

Abstract generation method based on single long text
A long text and abstract technology, applied in the field of abstract generation based on a single long text, to achieve the effect of high difficulty and time-consuming
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

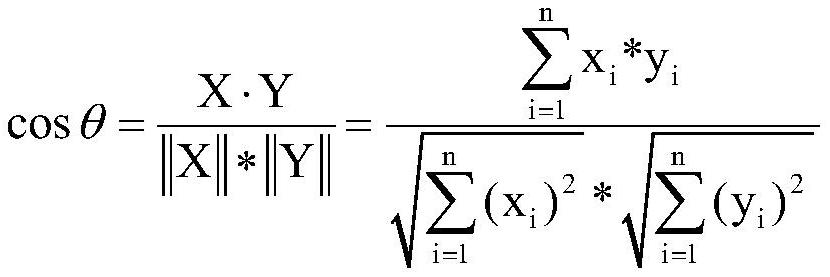
Examples
specific Embodiment 1
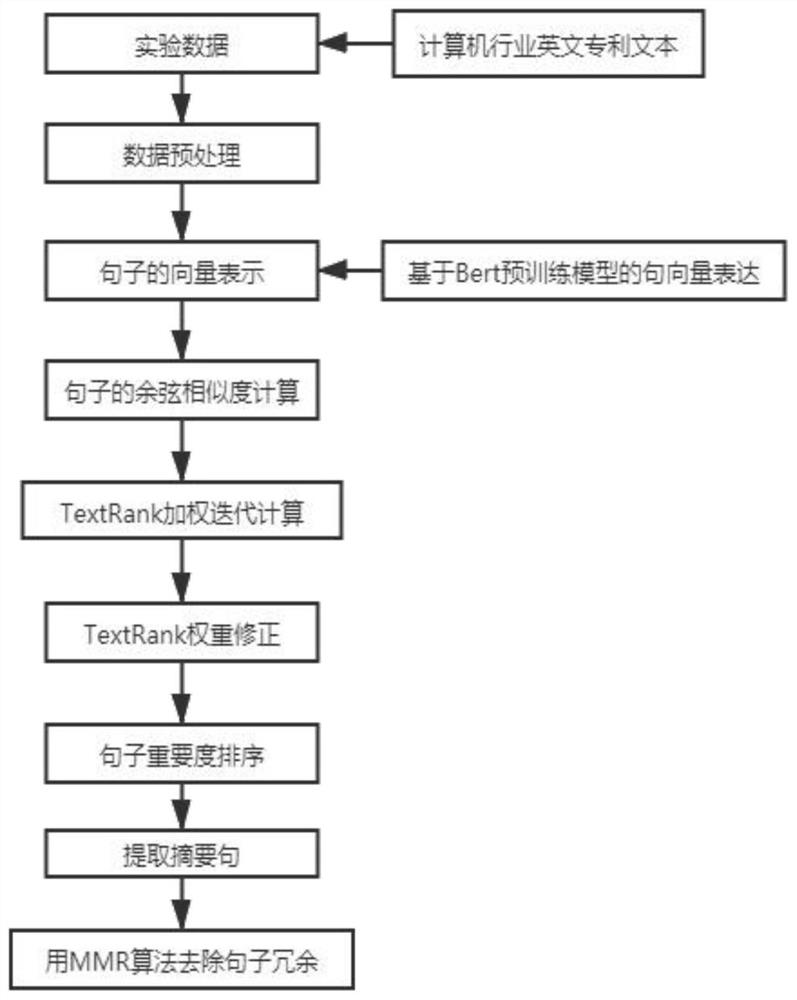
[0053] Such as figure 1 As shown, the present invention provides a method for generating abstracts based on a single long text, comprising the following steps:
[0054] A method for generating an abstract based on a single long text, comprising the following steps:
[0055] Step 1: For the single long text to be processed, construct the feature vector of the text sentence through the Bert algorithm, and determine the cosine similarity between the sentences;
[0056] The step 1 is specifically:
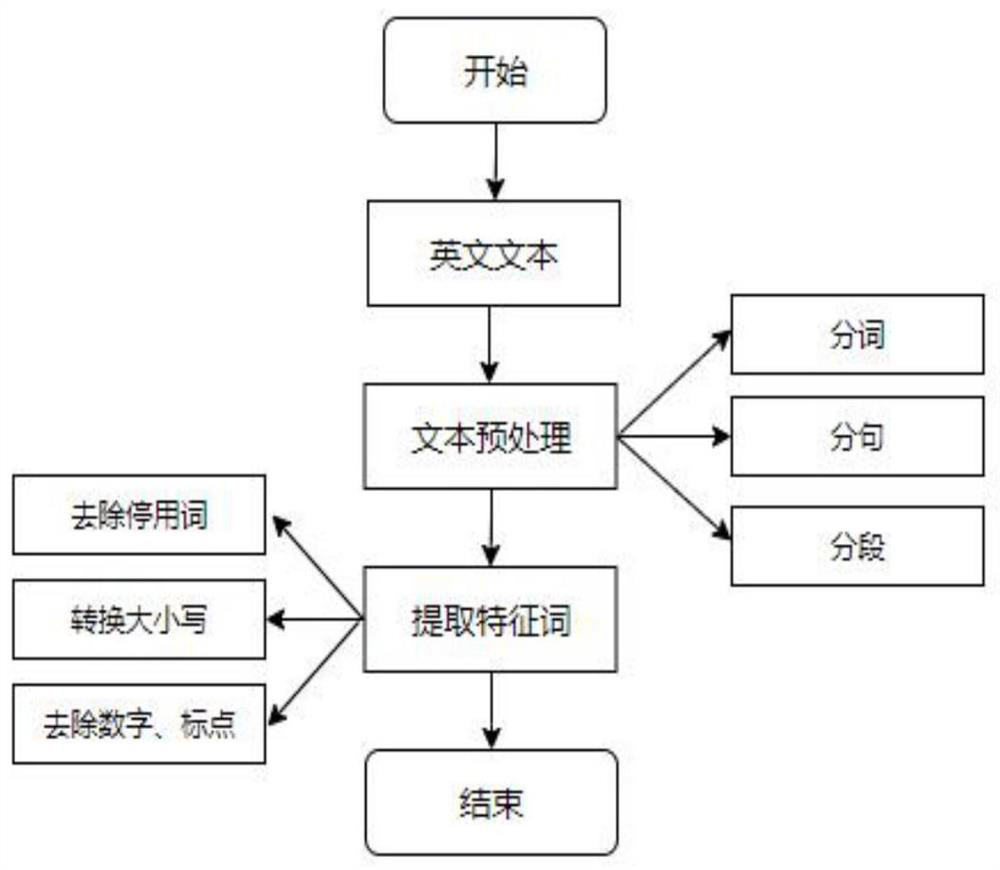
[0057] Step 1.1: Based on the single long text to be processed, the sent_tokenize() function in the punkt separator in the NLTK library is used to separate the sentences of the English text. The sent_tokenize() function in the punkt separator uses a language-independent The unsupervised method detects sentence boundaries, enabling it to accurately handle dotted words;
[0058] Perform word segmentation, case conversion, removal of stop words, numbers and punctuation processing on se...
specific Embodiment 2
[0093] The method design process that the present invention proposes is as figure 1 As shown, the method is based on the design of the classic TextRank algorithm, as follows:
[0094] Step 1: For a single long text to be processed, express the sentence feature vector through the Bert algorithm to calculate the cosine similarity;
[0095] The method of the present invention is based on the realization of the TextRank algorithm. In the classic TextRank algorithm, the feature representation of the sentence is to measure the similarity between two sentences based on the method of content overlap. This method only considers the difference between the words. overlap, while ignoring the semantic information in the sentence. In order to consider the semantic information of sentences, later scholars began to consider using word embedding methods such as Word2Vector model or GloVe model to express word vectors, and express sentence vectors by means of weighted average of word vectors. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More