Optimized random forest unbalanced data set processing method
A technology of random forest and random forest model, which is applied in the direction of computer parts, instruments, characters and pattern recognition, etc., can solve the problems of reducing the unbalanced rate of data sets, information loss, and the decline of the accuracy rate of most categories, so as to achieve correct prediction The rate will not drop seriously, the prediction performance will be improved, and the classification accuracy rate will be improved.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment
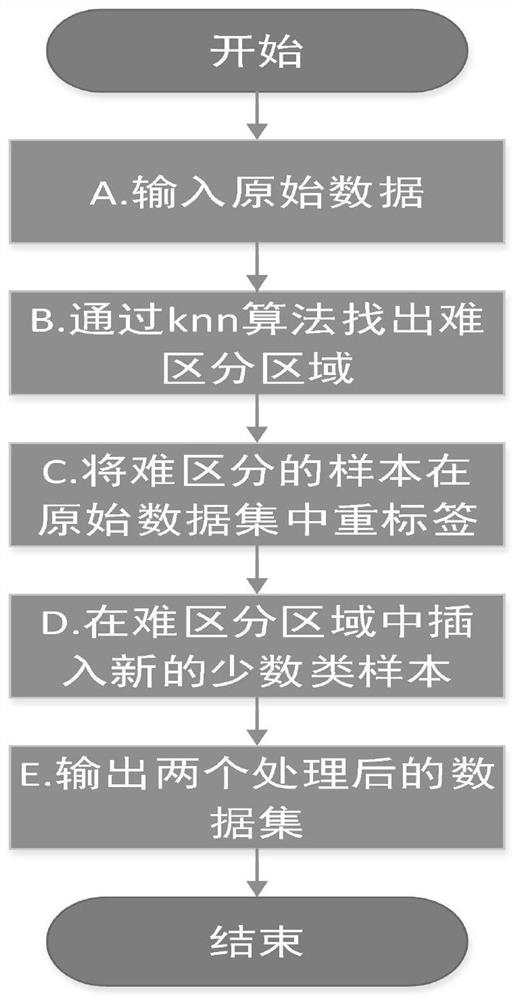
[0059] The present invention is an optimized random forest method for processing unbalanced data sets. The method includes data preprocessing, random forest model construction and classification prediction, wherein the data preprocessing will find the nearest neighbor of the minority class sample K majority class samples form an indistinguishable area. The samples in this area are relabeled in the original data set, and the minority class samples are generated in the indistinguishable area. The original data after relabeling and the newly added samples The difficult-to-distinguish regions are output as different training sets; the construction of the random forest model uses the 2 data sets processed by the data preprocessing part as the training set of the model to obtain two random forest models; the classification prediction will Enter the two random forest models described in two stages for verification, and finally obtain the classification prediction results of the sample...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



