

Legal case similarity calculation method and system based on multi-head attention
A similarity calculation and attention technology, applied in the field of text recognition, can solve the problem of low matching accuracy, and achieve the effect of improving accuracy, improving accuracy, and accurate and reliable calculation results.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
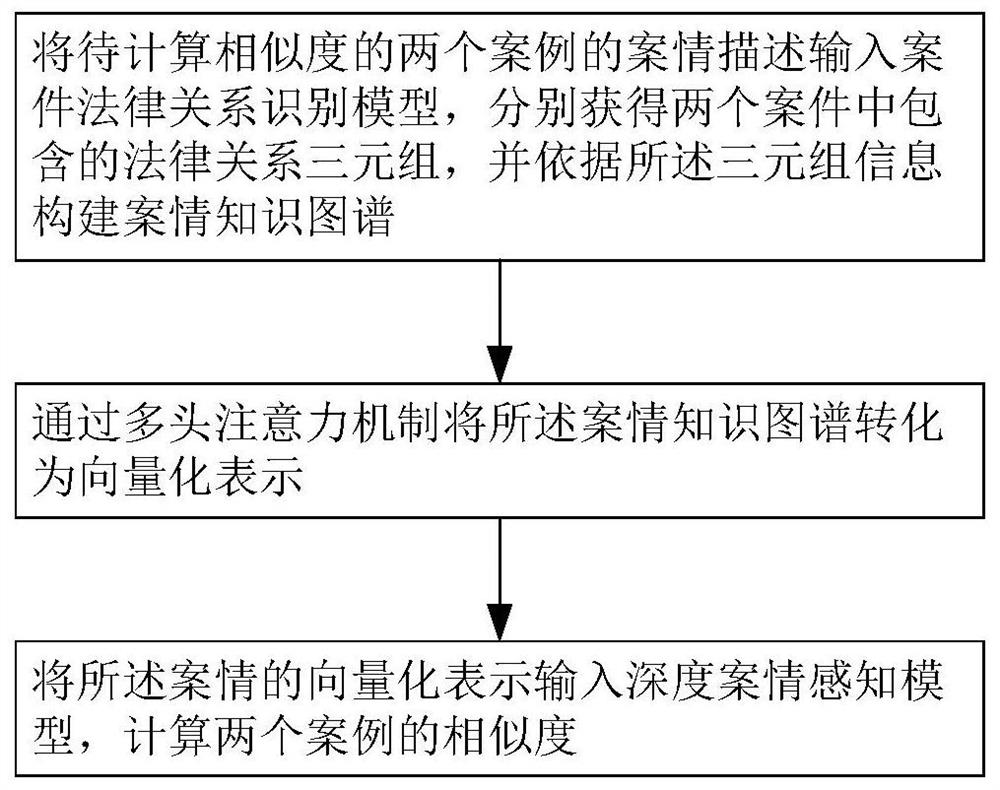
[0085] A method for calculating the similarity of legal cases based on multi-head attention, the method includes:
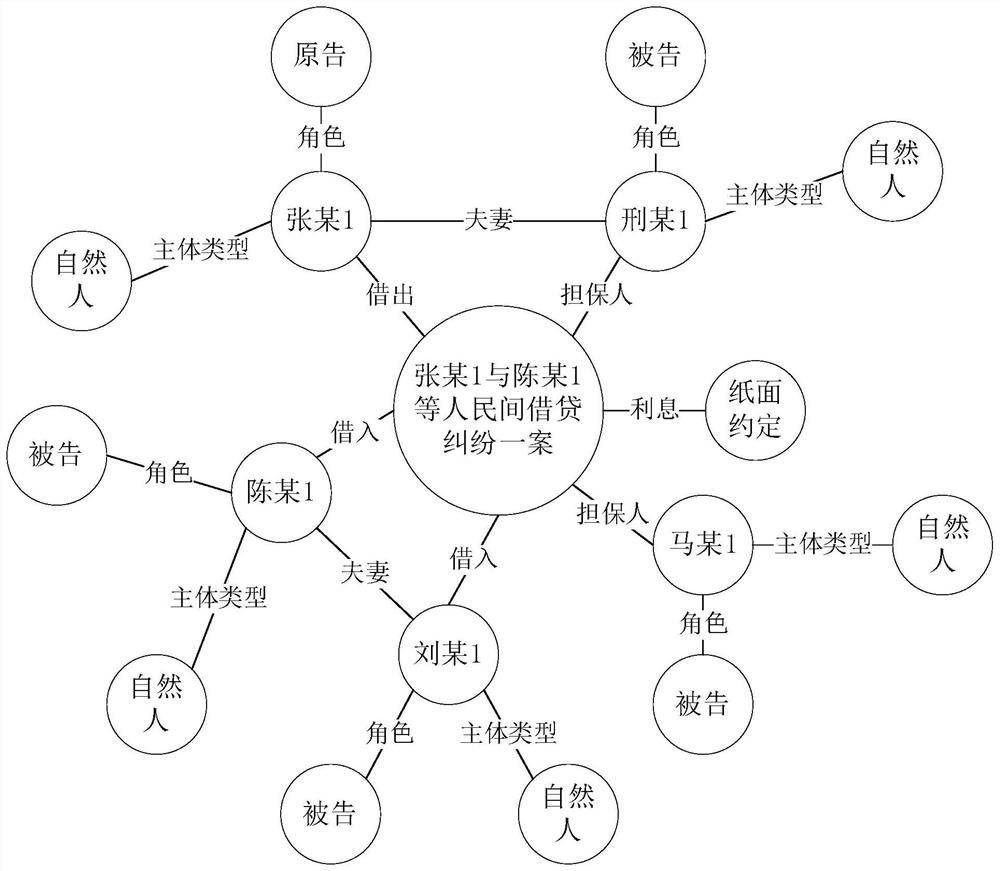
[0086] 1) Input the case descriptions of the two cases whose similarity is to be calculated into the case legal relationship recognition model, and extract the triples formed by the legal relationships in the two cases respectively, and the triples include the head entity, relationship and tail entity , and build a case knowledge map based on the triples;
[0087] 2) Convert the case knowledge map into a vectorized representation through a multi-head attention mechanism;
[0088] 3) Input the vectorized representation of the case into the deep case perception model to obtain the similarity between the two cases.
Embodiment 2
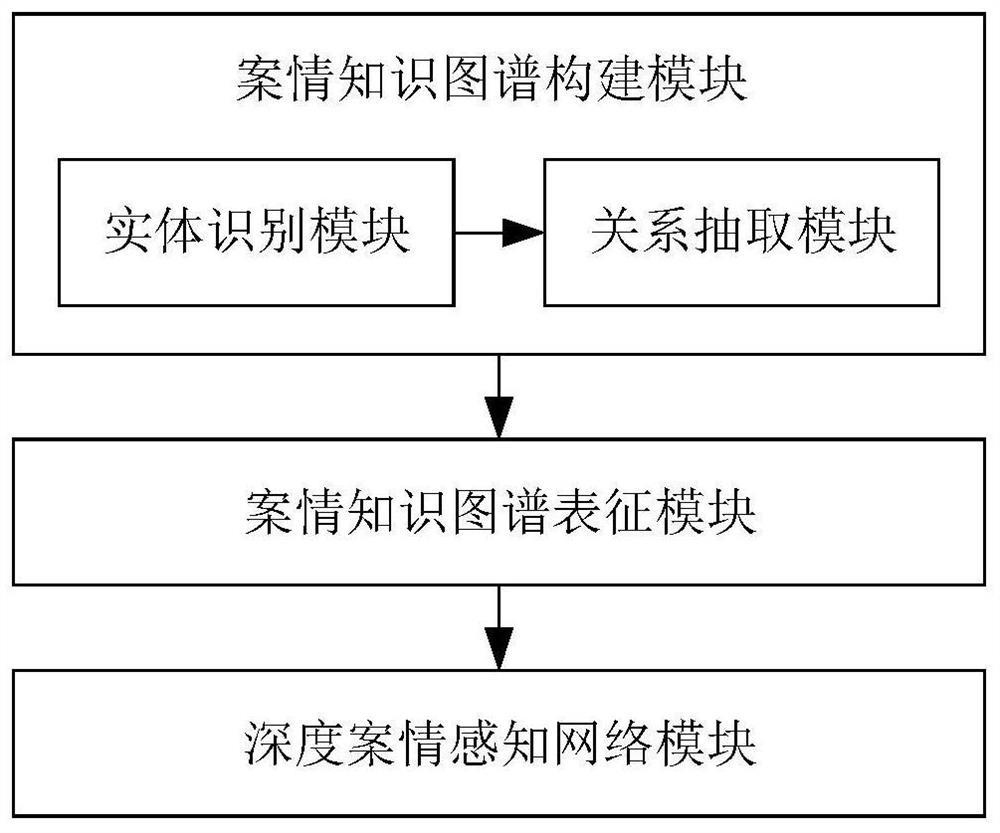
[0090]Repeat embodiment 1, but the case legal relationship recognition model described in step 1) includes: an entity recognition module for identifying entities in the description of the case; a relationship extraction for identifying the relationship between entities in the description of the case module. When identifying the case description of the structured text and the quasi-structured text, the entity identification module identifies the entity using a rule-based entity identification method.
[0091] Step 1) described in the construction method of case legal relationship identification model comprises the following steps:
[0092] 1a) Determine the entities and relationships that have an impact or have a greater impact on the calculation of case similarity, and construct a case legal relationship recognition model training data set;
[0093] In this embodiment, 600 judgment documents are randomly selected for labeling, and the entities and relationships included in th...
Embodiment 3
[0113] Repeat embodiment 2, just described step 2) specifically comprise the following steps:
[0114] 2a) initializing vectorized representations of the head entity, relation and tail entity of the triple;
[0115] In this embodiment, the triplet can be expressed as t ijk =(e i ,r k ,e j ), use random initialization to initialize the entities and relationships into d-dimensional vectors, and the vectorized triples can be expressed as where e i and e j denote head entity and tail entity respectively, r k Indicates the relationship, h i 、h j and l k are their corresponding vectorized representations, respectively.
[0116] 2b) concatenating the vectorized representations of the entities and relations of the triples, and calculating the eigenvectors of the triples using a projection matrix;
[0117] In this embodiment, the calculation formula of the eigenvector of the triplet is:
[0118]
[0119] Among them, W 1 is a linear transformation matrix,
[0120] 2c) ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More