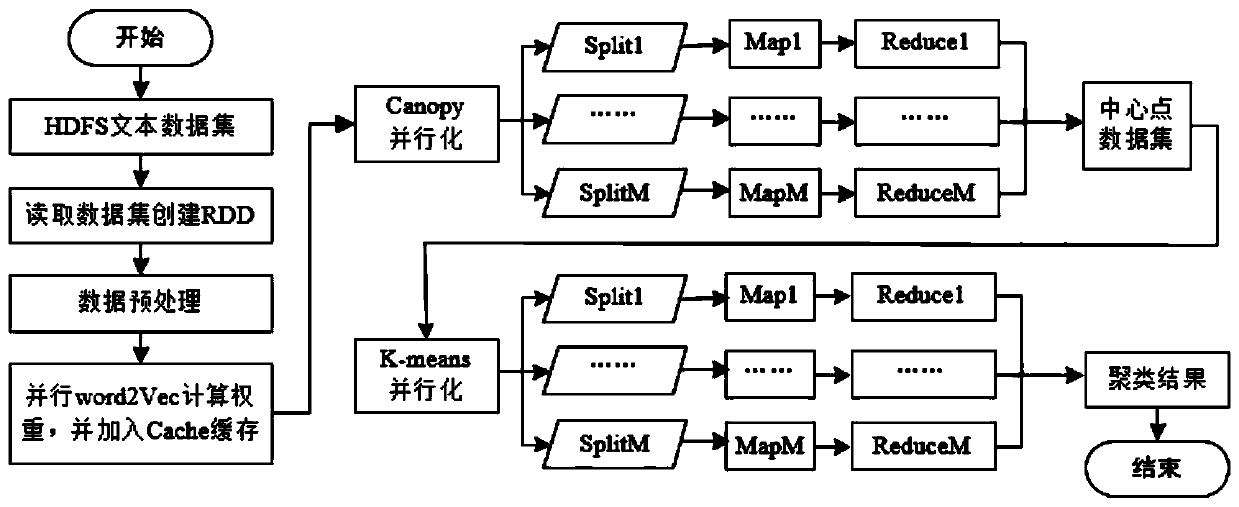
[0059] Through the SWCK-means text clustering algorithm combining the Canopy center point selection algorithm and the K-means distance-based clustering algorithm, the low-dimensional big data text data is clustered S103.
[0060] The SWCK-means text clustering algorithm processing combined with the Canopy center point selection algorithm and the K-means distance-based clustering algorithm includes:
[0061] Parallel Canopy clustering of large text data with text feature word weights to obtain the cluster center point, using the cluster center poin...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com