

Multi-agent group cooperation strategy automatic generation method
An automatic generation and intelligent agent technology, applied in the field of artificial intelligence, can solve problems such as slow learning speed and difficult algorithm stability, and achieve the effect of improving training efficiency, improving generation and evaluation efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
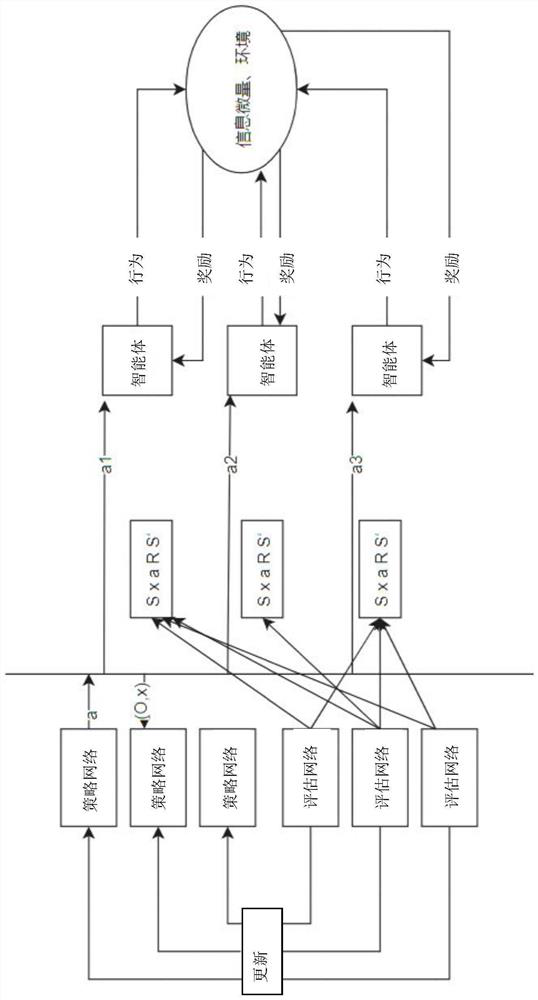
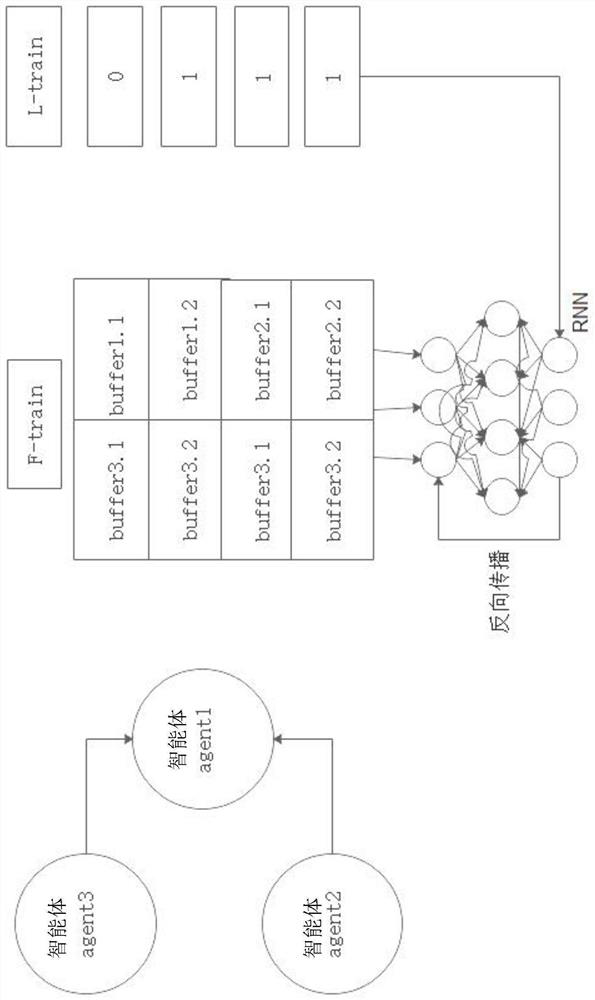
[0046] The invention discloses a multi-agent group cooperation strategy automatic generation method of MADDPG (a multi-agent reinforcement learning framework based on a deep deterministic policy gradient algorithm), hereinafter referred to as the TTL-MADDPG algorithm, which is based on the MADDPG algorithm. Based on the original MADDPG algorithm, three major innovations are proposed: trace information, multi-agent cooperative teaming, and life-and-death training. The invention takes the MADDPG algorithm as the main body, adds the strategy network (actor network) of the MADDPG algorithm into the information trace, and changes it to a i =μ θi (O i ,x i )+N noise , where x i Represents the intelligent agent i The trace amount of information, the intelligent agent i The learning history in the environment will leave a trace of its own information in the environment. Through the trace of information, the agent can learn from other people's experience and avoid detours. In th...
Embodiment 2
[0071] Application of multi-agent group cooperative strategy automatic generation algorithm in traffic light control.
[0072] Take the traffic signal at each intersection as the intelligent body, expressed as agent i ;
[0073] Input: the collection of multiple traffic signals Agents={agent 0 , agent 1 , agent 2 ,...,agent i}.
[0074] Input: Initialize each traffic signal agent i The policy network π i (o,θ πi ) and the evaluation network Q i (s,a 1 ,a 2 ^a N ,θ Qi ) and network parameters θ πi and θ Qi ; where o represents the real-time information of the traffic signal machine observing the traffic environment; strategy network π i Indicates the control strategy of the i-th traffic signal machine on the traffic lights each time, and evaluates the network Q i Indicates the evaluation of the i-th traffic signal machine on the control strategy of traffic lights, s indicates the status information of the traffic signal machine, a indicates the traffic control a...
Embodiment 3
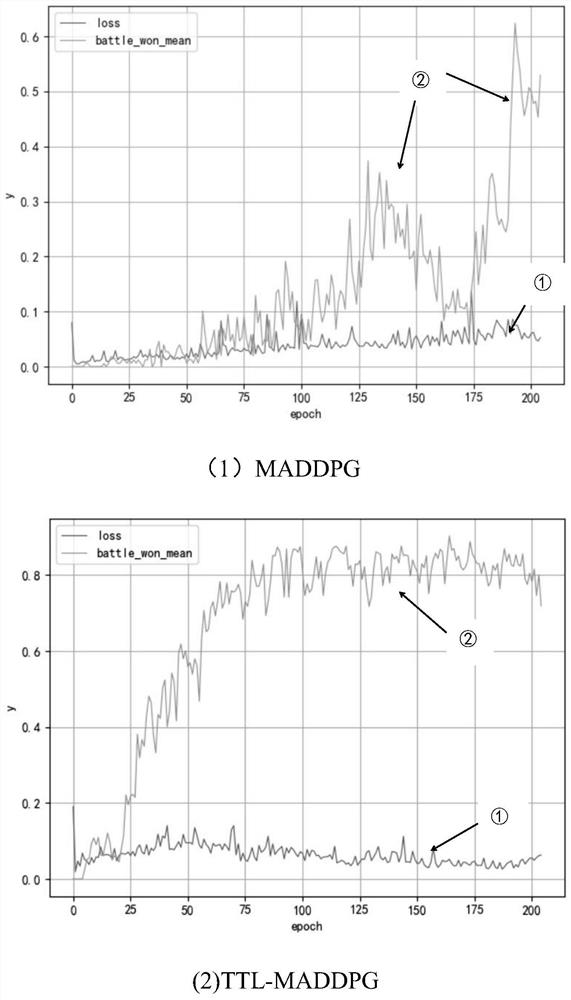
[0086] The algorithm in the automatic generation method of the multi-agent group cooperation strategy adopted by the present invention is evaluated through a simulation test.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More