

A Parameter Adaptive Backstepping Control Method for Underwater Robots Based on Double BP Neural Network Q-Learning Technology
A BP neural network, underwater robot technology, applied in the direction of adaptive control, general control system, control/adjustment system, etc., can solve the problems of low learning efficiency and difficult real-time online adjustment of parameters, so as to improve adaptability and reduce training The number of times, the effect of good control effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
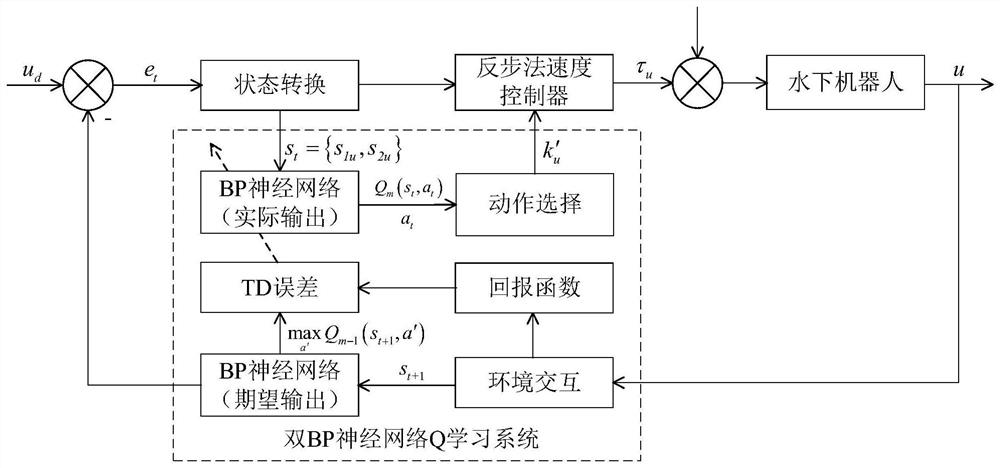
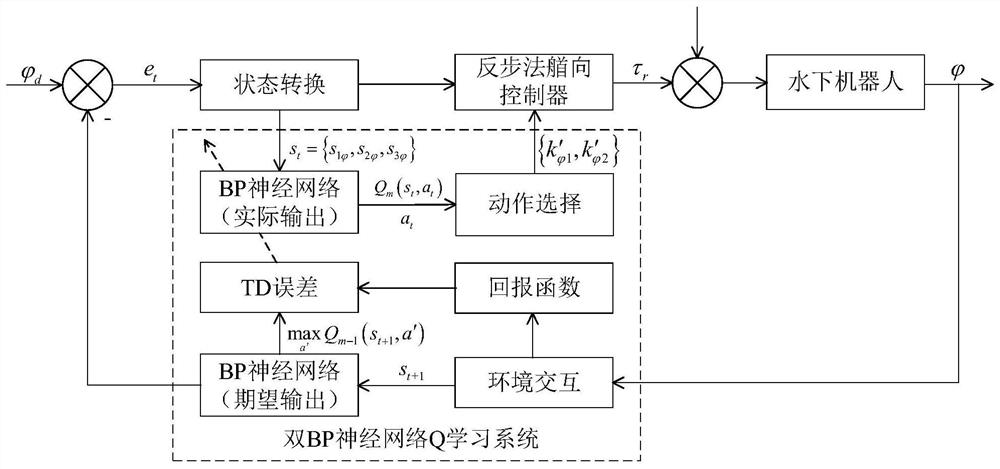
[0052] Specific embodiment one: a kind of underwater robot parameter self-adaptive backstepping control method based on double BP neural network Q learning technology described in the present embodiment, described method specifically comprises the following steps:
[0053] Step 1. Design the speed control system and the heading control system of the underwater robot respectively based on the backstepping method, and then determine the control law of the speed control system and the control law of the heading control system according to the designed speed control system and heading control system;
[0054] The speed control system of the underwater robot is shown in formula (1):
[0055]
[0056] Among them, m is the mass of the underwater robot, and x u|u| are dimensionless hydrodynamic parameters, u is the longitudinal velocity of the underwater robot, |u| is the absolute value of u, is the longitudinal acceleration of the underwater robot, τ u is the longitudinal thr...
specific Embodiment approach 2
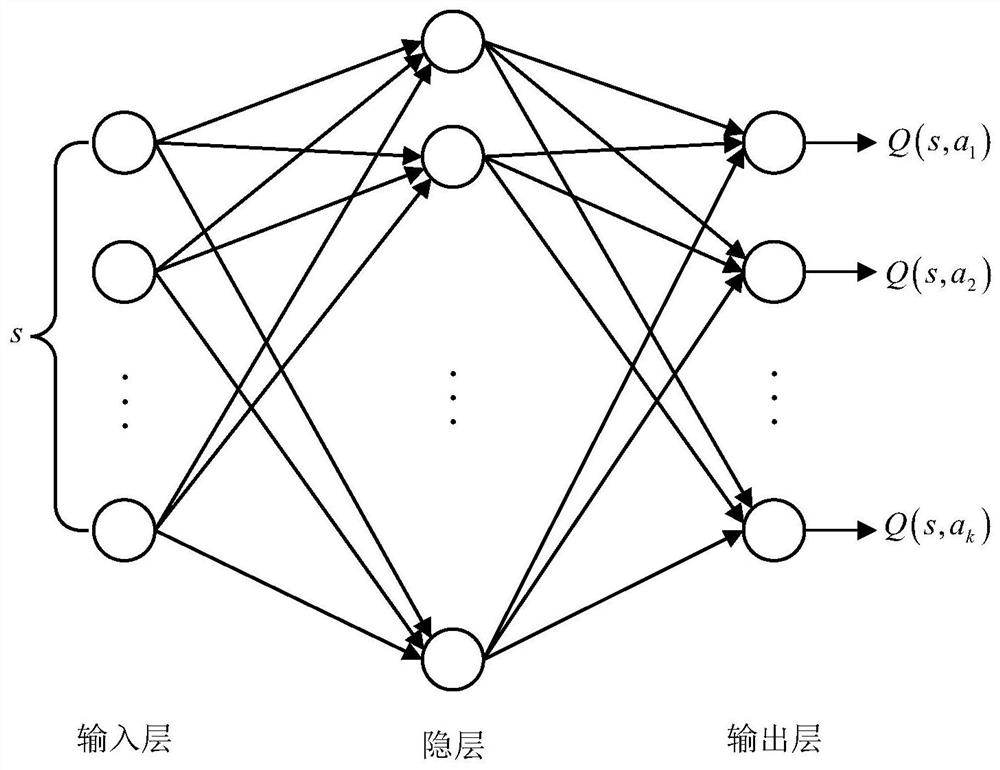
[0110] Specific embodiment 2: The difference between this embodiment and specific embodiment 1 is that in the second step, the output is the action value set k′ u , and then use the ε greedy strategy from the action value set k′ u Select the optimal action value corresponding to the current state vector; the specific process is:
[0111] Define the action space that needs to be divided as k′ u0 , k′ u0 ∈[-1, 2], put k′ u0 Every 0.2 is divided into 16 action values, and 16 action values form the action value set k′ u ; Then use the ε greedy strategy from the action value set k′ u Select the optimal action value k″ corresponding to the current state vector u .
[0112] action value set k′ u={-1,-0.8,-0.6,-0.4,-0.2,...,1.4,1.6,1.8,2}.
[0113] The adaptive backstepping speed controller and heading controller based on reinforcement learning, its action selection method is ε greedy strategy, ε∈(0,1), when ε=0 represents pure exploration, when ε=1 represents pure explorati...
specific Embodiment approach 3
[0114] Specific embodiment three: the difference between this embodiment and specific embodiment one is: in the step three, the first current BP neural network is in the current state S t Choose the optimal action a t And the reward value obtained after execution is r t+1 (S t+1 , a), r t+1 (S t+1 , the expression of a) is:
[0115] r t+1 (S t+1 ,a)=c 1 ·s 1u 2 +c 2 ·s 2u 2 (13)
[0116] Among them, c 1 and c 2 All are positive numbers greater than zero.
[0117] The reward and punishment function has a relatively clear goal, which is used to evaluate the performance of the controller. Usually, the quality of a controller is based on its stability, accuracy and rapidity. It is hoped that it can reach the expected value faster and more accurately. , reflected in the response curve should have a faster rising speed, and have a smaller overshoot and oscillation. c 1 and c 2 Both are positive numbers greater than zero, respectively representing the proportion o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More