

Intelligent question answering method and device based on enterprise entity
An intelligent question answering and enterprise technology, applied in the field of knowledge question answering, can solve problems such as lack of knowledge and low accuracy of knowledge question answering, and achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
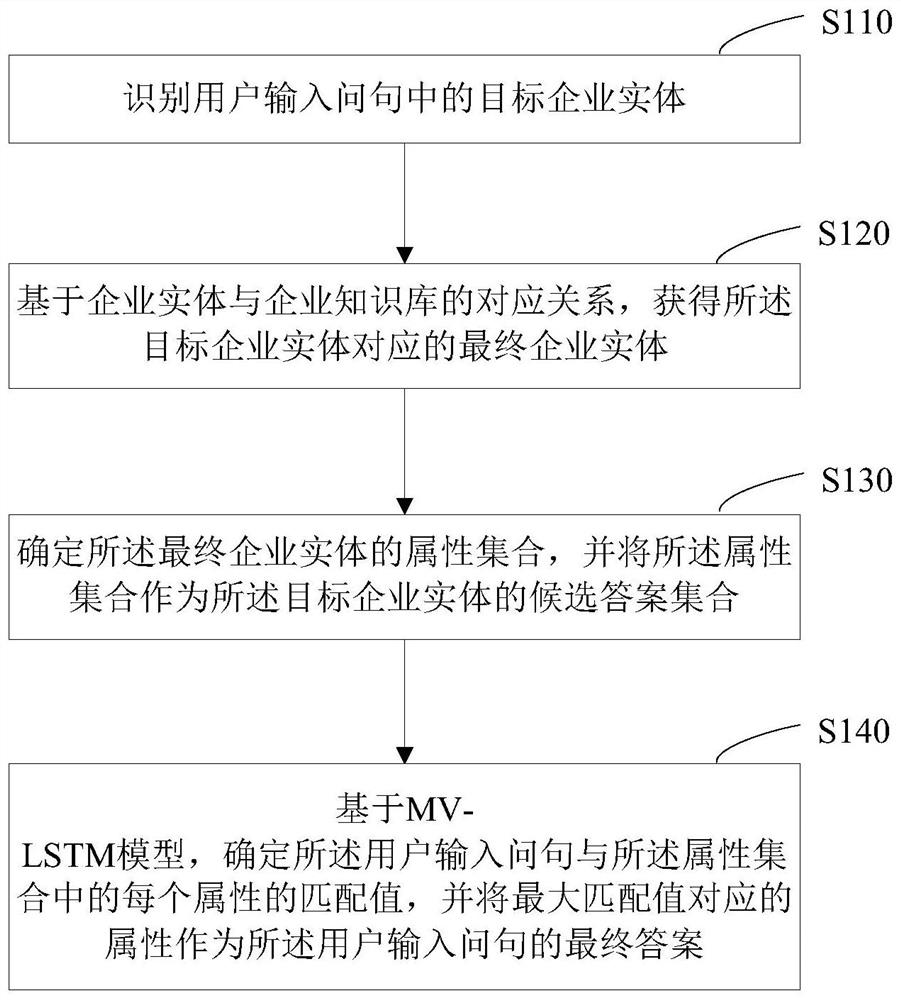
[0083] see figure 1 , figure 1 The first flow chart of an intelligent question answering method based on an enterprise entity provided by an embodiment of the present invention, the method is applied to a server, such as figure 1 As shown, the method includes the following steps:
[0084] S110, identifying the target business entity in the question input by the user;
[0085] This process is to obtain the target enterprise entity in the question input by the user, and use it to link with the enterprise entity in the enterprise knowledge base. The corporate entity in the question may be the full name, abbreviation and brand name of the company. For example, "Bank of China Co., Ltd.", "Baidu" and "Eleme" are the full name, abbreviation and brand name of the company respectively, collectively referred to here as business entity.
[0086] Optionally, in this embodiment, based on the BiLSTM-CRF model, the target enterprise entity in the question input by the user is identified....
Embodiment 2
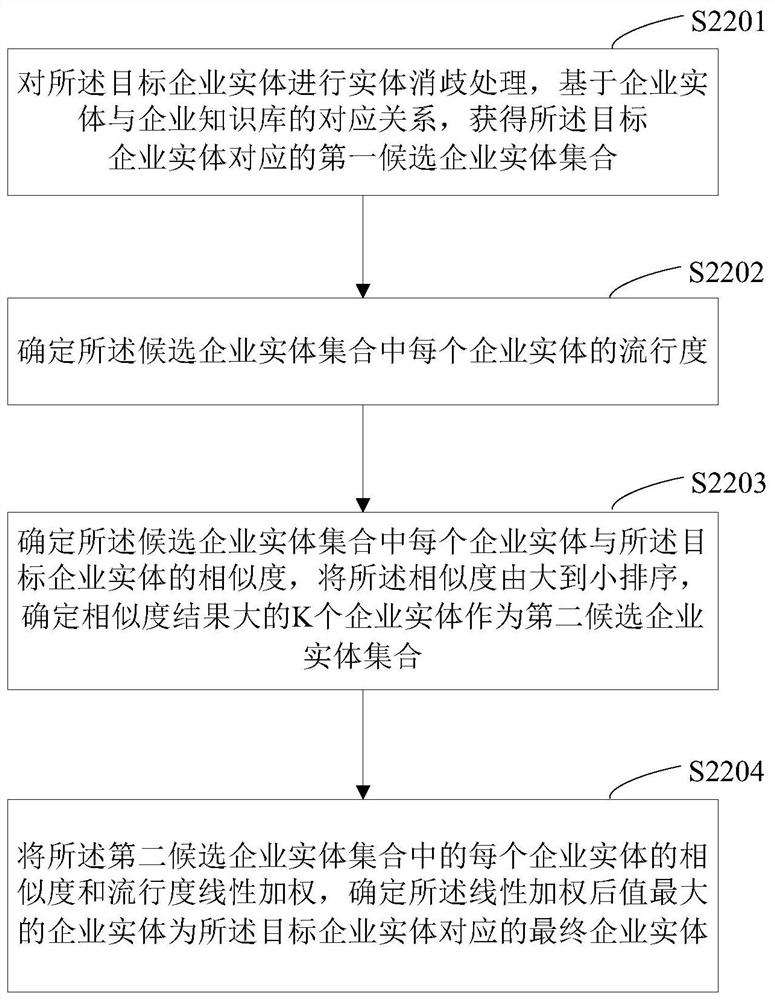
[0117] see figure 2 , figure 2 It is the second flow chart of an enterprise entity-based intelligent question answering method provided by an embodiment of the present invention. The method is applied to a server. On the basis of the method described in Embodiment 1, in this embodiment, an enterprise entity-based The corresponding relationship with the enterprise knowledge base is to obtain the final enterprise entity corresponding to the target enterprise entity, which specifically includes:
[0118] S2201. Perform entity disambiguation processing on the target enterprise entity, and obtain a first candidate enterprise entity set corresponding to the target enterprise entity based on the correspondence between the enterprise entity and the enterprise knowledge base;
[0119] For example, assuming that the target business entity is Baidu, its corresponding first candidate business entity set may be {Baidu Cloud, Baidu Online Network Technology, Baidu Translation, Baidu Musi...
Embodiment 3
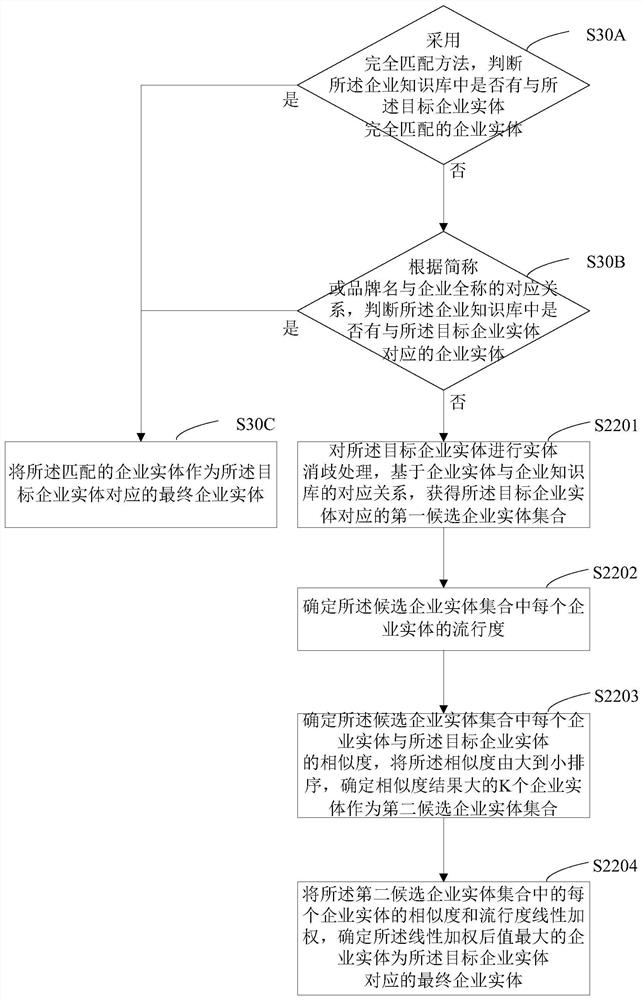
[0130] see image 3 , image 3 It is the third flow chart of an enterprise entity-based intelligent question answering method provided by the embodiment of the present invention. This method is applied to a server. Before disparity processing, described in this embodiment also includes:
[0131] S30A, using the complete matching method, judging whether there is an enterprise entity that completely matches the target enterprise entity in the enterprise knowledge base, if yes, execute S30C, and then use the matched enterprise entity as the target enterprise entity corresponding The final business entity, if not, execute S30B;
[0132] Specifically, firstly, the target enterprise entity is linked with the entity in the enterprise knowledge base, and the exact matching method is specifically adopted. Since the full name of an enterprise company is unique, if the enterprise entity in the corresponding enterprise knowledge base can be retrieved, the target enterprise entity can b...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More