A PDF automatic indexing system and method based on text features and grammar rules
An automatic indexing and fully automatic technology, applied in special data processing applications, natural language data processing, semi-structured data mapping/conversion, etc., can solve problems such as dependence on personnel quality, reduce duplication of labor, improve scalability, The effect of improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


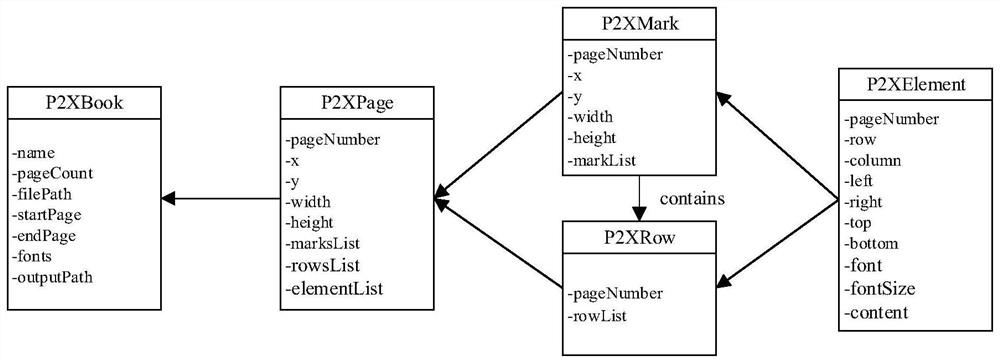
Examples
Embodiment
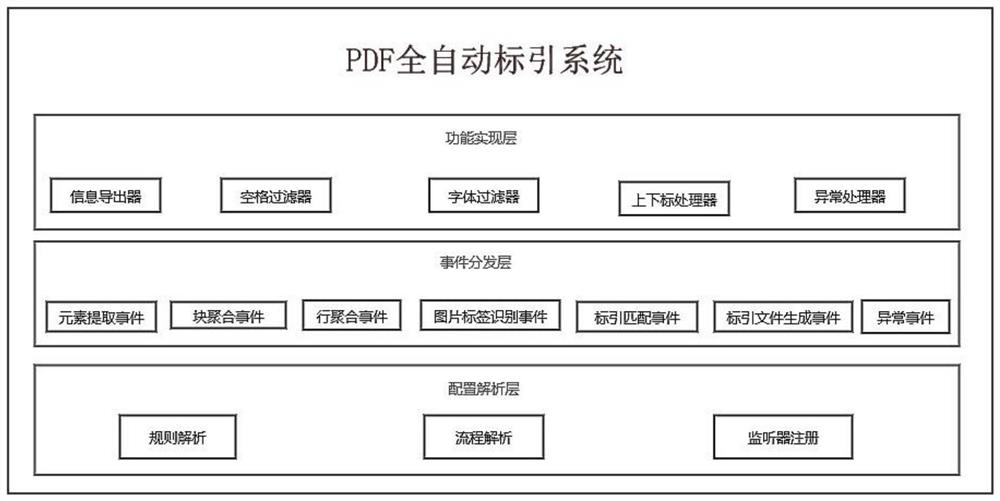
[0114] The overall architecture of the PDF automatic indexing system is as follows figure 1 shown.
[0115] The PDF automatic indexing system is divided into three layers, configuration analysis layer, event distribution layer, and function realization layer. The system adopts an event-driven approach and uses an observer mode architecture. The advantage of this architecture is that the specific implementation of functions and the main process are loosely coupled and belong to different levels. When the module is working, it only needs to use the event Sending out does not pay attention to the specific implementation, which will greatly improve the scalability of the system. For automatic indexing, many functions require iterative optimization to adapt to complex layouts and special situations. If it is a normal process architecture, adding a function often requires modifying the entire process, but with an event-driven architecture, we only need to re- Just add an event an...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com