

Method and system capable of switching bit-wide quantized neural network on line
A neural network and bit-bit technology, applied in neural learning methods, biological neural network models, neural architectures, etc., can solve problems such as changing bit widths
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

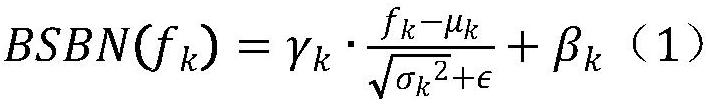
Examples
Embodiment 1
[0073] A method for quantizing a neural network capable of switching bit widths online according to the present invention, comprising:
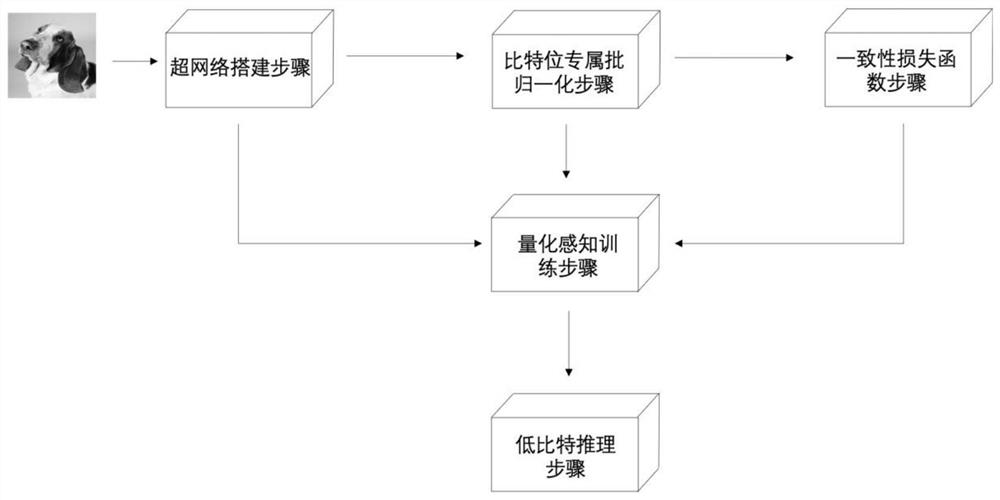
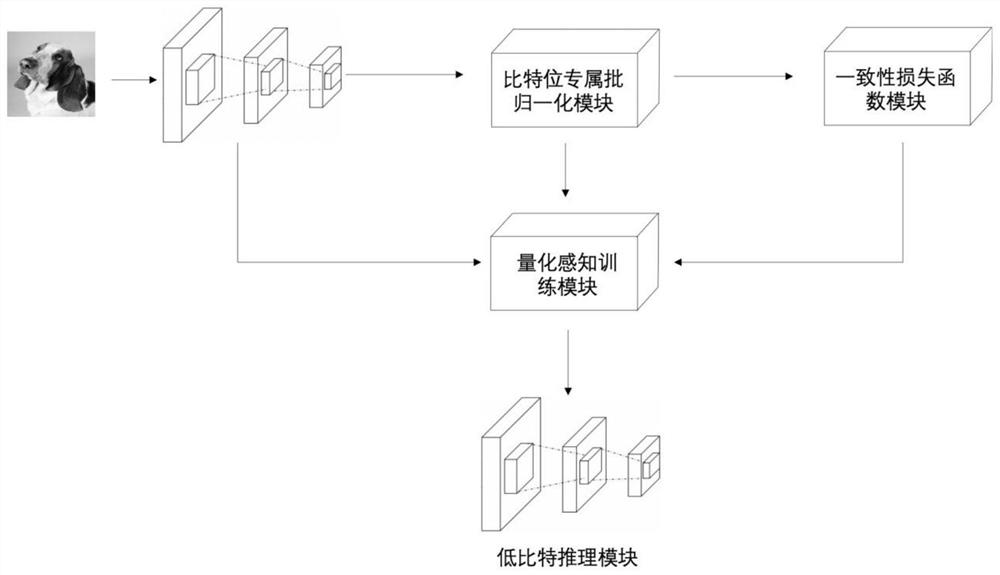
[0074] Step M1: Integrate deep neural networks with different bit widths into a super network, and all networks with bit widths share the same network architecture;
[0075] Step M2: The supernetwork operates with different bit widths. For any bit width, the corresponding network intermediate layer features are obtained, and each network intermediate layer feature is processed by a corresponding batch normalization layer;
[0076] Step M3: train the supernetwork through supervised learning, simulate quantization noise in the supernetwork training stage, until the consistency loss function between the low-bit mode and the high-bit mode converges, and obtain the trained supernetwork;
[0077] Step M4: using the preset quantizer to extract the quantized neural network of the target bit from the trained hypernetwork for low-bit inference;
[007...
Embodiment 2
[0132] Embodiment 2 is a modification of embodiment 1
[0133] In view of the defects in the prior art, the object of the present invention is to provide a quantized neural network capable of switching bit widths online, so that the deep neural network can be deployed with different bit widths without any additional training.
[0134] like figure 1 As shown, it is a flow chart of the quantized neural network that can switch the bit width online in the present invention. The method builds a hypernetwork, integrates the neural networks of different bits into the same network structure, and through different bit Wide, features are processed with a separate batch normalization layer to ensure network convergence. Through the consistency loss function step, the consistency between the low-bit mode and the high-bit mode is constrained in the training phase to reduce the error caused by quantization. The hypernetwork is optimized by quantization-aware training, and fast inference a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More