

GPDSP assembly transplantation optimization method and system based on countdown buffering
Patent Information
- Authority / Receiving Office
- CN · China
- Current Assignee / Owner
- NAT UNIV OF DEFENSE TECH
- Publication Date
- 2021-07-23
Smart Images

Figure 1 
Figure 2 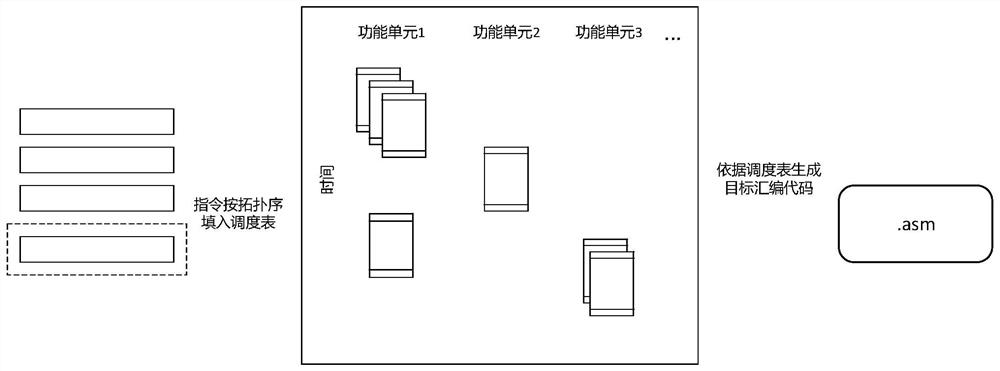
Figure 3
Abstract
Description
technical field
[0001] The invention relates to the field of assembly code optimization and transplantation, in particular to a countdown buffer-based GPDSP assembly transplantation optimization method and system. Background technique
[0002] GPDSP (General Purpose DSP, general-purpose digital signal processor) has made great progress in recent years, and is widely used in wireless communication, scientific computing, image processing and other fields, and it has also gradually penetrated into people's daily life. Become the core of consumer electronics products. At present, most GPDSPs have the characteristics of vector processing, Single Instruction Multiple Data (Single Instruction Multiple Data, SIMD) support and Very Long Instruction Word (VLIW), and support floating-point and fixed-point calculations. The FT-Matrix series independently developed by my country And Texas Instruments DSP is one of the typical representatives.
[0003] In addition to the common C languag...