Image retrieval method based on deep cross-modal hashing based on joint semantic matrix
A semantic matrix, image retrieval technology, applied in the field of deep learning and image retrieval, can solve problems such as unsatisfactory application effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
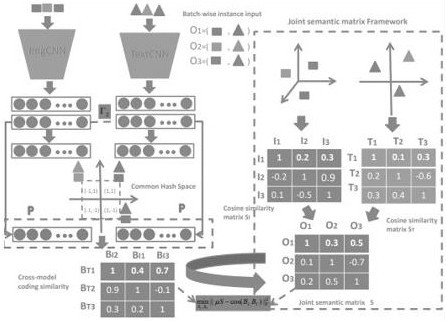
[0051] An image retrieval method based on deep cross-modal hashing (DCSJM) of joint semantic matrix, including the following steps (the specific process is as follows: figure 1 shown):
[0052] S1: Randomly obtain a batch of image-text pair data, and construct a label matrix T;
[0053] S2: Image and text data are sent to the pre-training model VGG19 layer model and Word2Vec model to obtain image and text features (such as figure 1 The upper left part of , specifically the process of obtaining image features through ImgCNN (image network) for image data, and obtaining text features for text through Text CNN (text network);
[0054] S3: Use the features obtained in S2 to construct a joint semantic matrix (such as figure 1 In the dotted box on the right, the image similarity matrix is obtained by calculating the cos distance of the image features. In the figure, I1, I2, and I3 are taken as examples. Similar texts are denoted by T1, T2, T3);
[0055] S4: Use the label matri...
Embodiment 2
[0058] Embodiment 2 (this embodiment is the specific development of embodiment 1)
[0059] An image retrieval method based on Deep Cross-Modal Hashing (DCSJM) of Joint Semantic Matrix, comprising the following steps:
[0060] S1: Use n to indicate that n image-text pair instances were used in the experiment, denoted as ,in represents the i-th instance in the image instance Indicates the i-th instance in the text instance. per image-text pair corresponding to a class vector , where c represents the number of categories, if the i-th instance is in the j-th category, then ,otherwise . Construct a label matrix T for each batch of data.
[0061] S2: The image and text data are respectively sent to the pre-training model VGG19 layer model and the Word2Vec model to obtain image and text features. First, some definitions for constructing the joint semantic matrix are introduced: with Represents the batch size; the specific description is as follows, using represent...
Embodiment 3
[0087] Embodiment 3 (this embodiment is verified by specific experimental data)
[0088] For the specific process of this embodiment, refer to Embodiment 2.
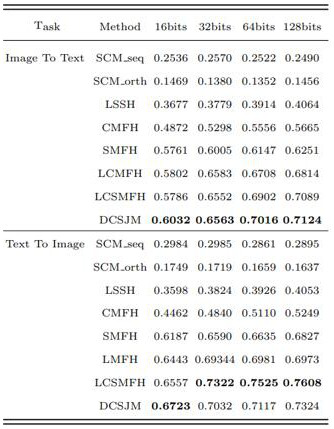
[0089] Experiments are performed on the widely used dataset Pascal Sentence. This dataset is a subset of Pascal VOC and contains 1000 pairs of image and text descriptions from 20 categories. In the experiment, 19-layer VGGNet is used to learn image data representation, and the 4096-dimensional feature learned by fc7 layer is used as the image representation vector. For text data, a sentence CNN is used to learn a 300-dimensional representation vector for each text.
[0090] Results on the Pascal Sentence dataset:
[0091] Validate the hyperparameters multiple times, and finally set the hyperparameters to = 0.0001, = 0.1, = 0.0001. In the experiment, the hyperparameters in other loss functions will be adjusted according to the actual situation.
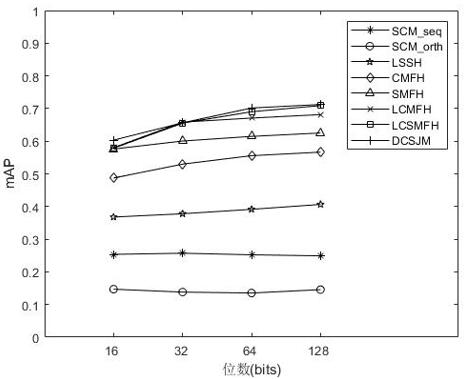
[0092] figure 2 Shows the mAP values of different digits in ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com