

Subway station air conditioning system energy-saving control method based on deep reinforcement learning
An air-conditioning system and reinforcement learning technology, applied in neural learning methods, biological models, design optimization/simulation, etc., can solve problems such as long convergence time, limited parameter space, and limited applicability of complex system control, so as to reduce training time , reduce the number of training sessions, and meet the temperature requirements of the station
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0075] A method for energy-saving control of subway station air-conditioning systems based on deep reinforcement learning: through the following steps:
[0076] S1. Collect the data parameters of the air-conditioning system of the subway station;
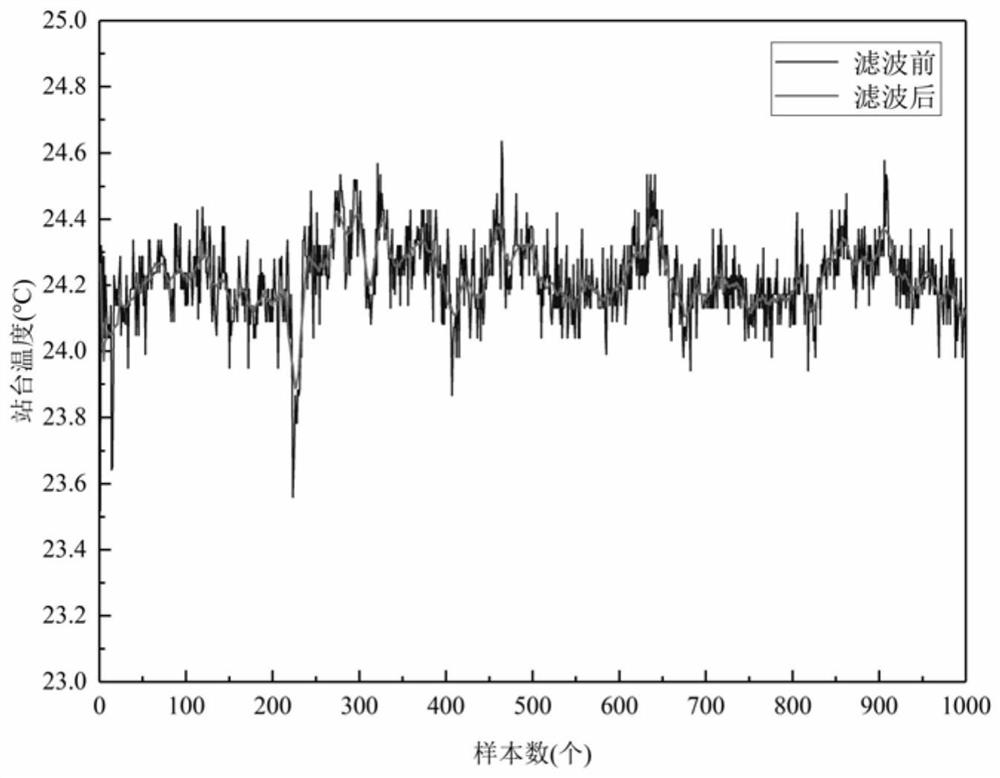
[0077] S2. Perform moving average filter processing, normalization and denormalization processing on the collected data, and convert the data into a value within the range of 0-1 by using a linear function conversion method;
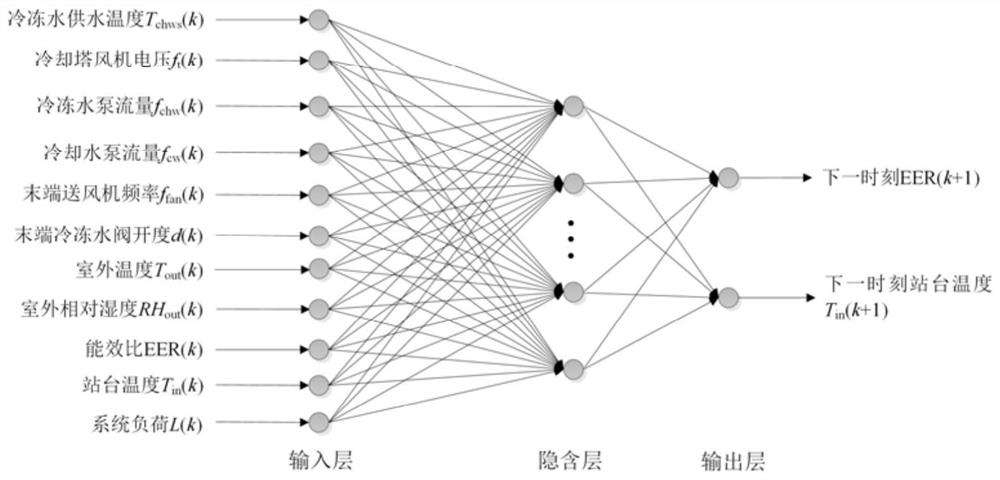
[0078] S3, using the neural network and the data obtained in step S2 to construct the neural network model of the air-conditioning system of the subway station;
[0079] S4. Determine the state variable, action variable, reward signal and structure of the DDPG agent;
[0080] S5. Using the DDPG algorithm to solve the final control strategy.
[0081] The above steps S1-S3 are described in further detail below:
[0082] In order to reduce the training time of the agent, it is first necessary to model the syst...
Embodiment 2
[0107] A method for energy-saving control of subway station air-conditioning systems based on deep reinforcement learning: through the following steps:
[0108] S1. Collect the data parameters of the air-conditioning system of the subway station;
[0109] S2. Perform moving average filter processing, normalization and denormalization processing on the collected data, and convert the data into a value within the range of 0-1 by using a linear function conversion method;
[0110] S3, using the neural network and the data obtained in step S2 to construct the neural network model of the air-conditioning system of the subway station;
[0111] S4. Determine the state variable, action variable, reward signal and structure of the DDPG agent;
[0112] S5. Using the DDPG algorithm to solve the final control strategy.
[0113] Steps S4-S5 are further described below:
[0114] Before the DDPG agent is trained, the control strategy must first determine the state, action, reward signal, ...
experiment example
[0155] In order to realize the proposed improved DDPG algorithm, this experimental example uses Pycharm software, based on the Tensorflow framework, an algorithm program is written according to Algorithm 1, and a simulation experiment is carried out, and the neural network model established in Example 1 is used as the learning environment for the DDPG agent .The specific process is attached Figure 10 shown.
[0156] attached Figure 11 The score (total reward value) of the DDPG algorithm based on multi-step prediction is given during 1000 times of training. It can be seen that during the training process, the reward value of each time fluctuates, and the main reasons for this phenomenon are Two, one is that the initial environment of each training is different, and the other is that the algorithm adds random noise to each strategy exploration. However, from the perspective of the change trend of the overall reward value, during the training process, the total reward value sh...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More