

Big data task scheduling method
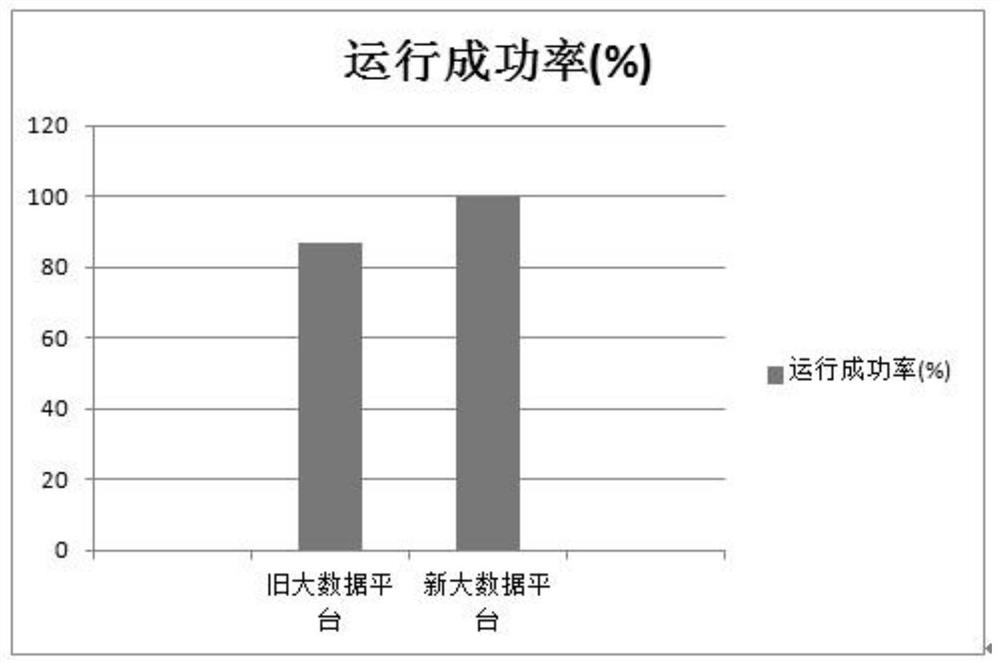
A task scheduling and big data technology, applied in digital data processing, program startup/switching, resource allocation, etc., can solve problems such as poor utilization of computing resources, and achieve the effect of solving excessive resource preemption and full utilization
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0028] The present invention will be further described below in conjunction with the accompanying drawings and embodiments.
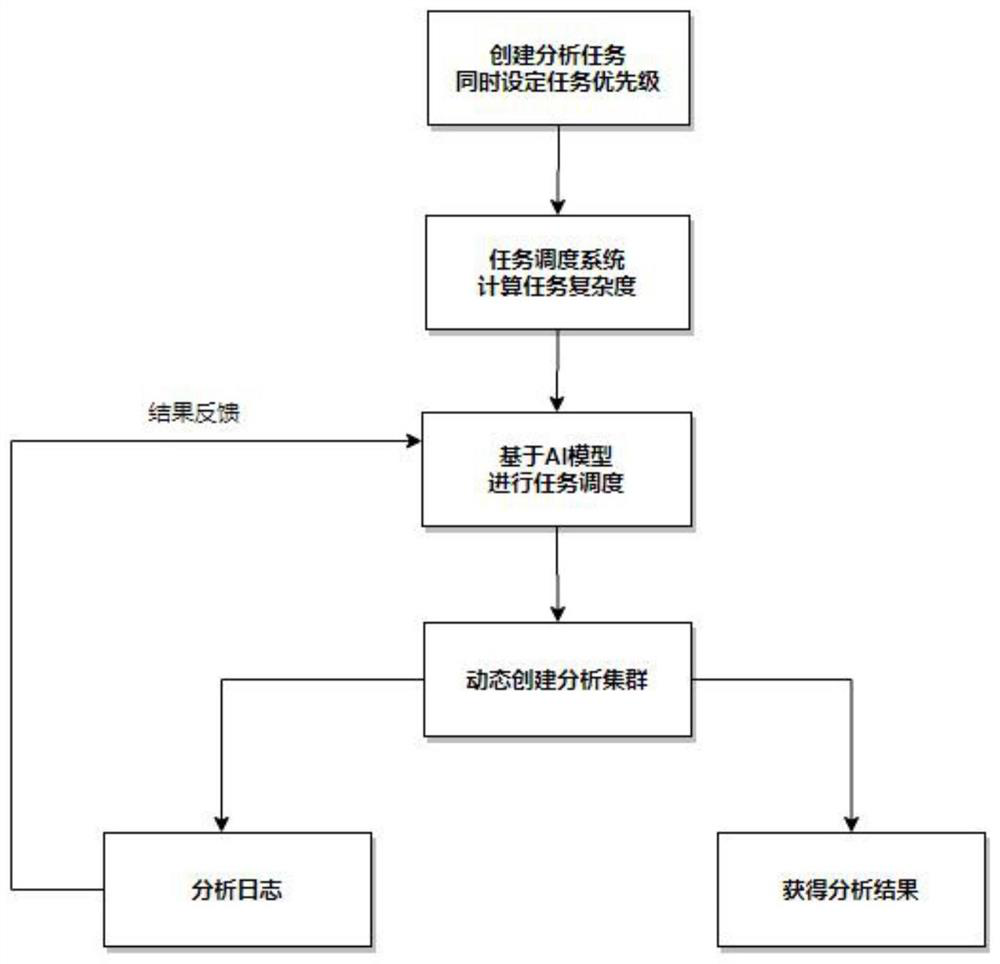
[0029] like figure 1 As shown, a big data task scheduling method includes the following steps:
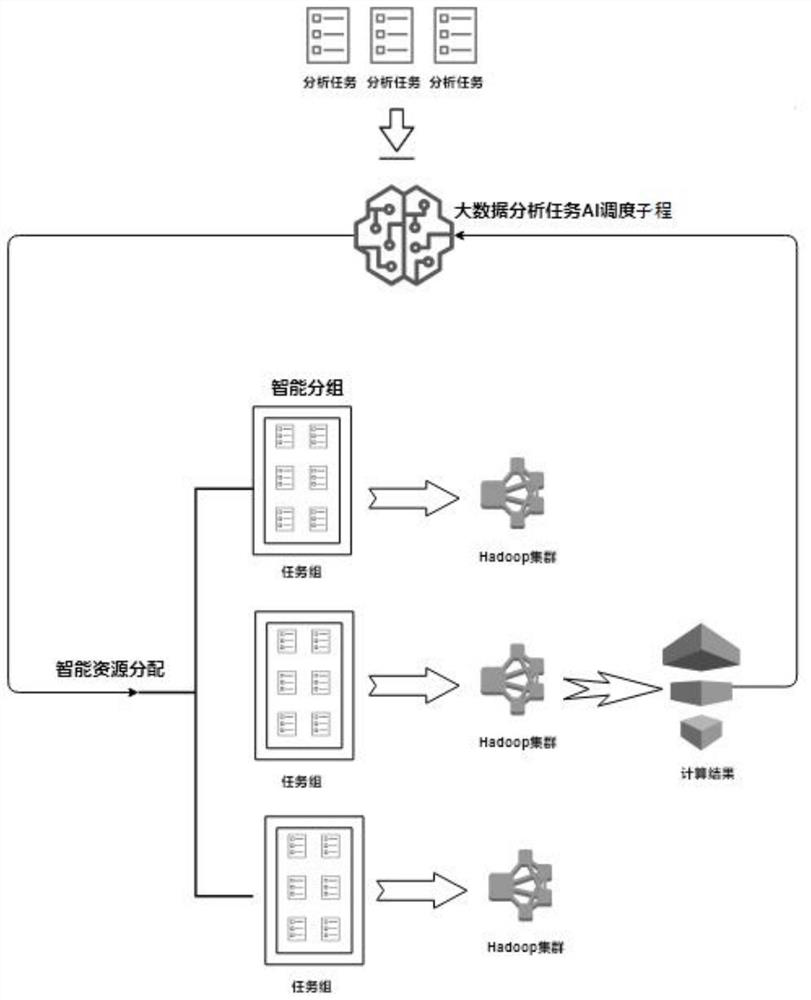
[0030] S1. Divide multiple big data analysis tasks into multiple priorities according to their importance, each big data analysis task has its own priority, divide the same priority big data analysis tasks into the same group, and get multiple group task group.
[0031] In step S1, the priority of each big data analysis task can be divided according to its business importance, and the higher the importance, the higher the priority.
[0032] In step S1, the priority of each big data analysis task can also be divided according to the importance of business guidance according to its analysis conclusion, and the higher the importance, the higher the priority.
[0033] Among them, each step is explained as follows:
[0034] S2. Determine the complexity of eac...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More