

Many-to-many voice conversion method based on double voiceprint feature vectors and sequence-to-sequence modeling
A voiceprint feature and voice conversion technology, applied in voice analysis, voice recognition, instruments, etc., can solve the problems of discontinuous feature space, ignoring information, and unsatisfactory conversion effect, so as to reduce actual cost and difficulty, reduce cost and Difficulty, good effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
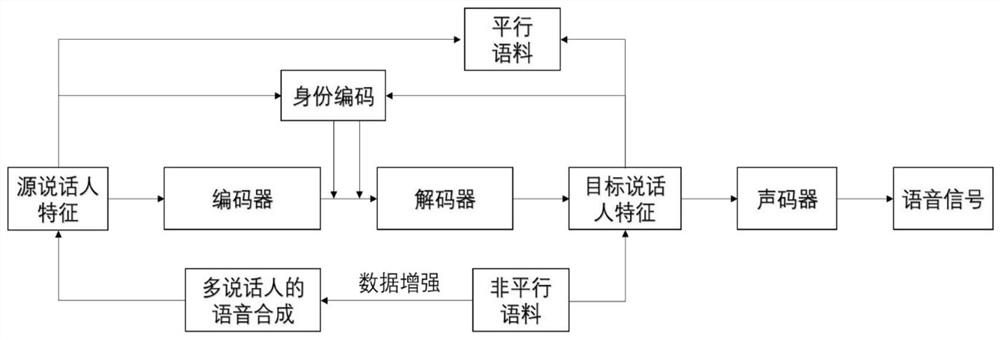
[0055] Such as figure 1 , 2 As shown, a many-to-many voice conversion method based on dual voiceprint feature vectors and sequence-to-sequence modeling, including the following steps:
[0056] S1. Data enhancement: use text-to-speech multi-speaker speech synthesis module to generate parallel corpus; parallel corpus means that the source speaker and target speaker speak the same content; due to the lack of a large amount of parallel corpus data, text-to-speech Multi-speaker speech synthesis technology to generate parallel corpus;
[0057] S2. Feature extraction of the speech signal: for the generated parallel corpus, extract the acoustic features of the original audio and the target audio;
[0058] S3. Encoding the speaker's identity feature to obtain a voiceprint feature vector representing the speaker's identity;
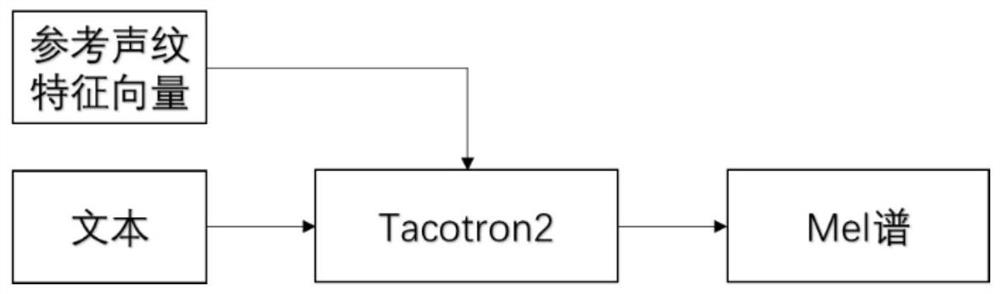
[0059] S4. Utilize the sequence-to-sequence voice conversion model to train the acoustic features of step S2 and the voiceprint feature vector of step S3. The s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More