
Patsnap Eureka
For R&D, Patsnap Eureka makes reading and utilizing patents & technical documents easy.
Patsnap Eureka AIR
Designed for self-driven R&D workflows. Generate viable solutions, solve complex R&D challenges, empower your innovation with AI.

Patsnap Eureka Materials
Designed for material experts only. Revolutionize your material R&D, from search, analyze, to developing new materials.

TechResearch
Generate reliable direction feasibility study reports for your R&D in just a few steps.

TechSeek
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

TechMind
As an expert in R&D Theories, TechMind can generates customized viable solutions instantly.

TechRisk
Analyze your overall solution with one click, know your potential R&D risks in advance.

TechMonitor
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Incremental data synchronization method and device based on map reduce
A technology of incremental data and data loading, applied in the field of data warehouse, can solve the problems of low efficiency of incremental comparison and synchronization, improve the efficiency of data synchronization, avoid large-scale data sorting operations, and improve the efficiency of data comparison and synchronization Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
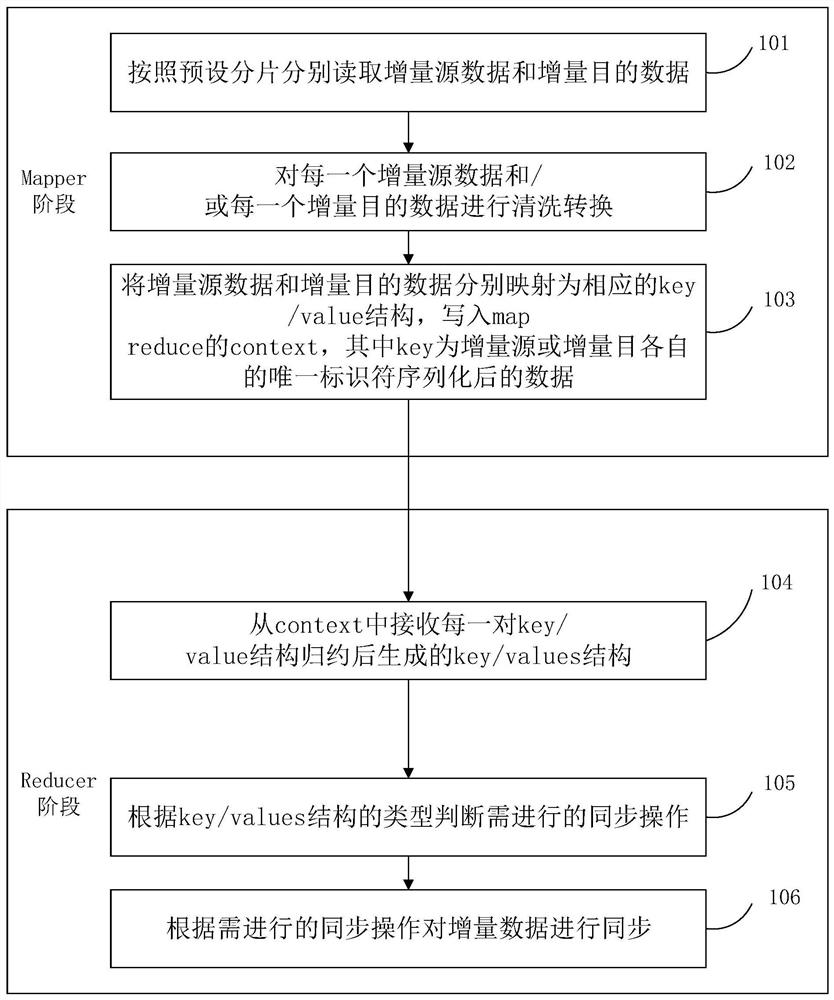
[0031] When performing incremental synchronization of ETL data, it is necessary to compare the corresponding data in the incremental source and the incremental destination one by one. In order to match the data in the incremental source and the incremental destination, the data needs to be sorted first. In common usage scenarios, the scale of incremental data that needs to be synchronized is very large, and sorting consumes a lot of time and resources. Moreover, the comparison process after sorting is generally single-threaded, and the efficiency is low.
[0032] Hadoop map reduce is a computing model, framework, and platform for parallel processing of big data. It can be used for parallel computing of large-scale data sets (greater than 1TB), and it allows ordinary commercial servers on the market to form a network containing dozens, hundreds to The distribution and parallel computing clusters of thousands of nodes provide a huge but well-designed parallel computing software ...
Embodiment 2
[0068] In the specific usage scenario of Embodiment 1, in order to adapt to the need for collating and synchronizing a large amount of data in a big data scenario, improve the platform versatility of the method, improve the convenience of implementing the solution, and facilitate the use in a distributed system, the present invention implements The example selects map reduce as the specific implementation method of concurrent execution.
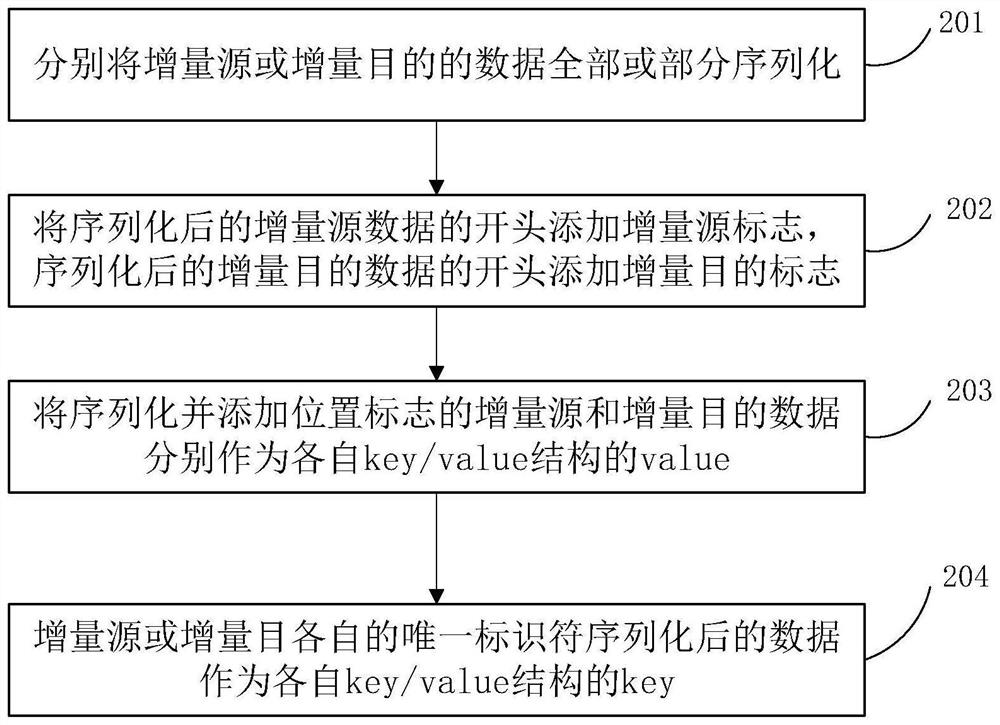
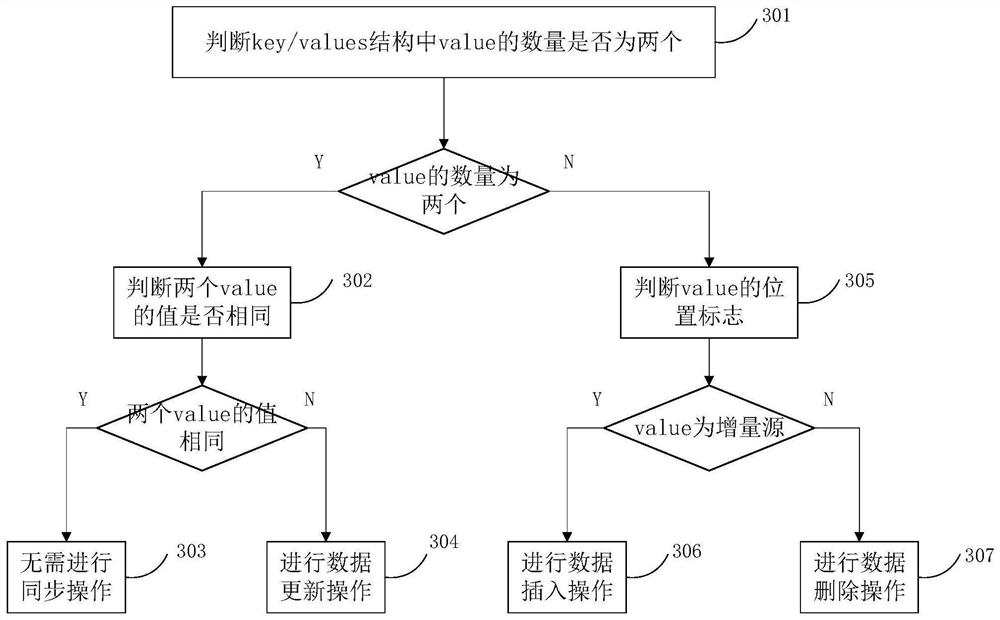
[0069] In the specific use scenario of this embodiment, such as Figure 5 The technical details of the Hadoop map reduce framework shown, steps 101 to 105 in Embodiment 1, and corresponding specific implementation steps and optimization methods are executed concurrently by map reducejob. Wherein, the map stage includes steps 101-1 and step 103, and the reduce stage includes steps 104-106.
[0070] The following methods can be used for specific execution, such as Figure 5 , according to the attribute information in the split and the process...
Embodiment 3
[0108] On the basis of the method for incremental data synchronization based on map reduce provided by the above-mentioned embodiment 1 to embodiment 2, the present invention also provides a device for incremental data synchronization based on map reduce that can be used to implement the above method, such as Figure 6 Shown is a schematic diagram of the device architecture of the embodiment of the present invention. The apparatus for incremental data synchronization based on map reduce in this embodiment includes one or more processors 21 and memory 22 . in, Figure 6 A processor 21 is taken as an example.
[0109] Processor 21 and memory 22 can be connected by bus or other means, Figure 6 Take connection via bus as an example.
[0110] The memory 22 is a non-volatile computer-readable storage medium based on a map reduce-based incremental data synchronization method, and can be used to store non-volatile software programs, non-volatile computer-executable progra...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com