Kafka-based automatic migration method of distributed data stream hierarchical cache
An automatic migration and data flow technology, applied in the field of big data storage, can solve the problems that the Kafka system does not support hierarchical storage, etc., and achieve the effects of improving stream processing performance, reducing storage costs, and expanding functions
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0033] The specific implementation of the present invention will be described in detail below in conjunction with the accompanying drawings.
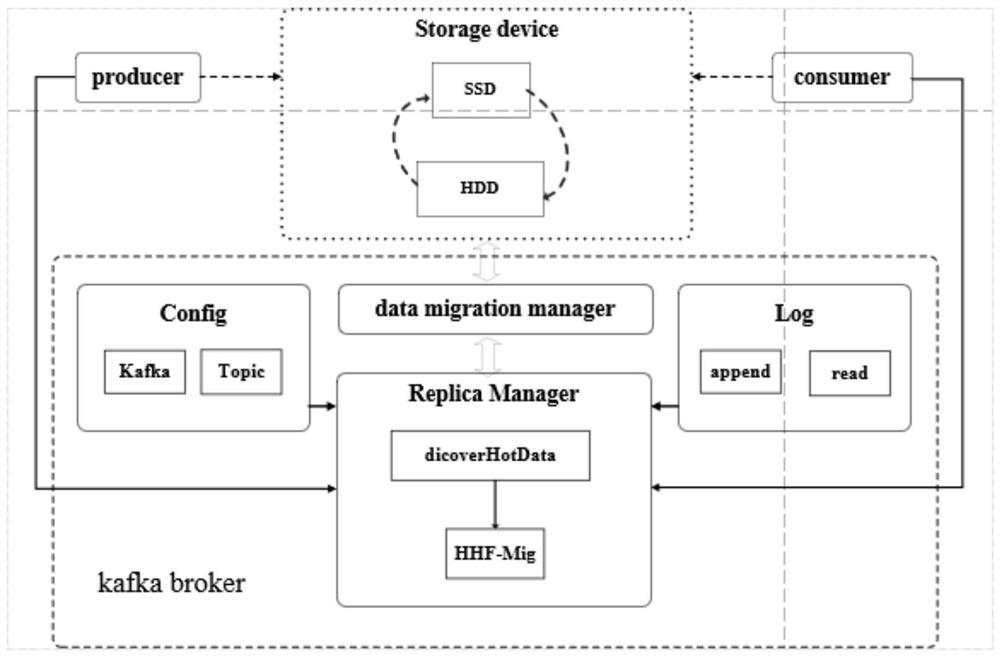
[0034] This embodiment is carried out in a cluster environment, the cluster includes three nodes, the software environment is Ubuntu16.04 system, the programming language is Java / scala, and the hierarchical storage system of each node is based on Samsung solid-state hard disk SSD (250GB) and Seagate mechanical hard disk HDD (1TB) build. The corresponding working parameters of the cluster are as follows: the copy coefficient of the topic is 2, the number of brokers (servers) is 3, the partition coefficient is also 3, and the number of producers and consumers is 6. Producers publish messages to the hierarchical cache system, and consumers read messages from the cache system. When reading and writing the log of the TopicPartition in the Kafka cluster, such as figure 1 As shown in the log module, use the read() and append() functions.
...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com