Pronunciation detection method and device, computer equipment and storage medium
A detection method and a technology for correct pronunciation, which are applied in speech analysis, teaching aids and instruments for electrical operation, etc., can solve the problems of error in judgment results, the generalization ability of classification models with limited segmentation accuracy, and the interpretation of pronunciation characteristics. The effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
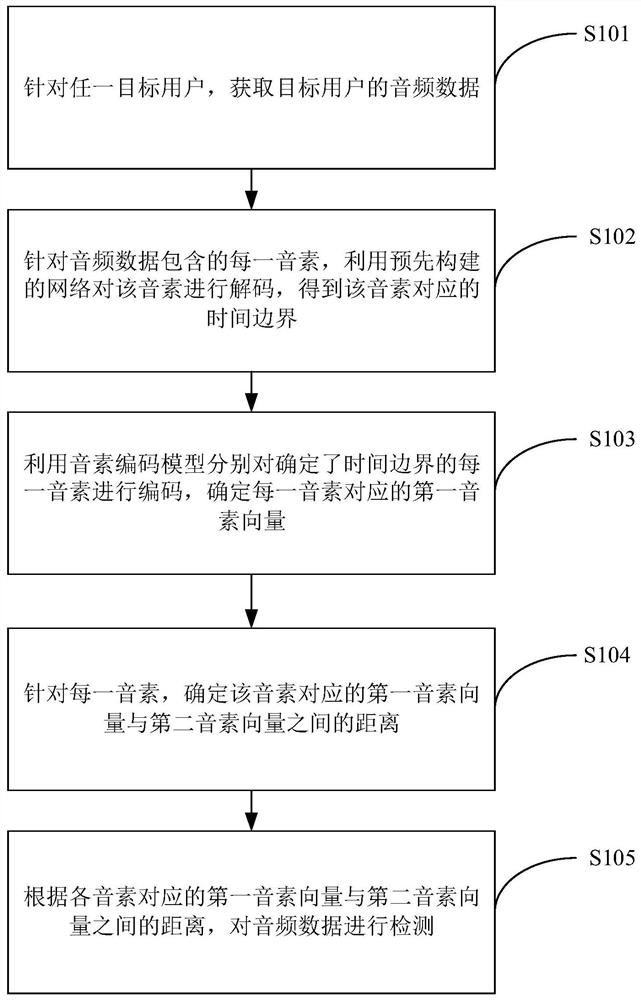
[0082] Aiming at the two aspects of the user's individual pronunciation characteristics and the feedback of the user's pronunciation errors, the embodiment of the present disclosure provides a pronunciation detection method, see Figure 1b As shown, it is a flowchart of a pronunciation detection method provided by an embodiment of the present disclosure, the method includes steps S101-S106, wherein:
[0083] S101: For any target user, acquire audio data of the target user.
[0084] In this step, the device receiving the audio data may be the terminal device 11 mentioned above, such as a computer, mobile phone, tablet computer and other devices installed with an evaluation client. During specific implementation, the client collects the audio data of the text read by the target user by calling the microphone of the terminal device. The audio data includes phonemes, and the client sends the audio data to the server to detect whether the reading is accurate or not.
[0085] Of co...
Embodiment 2
[0134] refer to Figure 6 As shown, it is a schematic diagram of a pronunciation detection device provided by an embodiment of the present disclosure, which includes: an extraction unit 601, a decoding unit 602, a first determination unit 603, a second determination unit 604, and a detection unit 605; wherein,
[0135] An extraction unit 601, configured to acquire audio data of the target user for any target user, the audio data including phonemes;
[0136] The decoding unit 602 is configured to use a pre-built network to decode each phoneme included in the audio data to obtain a time boundary corresponding to the phoneme, and the network is constructed using text information corresponding to the audio data of;
[0137] The first determining unit 603 is configured to use a phoneme coding model to encode the phonemes with determined time boundaries, and determine a first phoneme vector corresponding to each phoneme, wherein the phoneme coding model is based on the audio sample...
Embodiment 3
[0151] Based on the same technical idea, the embodiment of the present application also provides a computer device. refer to Figure 7 As shown, it is a schematic structural diagram of a computer device provided by the embodiment of the present application, including a processor 701 , a memory 702 , and a bus 703 . Among them, the memory 702 is used to store execution instructions, including a memory 7021 and an external memory 7022; the memory 7021 here is also called an internal memory, and is used to temporarily store calculation data in the processor 701 and exchange data with an external memory 7022 such as a hard disk. The processor 701 exchanges data with the external memory 7022 through the memory 7021. When the computer device is running, the processor 701 communicates with the memory 702 through the bus 703, so that the processor 701 executes the execution instructions mentioned in the above method embodiments .
[0152] Embodiments of the present disclosure furthe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More