

Process decomposition method and device for running ETL by hadoop cluster
A hadoop cluster and process technology, applied in the field of process decomposition of ETL running in hadoop cluster, can solve problems such as inability to complete DAG graph operation, and achieve the effect of convenient and flexible programming
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0053] Based on the constraints of traditional ETL data processing performance and the problems of simple use of hadoop, the embodiment of the present invention provides a process decomposition method for running ETL in a hadoop cluster, which can decompose the ETL process so that it can be submitted to the map reduce framework of the hadoop cluster environment after decomposition in the implementation.
[0054] Wherein, the process decomposition refers to decomposing the ETL process into one or more MRWorks (ie, Map ReduceWork), and the components of each MRWork run in one map reduce. All components of an MRWork usually run partly in the mapper and partly in the reducer. All mapper task sub-processes and all reducer task sub-processes constitute an MRWork.
[0055] Such as figure 1 As shown, the process decomposition method of hadoop cluster running ETL provided by the embodiment of the present invention mainly includes the following steps:
[0056] Step 10, constructing a ...
Embodiment 2
[0086] On the basis of the process decomposition method of a hadoop cluster running ETL provided in the above-mentioned embodiment 1, several specific examples are further given in the embodiment of the present invention to introduce how to use the method in embodiment 1 in different application scenarios Break down the process.
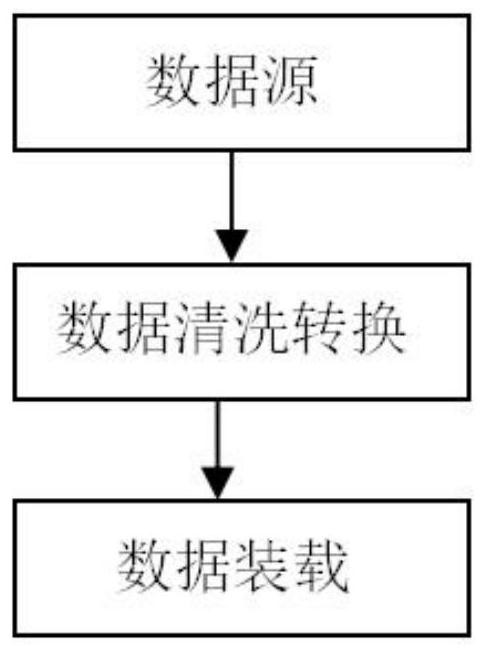
[0087] combine Figure 9 , in the first specific example, there is no reduce node in the ETL process, there is a data source, and the corresponding directed acyclic graph DAG is as follows Figure 9 As shown on the left (corresponding to figure 2 ). Since the reduce node cannot be searched in the DAG, the data source node and all downstream component nodes are directly formed into a mapper sub-process, and the ETL process is decomposed into an MRWork. In a preferred embodiment, the data source can be fragmented to obtain n fragmentation table data sources, which are respectively split1, split2, ..., splitn, corresponding to n mapper sub-processes...
Embodiment 3
[0096] It can be seen from the process decomposition method of Hadoop cluster running ETL provided by the above-mentioned embodiment 1 that if there are X reduce nodes in the ETL process, at least X map reduce is required, that is, the ETL process is decomposed into at least X MRWork.
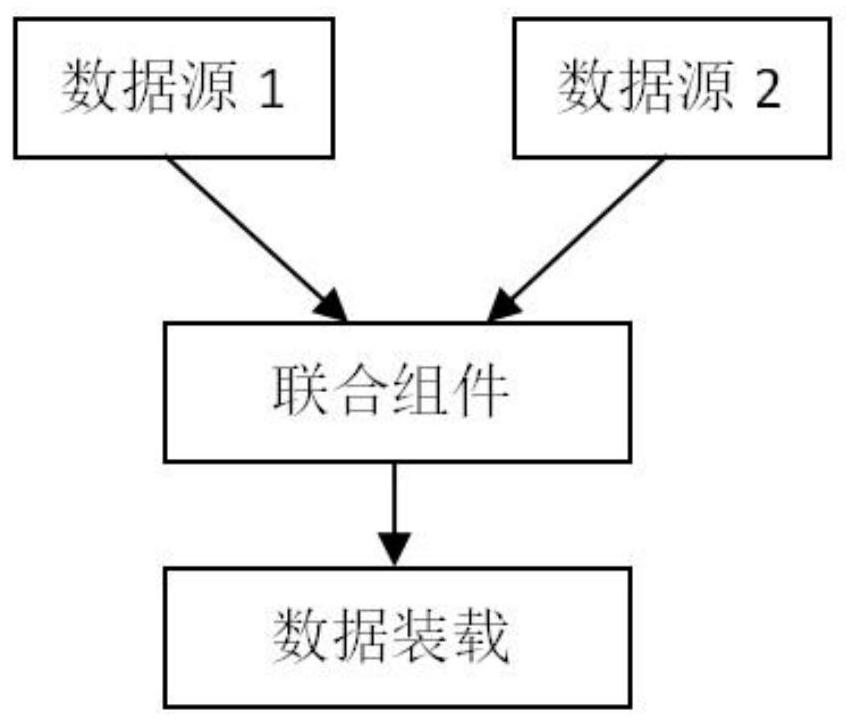
[0097] by Figure 6 and Figure 12 For example, the ETL process includes three reduce nodes: sorting component 1, connecting component, and sorting component 2. Therefore, this complex ETL process can be divided into three MRWorks, which are respectively recorded as MRWork1, MRWork2, and MRWork3. Each MRWork owns The component nodes run in a map reduce. The MRWork data structure is roughly as follows:
[0098]
[0099]
[0100] In the above data structure, ActivityBean is the holder of each component property.
[0101] multiMapSourceActivityBeansMap is a defined map variable, where the key is the data source ActivityBean, and the value is the data source and all component nodes downstr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More