

Deep fake face video positioning method based on space-time fusion
A spatio-temporal fusion and deep technology, applied in the fields of image processing and image recognition, can solve the problems of affecting the generalization ability and functional integrity of the recognition system, reducing the recognition accuracy, ignoring time domain features, etc. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

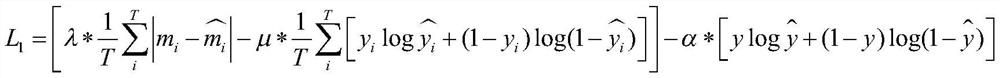
Examples
Embodiment Construction
[0053] The present invention will be described in further detail below in conjunction with the accompanying drawings.
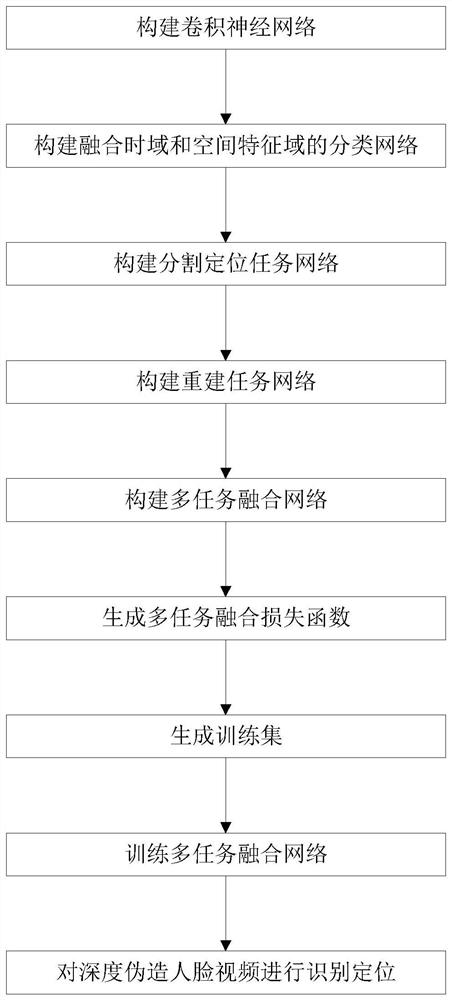
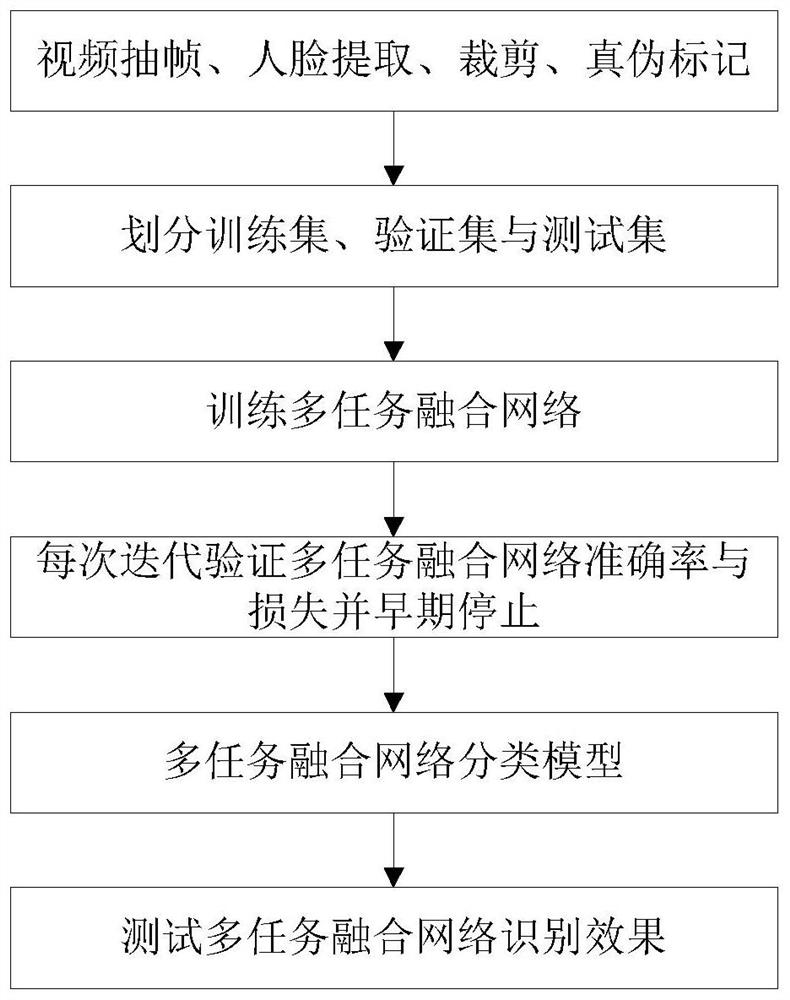
[0054] refer to figure 1 , to further describe in detail the specific steps of the present invention.
[0055] Step 1, construct a convolutional neural network.
[0056] Build a 13-layer convolutional neural network, the structure of which is: the first convolutional layer, the second convolutional layer, the first pooling layer, the third convolutional layer, the fourth convolutional layer, and the second pooling layer , the fifth convolutional layer, the sixth convolutional layer, the seventh convolutional layer, the third pooling layer, the eighth convolutional layer, the ninth convolutional layer, and the tenth convolutional layer.
[0057] Set the size of the convolution kernels of the first to tenth convolution layers to 3×3, and the number of convolution kernels to 64, 64, 128, 128, 256, 256, 256, 512, 512, 512 , the step size is set to 1, the first...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More