Content similarity sorting algorithm
A sorting algorithm and similarity technology, applied in computing, biological neural network model, semantic analysis and other directions, can solve the problems of high consumption of computing resources, destroy the sense of experience, long computing time, etc., to reduce the scope of computing, save computing resources, The effect of reducing computation time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
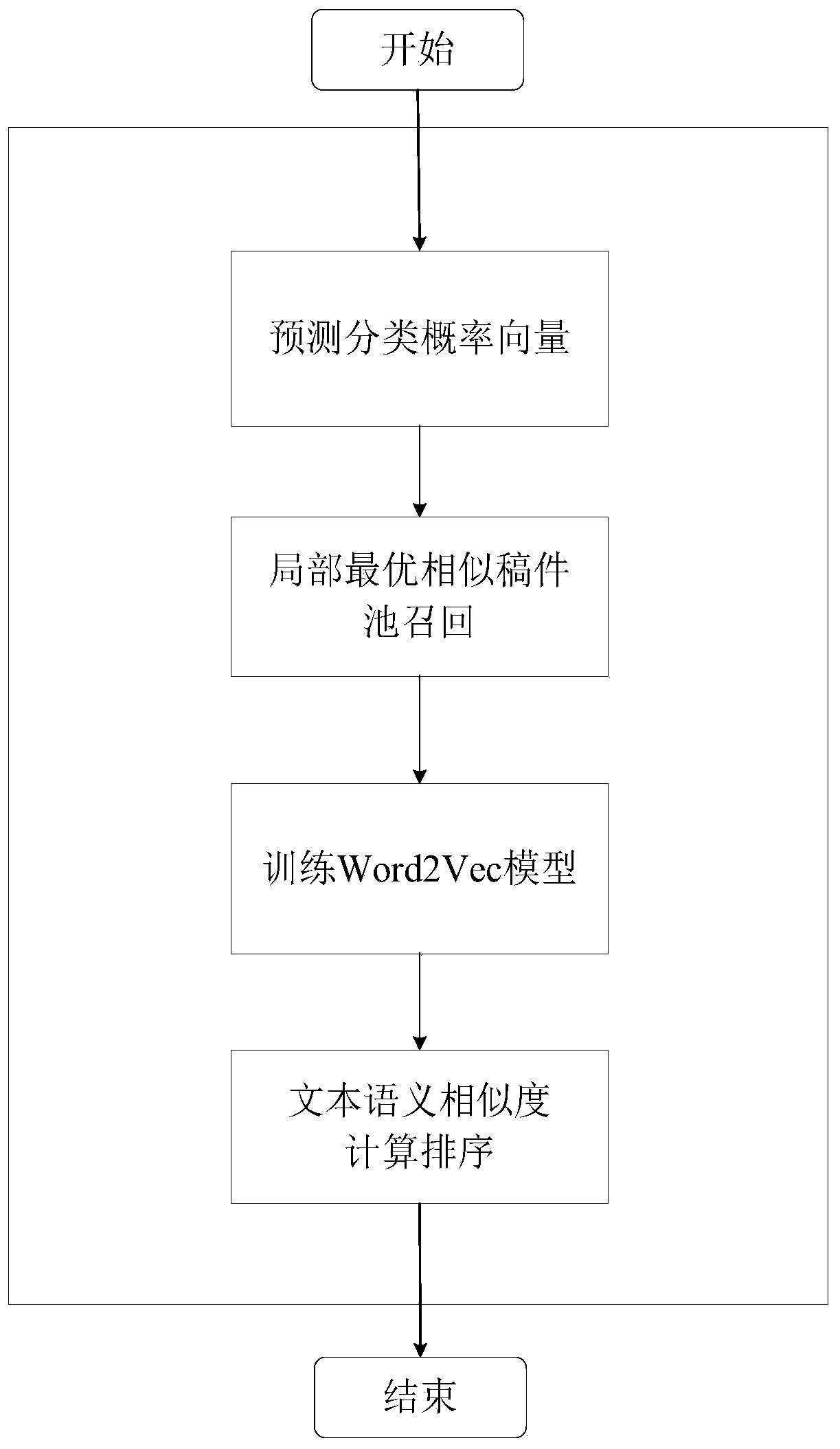
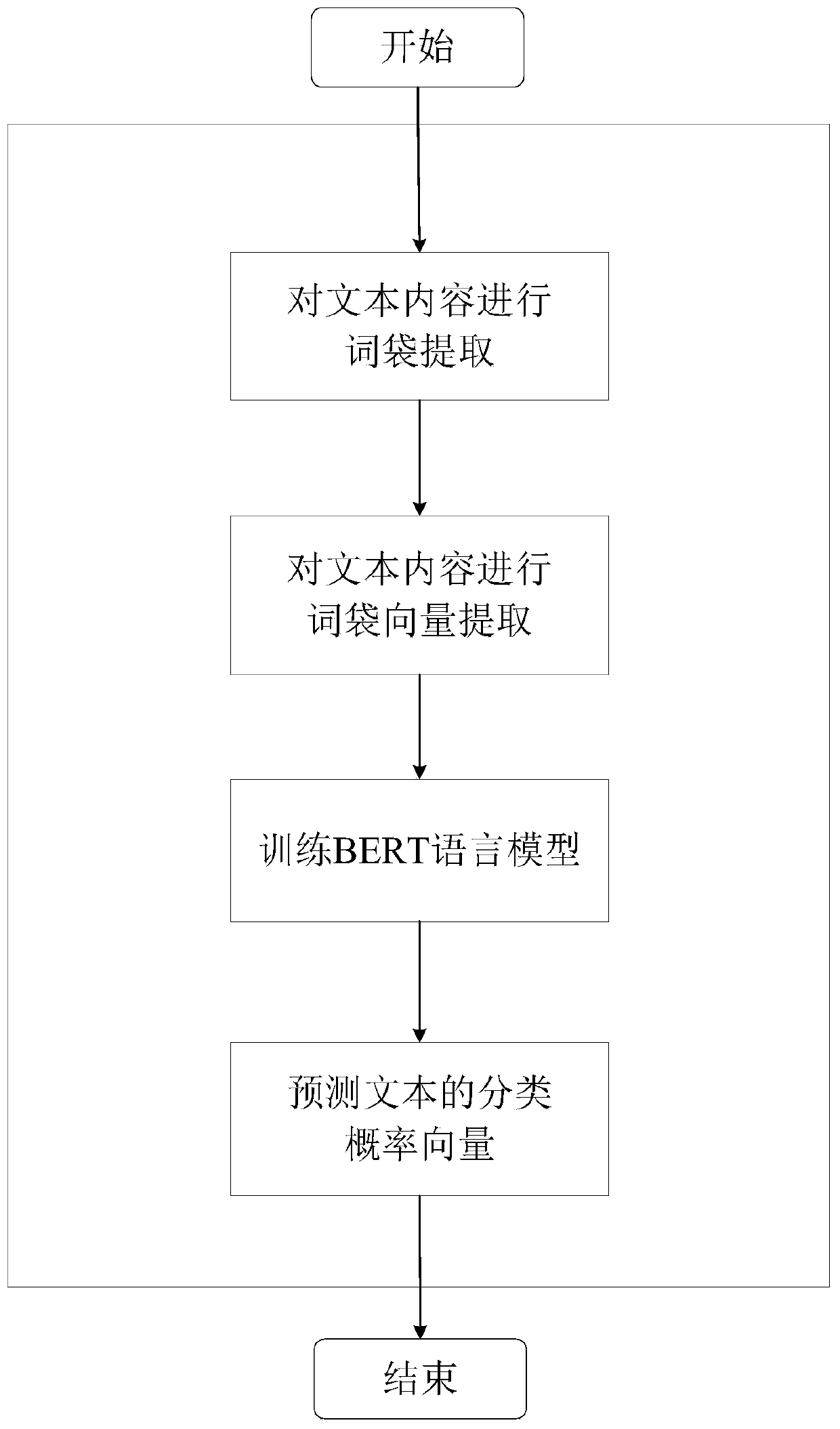
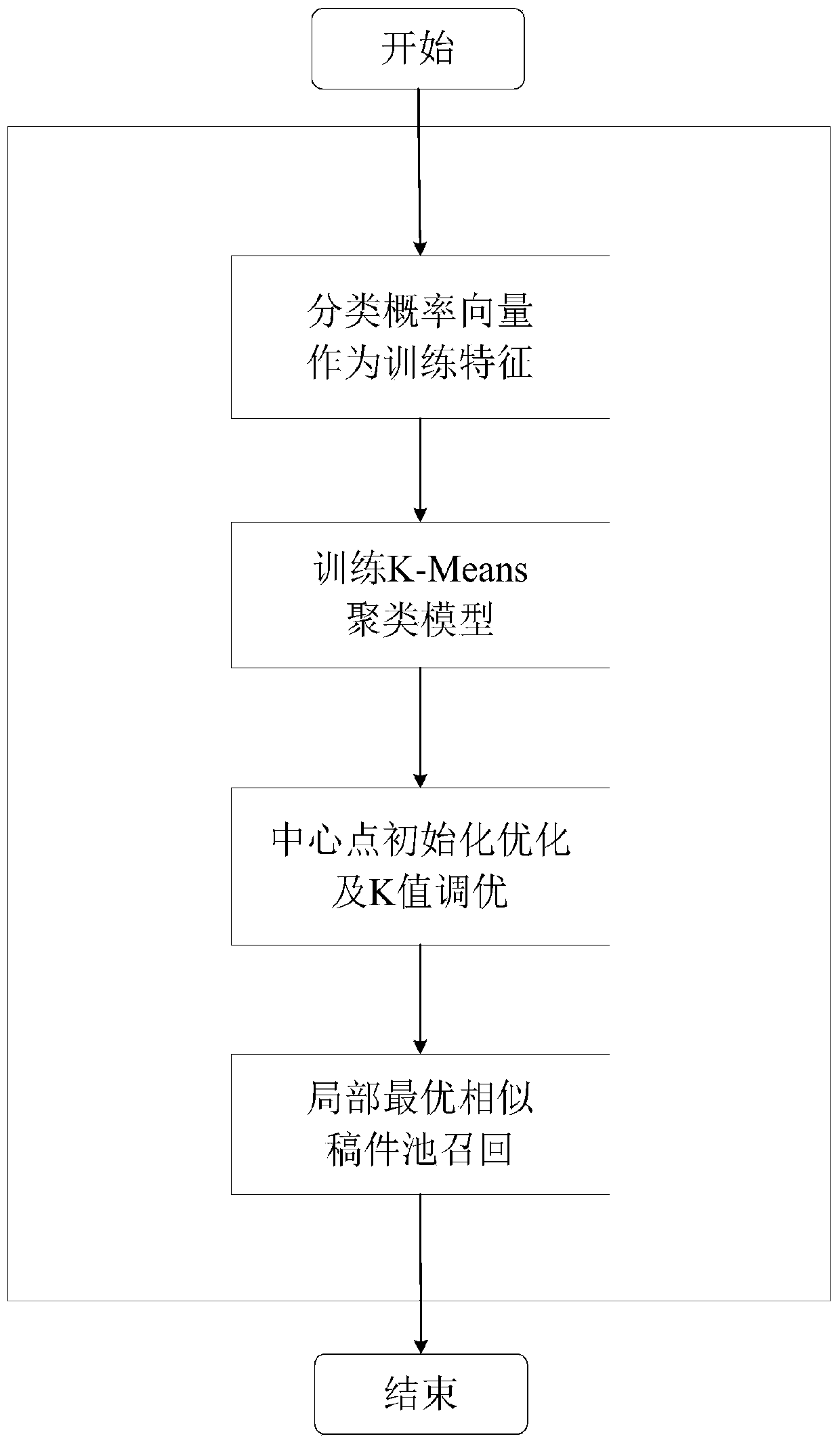
[0045] Example 1, such as figure 1 As shown, the present invention comprises two parts of text similar recall and text semantic similarity sorting; Its text similar recall is the text similar recall layer, and its text similar recall layer adopts BERT language model and K-Means clustering model to realize; Its text The semantic similarity ranking is the text semantic similarity ranking layer, and its text semantic similarity ranking layer is implemented by the Word2Vec neural network model.
[0046] Such as Figure 2-Figure 3 As shown, text similarity recall specifically includes the following steps:
[0047] Step 1: Predict the classification probability vector P
[0048] (1) Perform data processing on massive text data, extract text length seq_len and text content chars, and combine them into a text set with two dimensions;
[0049] (2) For all text content chars, establish a bag of words model, and perform word bag vector words conversion on the text content chars, extra...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com