

Large-scale data similar feature detection method based on inverted indexes
A large-scale data and inverted index technology, which is applied in unstructured text data retrieval, text database indexing, special data processing applications, etc., can solve problems such as inability to apply numerical features, poor performance, and affecting feature selection. Achieve the effects of ensuring uniqueness and accuracy, improving computing efficiency, and reducing scale
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

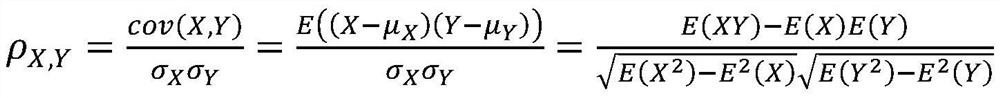
Examples
Embodiment Construction
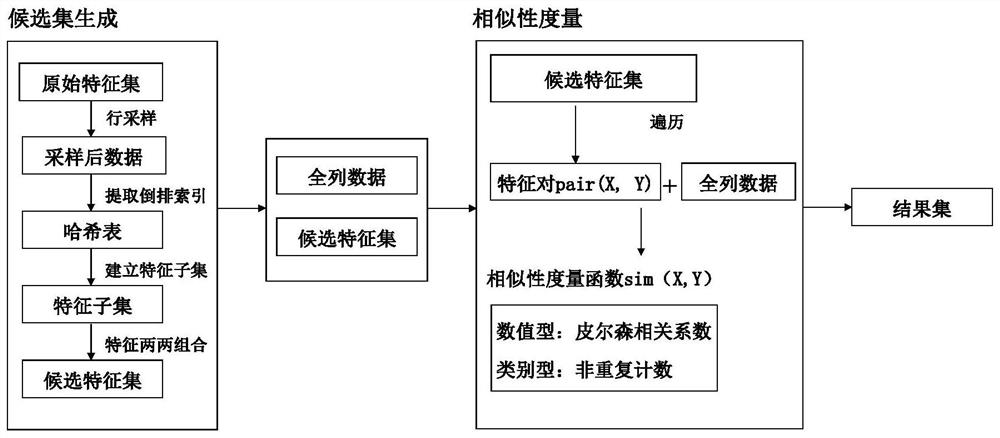
[0023] Such as figure 1 As shown, the large-scale data similar feature detection method based on inverted index includes: candidate set generation, similarity measurement and result set integration process.
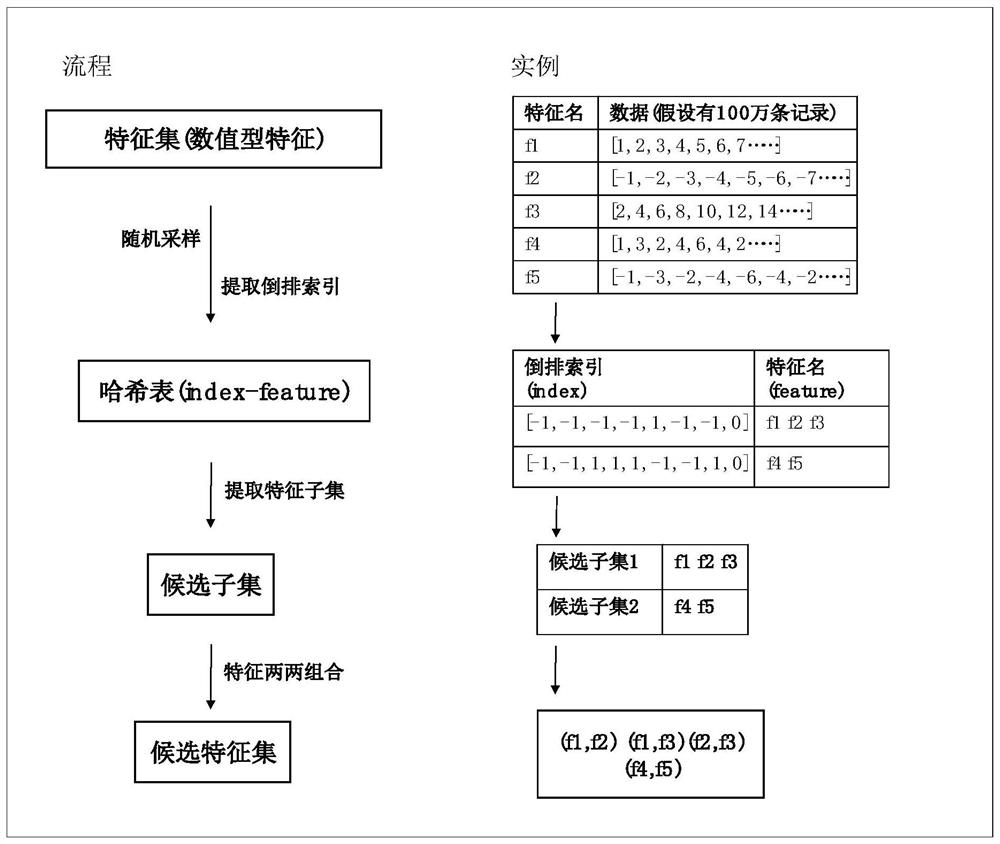
[0024] First, column sampling is performed on the data corresponding to all the features in the original feature set, and an inverted index is constructed. The features with the same inverted index are put into the same feature subset, and all the features in each feature subset are combined to form a feature pair, and then added to the candidate feature set. The present invention proposes a brand-new inverted index design method by analyzing the relationship between feature distribution and similarity measurement function:
[0025] For a numerical feature pair (let the feature be X, Y), the Pearson correlation coefficient is used to measure the similarity between the features X and Y, and the Pearson correlation coefficient formula is as follows:
[0026]
[0027] T...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More